21 KiB
Начало работы
В данной статье мы разберем шаг за шагом один из наших примеров, обучим в нем искусственный интеллект (агента - Agent) и применим полученную модель в Unity сцене (scene). После прочтения статьи, вы сможете обучить агента в любой другой сцене из наших примеров. Если вы не работали с движком Unity, пожалуйста, ознакомьтесь с нашей статьей Background: Unity. Также, если словосочетание “машинное обучение” вам ничего не говорит, прочтите для быстрого ознакомления о нем здесь Background: Machine Learning.

Нашей сценой будет 3D Balance Ball. Агенты в ней - синие кубы-платформы, у каждого на голове по мячу. Все они - копии друг друга. Каждый куб-агент пытается предотвратить падение мячика, у каждого из них есть возможность двигать головой вверх-вниз (кивать), вправо-лево (качать). В данной сцене, - или иначе, среде, куб-платформа - это Агент, который получает награду за каждый момент времени, когда ему удается удержать мяч на голове. Агент также наказывается (отрицательная награда), если мяч падает с его головы. Цель обучения - научить агента удерживать мячик на голове.
Все, начинаем!
Установка
Если вы еще не установили ML-Agents, следуйте этой инструкции по установке(https://github.com/Unity-Technologies/ml-agents/tree/master/docs/localized/RU/docs/Установка.md).
- Далее, откройте в Unity Project, в котором находятся примеры:
- Запустите Unity Hub
- В Projects нажмите на Add вверху окна.
Перейдите в папку с ML-Agents Toolkit, найдите папку
Projectsи нажмите Open. - В окне Project перейдите на
Assets/ML-Agents/Examples/3DBall/Scenesи откройте файл-сцену3DBall.
О среде/cцене Unity
Агент - это автономный actor (официальное название в документации), который взаимодействует со средой, собирая о ней данные. В Unity, среда это сцена (scene), в которой есть один или более объектов - Агентов, а также, конечно, и другие объекты, с которыми взаимодействует агент.
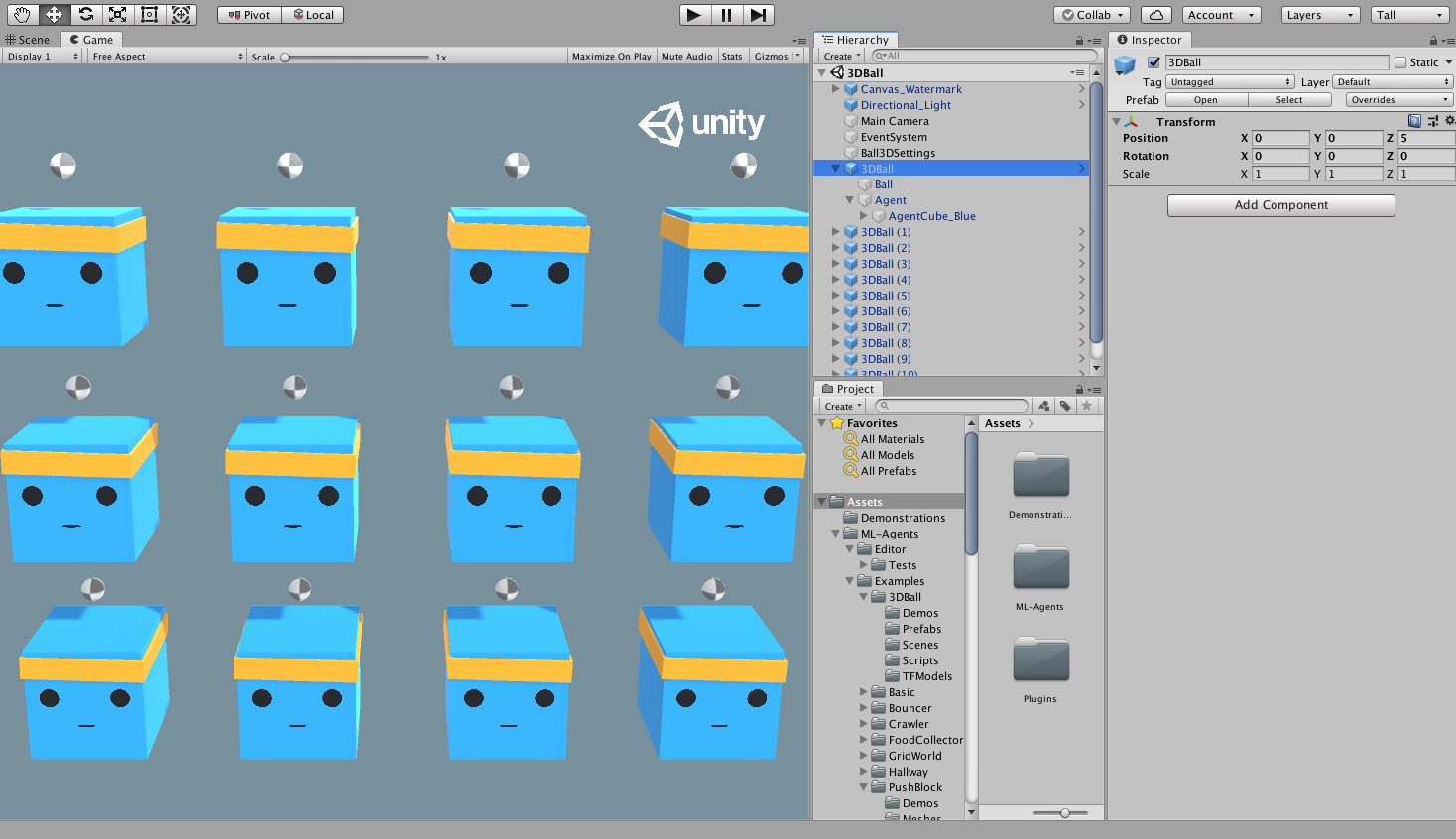
Обратите внимание: В Unity каждый объект сцены - это объект класса GameObject. GameObject это буквально контейнер для всего, что касается объекта: его физики, графики, поведения и пр., называемое компонентами. Чтобы посмотреть все компоненты, составляющие GameObject, выберите GameObject в окне Scene и откройте окно Inspector. Inspector показывает все компоненты GameObject. Первое, что мы можете заметить, открыв сцену 3D Balance Ball, что она состоит не из одного, а нескольких кубов - агентов. Каждый такой агент в сцене это независимый агент, но у них на всех одно Поведение (Behavior). Это сделано для ускорения процесса обучения: все 12 агентов вносят свой вклад одновременно.
