5.5 KiB
Using TensorBoard to Observe Training
The ML-Agents Toolkit saves statistics during learning session that you can view with a TensorFlow utility named, TensorBoard.
The mlagents-learn command saves training statistics to a folder named
results, organized by the run-id value you assign to a training session.
In order to observe the training process, either during training or afterward, start TensorBoard:
- Open a terminal or console window:
- Navigate to the directory where the ML-Agents Toolkit is installed.
- From the command line run:
tensorboard --logdir results --port 6006 - Open a browser window and navigate to localhost:6006.
Note: The default port TensorBoard uses is 6006. If there is an existing session running on port 6006 a new session can be launched on an open port using the --port option.
Note: If you don't assign a run-id identifier, mlagents-learn uses the
default string, "ppo". You can delete the folders under the results directory
to clear out old statistics.
On the left side of the TensorBoard window, you can select which of the training runs you want to display. You can select multiple run-ids to compare statistics. The TensorBoard window also provides options for how to display and smooth graphs.
The ML-Agents Toolkit training statistics
The ML-Agents training program saves the following statistics:
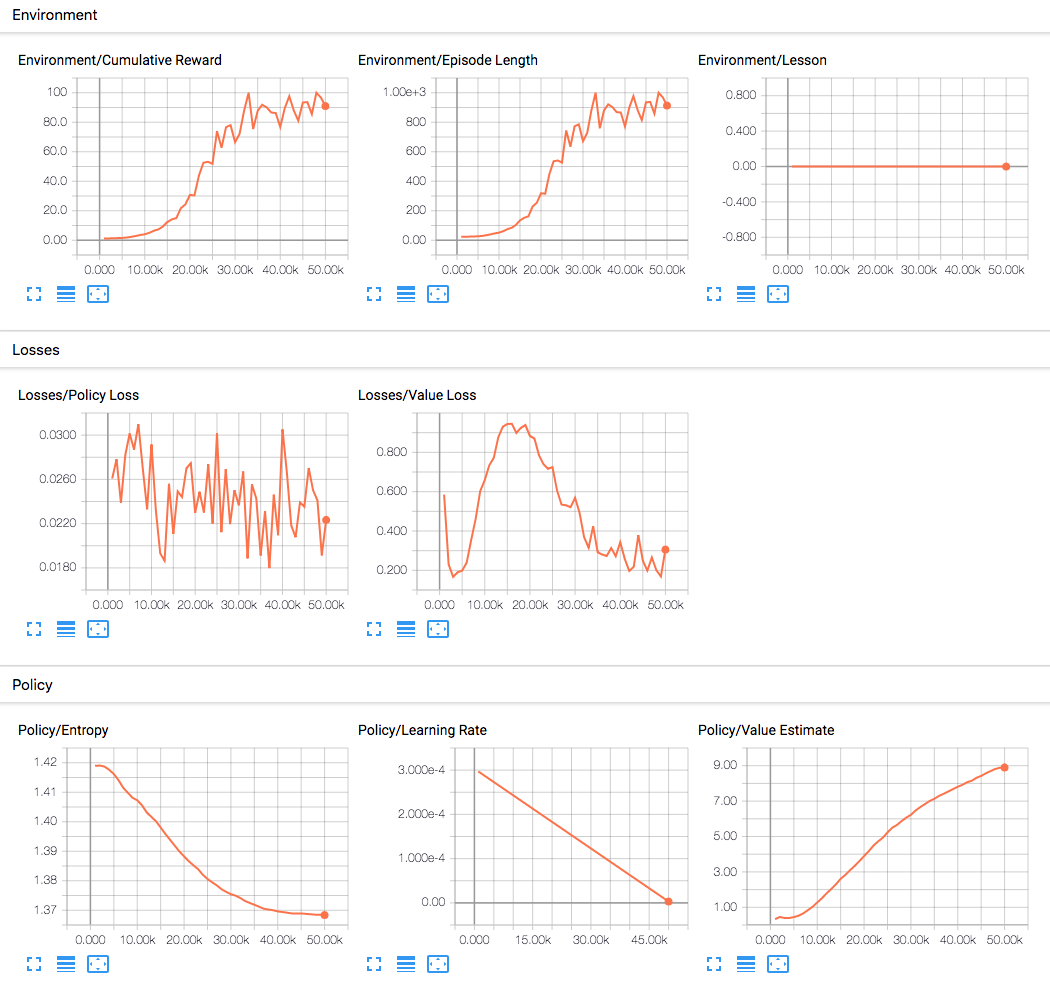
Environment Statistics
-
Environment/Lesson- Plots the progress from lesson to lesson. Only interesting when performing curriculum training. -
Environment/Cumulative Reward- The mean cumulative episode reward over all agents. Should increase during a successful training session. -
Environment/Episode Length- The mean length of each episode in the environment for all agents.