Агент
Агент - это actor (действующие лицо), который делает наблюдения (“видит/слушает/пр.” - принимает заданные сигналы) и совершает действия в среде. В 3D Balance Ball компоненты Агента помещены в 12 "Агентов" - GameObjects. Агент как объект обладает парой свойств, которые влияют на его поведение:
- Behavior Parameters (Параметры поведения) — У каждого Агента должно быть Поведение. Поведение определяет решения Агента.
- Max Step (Максимальное количество шагов) — Определяет, сколько шагов допускается сделать в рамках одной симуляции до завершения эпизода, достижение максимального значения также означает завершение. В 3D Balance Ball Агент перезапускается после 5000 шагов. Иными словами: каждый эпизод - это симуляция, в рамках которой куб пытается удержать шарик. Симуляция заканчивается либо по прошествию 5000 шагов, либо после определенного времени.
Параметры поведения: Векторное пространство наблюдений (Vector Observation Space)
Перед тем как принять тот или иной шаг/действие, агент собирает наблюдения о среде,
ее состоянии. Векторное пространство наблюдений это вектор со значениями типа
float (с плавающей точкой, например, 3.14), которые представляют собой информацию о мире,
позволяющими агенту принять решение о том или ином действии.
Параметры поведения в примере 3D Balance Ball использую вектор размерностью 8:
это значит, что в нем хранится 8 элементов наблюдения: x и z компоненты ротации агента, x, y, z
компоненты относительного местонахождения шарика, а также его скорость (состоящую из трех компонентов).
Параметры поведения: Векторное пространство действий (Vector Action Space)
Действия Агента даны в форме массива с типом float. ML-Agents Toolkit классифицирует
действия на два типа: дискретные и непрерывные. Пример 3D Balance Ball использует
непрерывное пространство действий, представляющий собой вектор чисел,
которые могут меняться сколь угодно мало. Поясним: в примере размер
вектора действий - 2: контроль x and z компонент ротации, чтобы
удержать шарик на голове. Так вот, изменение (без учета выделенной памяти)
может быть равным 0,1. Может быть равным и 0.11, а может и на 0.1000001…
и так далее - это и есть свойство непрерывности.
Еще пример для понимания: скажем, ваш рост составляет 180 см.
Если мы его начнем измерять более точной линейкой, окажется, что он
на самом деле 180,01 cм. Если еще более точной линейкой, то 180,012345 см.
И так далее, при точности линейки, стремящейся к бесконечности,
уточнение вашего роста также стремиться к бесконечности.
Запуск заранее обученной (предтренированной) модели
Мы включили в свои примеры заранее обученные модели (файлы с расширением .nn)
и использовали Unity Inference Engine,
чтобы запустить их в Unity. В этом разделе мы воспользуемся одной
из таких моделей для 3D Ball.
-
В окне Project пройдите в папку
Assets/ML-Agents/Examples/3DBall/Prefabs. Раскройте3DBallи кликните на префаб (prefab)Agent. Вы должны будете увидеть префабAgentв окне Inspector.Обратите внимание: Кубы-платформы в сцене
3DBallбыли сделаны используя префаб3DBall. Поэтому при необходимости внести изменения в каждую из платформ, вы можете просто изменить сам префаб вместо этого.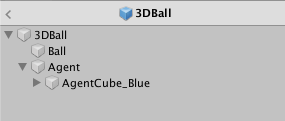
-
В окне Project, перенесите модель (Model) поведения 3DBall, находящуюся в
Assets/ML-Agents/Examples/3DBall/TFModelsв свойствоModelв компонентеBehavior Parameters (Script)в окне Inspector GameObject’a Agent.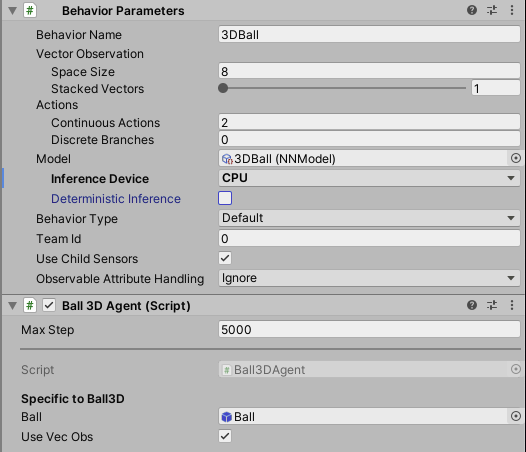
-
Теперь каждый
Агентна каждой платформе3DBallв окне Hierarchy должен содержать модель поведения 3DBall вBehavior Parameters. Обратите внимание : Вы можете изменять разные игровые объекты на сцене, выбрав их разом, используя строку поиска в Hierarchy сцены (Scene Hierarchy). -
В Inference Device для данной модели выберите CPU.
-
Нажмите на кнопку Play в Unity - наши платформы будут удерживать мячик, используя ранее обученную модель.
Обучение новой модели с использованием обучения с подкреплением (Reinforcement Learning)
В любой среде, которую вы сделаете сами, вам нужно будет обучить агентов с нуля, чтобы
у вас сгененировался файл модели (поведения). В данном разделе мы покажаем как использовать алгоритмы
обучения с подкреплением (reinforcement learning), являющиеся частью пакета ML-Agents
Python. Ниже представлена команда mlagents-learn, чтобы управлять как обучением, так и генерацией модели.
Обучение среды
- Откройте командную строку (терминал).
- Выберите папку с клонированным репозиторием.
Обратите внимание: если вы использовали дефолтную установку,
вам должно быть доступно выполнение
mlagents-learnиз любой директории/папки. - Выполните
mlagents-learn config/ppo/3DBall.yaml --run-id=first3DBallRun.config/ppo/3DBall.yaml- путь к файлу с дефолтной конфигурации обучения, который мы предоставили. Папка config/ppo содержит файлы конфигов обучения для всех наших примеров, включая 3DBall.run-id- уникальное имя для данной обучающий сессии.
- Когда отобразится сообщение "Start training by pressing the Play button in the Unity Editor" (“Начните обучение нажатием кнопки “Play” в редакторе Unity”) - нажмите Play в Unity, чтобы начать обучение в Editor.
Если mlagents-learn запущено корректно и начался процесс обучения,
вы должны будете увидеть что-то вроде этого:
INFO:mlagents_envs:
'Ball3DAcademy' started successfully!