Is Training
Is Training- A boolean indicating if the agent is updating its model.
Policy Statistics
-
Policy/Entropy(PPO; SAC) - How random the decisions of the model are. Should slowly decrease during a successful training process. If it decreases too quickly, thebetahyperparameter should be increased. -
Policy/Learning Rate(PPO; SAC) - How large a step the training algorithm takes as it searches for the optimal policy. Should decrease over time. -
Policy/Entropy Coefficient(SAC) - Determines the relative importance of the entropy term. This value is adjusted automatically so that the agent retains some amount of randomness during training. -
Policy/Extrinsic Reward(PPO; SAC) - This corresponds to the mean cumulative reward received from the environment per-episode. -
Policy/Value Estimate(PPO; SAC) - The mean value estimate for all states visited by the agent. Should increase during a successful training session. -
Policy/Curiosity Reward(PPO/SAC+Curiosity) - This corresponds to the mean cumulative intrinsic reward generated per-episode. -
Policy/Curiosity Value Estimate(PPO/SAC+Curiosity) - The agent's value estimate for the curiosity reward. -
Policy/GAIL Reward(PPO/SAC+GAIL) - This corresponds to the mean cumulative discriminator-based reward generated per-episode. -
Policy/GAIL Value Estimate(PPO/SAC+GAIL) - The agent's value estimate for the GAIL reward. -
Policy/GAIL Policy Estimate(PPO/SAC+GAIL) - The discriminator's estimate for states and actions generated by the policy. -
Policy/GAIL Expert Estimate(PPO/SAC+GAIL) - The discriminator's estimate for states and actions drawn from expert demonstrations.
Learning Loss Functions
-
Losses/Policy Loss(PPO; SAC) - The mean magnitude of policy loss function. Correlates to how much the policy (process for deciding actions) is changing. The magnitude of this should decrease during a successful training session. -
Losses/Value Loss(PPO; SAC) - The mean loss of the value function update. Correlates to how well the model is able to predict the value of each state. This should increase while the agent is learning, and then decrease once the reward stabilizes. -
Losses/Forward Loss(PPO/SAC+Curiosity) - The mean magnitude of the inverse model loss function. Corresponds to how well the model is able to predict the new observation encoding. -
Losses/Inverse Loss(PPO/SAC+Curiosity) - The mean magnitude of the forward model loss function. Corresponds to how well the model is able to predict the action taken between two observations. -
Losses/Pretraining Loss(BC) - The mean magnitude of the behavioral cloning loss. Corresponds to how well the model imitates the demonstration data. -
Losses/GAIL Loss(GAIL) - The mean magnitude of the GAIL discriminator loss. Corresponds to how well the model imitates the demonstration data.
Self-Play
Self-Play/ELO(Self-Play) - ELO measures the relative skill level between two players. In a proper training run, the ELO of the agent should steadily increase.
Exporting Data from TensorBoard
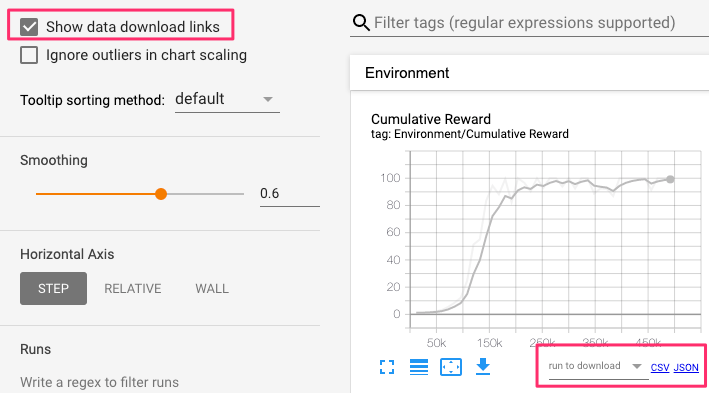
To export timeseries data in CSV or JSON format, check the "Show data download links" in the upper left. This will enable download links below each chart.
Custom Metrics from Unity
To get custom metrics from a C# environment into TensorBoard, you can use the
StatsRecorder:
var statsRecorder = Academy.Instance.StatsRecorder;
statsRecorder.Add("MyMetric", 1.0);