Unity Academy name: Ball3DAcademy
INFO:mlagents_envs:Connected new brain:
Unity brain name: 3DBallLearning
Number of Visual Observations (per agent): 0
Vector Observation space size (per agent): 8
Number of stacked Vector Observation: 1
Vector Action space type: continuous
Vector Action space size (per agent): [2]
Vector Action descriptions: ,
INFO:mlagents_envs:Hyperparameters for the PPO Trainer of brain 3DBallLearning:
batch_size: 64
beta: 0.001
buffer_size: 12000
epsilon: 0.2
gamma: 0.995
hidden_units: 128
lambd: 0.99
learning_rate: 0.0003
max_steps: 5.0e4
normalize: True
num_epoch: 3
num_layers: 2
time_horizon: 1000
sequence_length: 64
summary_freq: 1000
use_recurrent: False
memory_size: 256
use_curiosity: False
curiosity_strength: 0.01
curiosity_enc_size: 128
output_path: ./results/first3DBallRun/3DBallLearning
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 1000. Mean Reward: 1.242. Std of Reward: 0.746. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 2000. Mean Reward: 1.319. Std of Reward: 0.693. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 3000. Mean Reward: 1.804. Std of Reward: 1.056. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 4000. Mean Reward: 2.151. Std of Reward: 1.432. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 5000. Mean Reward: 3.175. Std of Reward: 2.250. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 6000. Mean Reward: 4.898. Std of Reward: 4.019. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 7000. Mean Reward: 6.716. Std of Reward: 5.125. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 8000. Mean Reward: 12.124. Std of Reward: 11.929. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 9000. Mean Reward: 18.151. Std of Reward: 16.871. Training.
INFO:mlagents.trainers: first3DBallRun: 3DBallLearning: Step: 10000. Mean Reward: 27.284. Std of Reward: 28.667. Training.
Обратите внимание, что средняя награда (Mean Reward), увеличивается от одной фазы обучения к другой. Это сигнал, что процесс обучения проходит успешно.
Примечание: Вы можете обучать агента, используя вместо Editor’a исполняемые файлы. См. инструкцию Using an Executable.
Наблюдение за тренировочным процессом
Начав обучать модель с помощью mlagents-learn в директории ml-agents появится папка results.
Чтобы более детально посмотреть процесс обучения, вы можете использовать TensorBoard.
Выполните в командной строке следующую команду:
tensorboard --logdir results
В вашем браузере наберите localhost:6006, чтобы посмотреть статистики TensorBoard.
В рамках этого примера самой важной из них является Environment/Cumulative Reward
(среда/суммарная награда за эпизод), которая должно увеличиваться в процессе обучения,
приближаясь к 100 - максимально возможное значение, которого может достигнуть агент.

Внедрение модели в среду Unity
Когда процесс обучения завершен и модель сохранена
(об этом будет специальное уведомление - Saved Model),
вы можете добавить ее в проект Unity и использовать ее в рамках
тех Agents, на базе которых она обучалась (иначе говоря, применить снова к тем же кубам-платформам).
Обратите внимание: Не закрывайте окно Unity, когда появится уведомление Saved Model. Подождите пока это не будет сделать автоматически или нажмитеCtrl+Cв командной строке. Если вы закроете окно вручную,.nnfile с обученной моделью не будет экспортирован в папкуml-agents`.
Если вы прервали обучение через Ctrl+C и хотите его продолжить,
выполните ту же команду, приписав к ней --resume:
mlagents-learn config/ppo/3DBall.yaml --run-id=first3DBallRun --resume
Ваша обученная модель будет находится в каталоге вида results/<run-identifier>/<behavior_name>.nn,
где <behavior_name> это название поведения (Behavior Name) агента, на базе которого и
была обучена модель. Этот файл содержит в себе последнюю сгенерированную версию.
Теперь вы можете применить модель к вашим Агентам, следуя инструкции,
которая идентична той, что была выше:
- Перенесите файл модели в
Project/Assets/ML-Agents/Examples/3DBall/TFModels/. - Откройте Unity Editor (редактор Unity) и выберите 3DBall с цену как описано выше.
- Выберете 3DBall префаб (prefab) объекта Агента.
- Переместите
<behavior_name>.nnфайл из окна Project, которых находится в Editor’e, в Model в Ball3DAgent в окне Inspector. - Нажмите кнопку Play вверху Editor’a.
Следующие шаги
- Для дополнительной информации о ML-Agents Toolkit, см. Обзор ML-Agents Toolkit.
- Создание своих сцен для обучения агентов.
- Обзор более сложных сред обучения, которые есть в качестве примера в ML-Agents - Example Environments
- Информация про различные опции обучения - Training ML-Agents