15 KiB
Getting Started with the 3D Balance Ball Environment
This tutorial walks through the end-to-end process of opening a ML-Agents toolkit example environment in Unity, building the Unity executable, training an Agent in it, and finally embedding the trained model into the Unity environment.
The ML-Agents toolkit includes a number of example environments which you can examine to help understand the different ways in which the ML-Agents toolkit can be used. These environments can also serve as templates for new environments or as ways to test new ML algorithms. After reading this tutorial, you should be able to explore and build the example environments.

This walk-through uses the 3D Balance Ball environment. 3D Balance Ball contains a number of platforms and balls (which are all copies of each other). Each platform tries to keep its ball from falling by rotating either horizontally or vertically. In this environment, a platform is an Agent that receives a reward for every step that it balances the ball. An agent is also penalized with a negative reward for dropping the ball. The goal of the training process is to have the platforms learn to never drop the ball.
Let's get started!
Installation
In order to install and set up the ML-Agents toolkit, the Python dependencies and Unity, see the installation instructions.
Understanding a Unity Environment (3D Balance Ball)
An agent is an autonomous actor that observes and interacts with an environment. In the context of Unity, an environment is a scene containing an Academy and one or more Brain and Agent objects, and, of course, the other entities that an agent interacts with.
Note: In Unity, the base object of everything in a scene is the GameObject. The GameObject is essentially a container for everything else, including behaviors, graphics, physics, etc. To see the components that make up a GameObject, select the GameObject in the Scene window, and open the Inspector window. The Inspector shows every component on a GameObject.
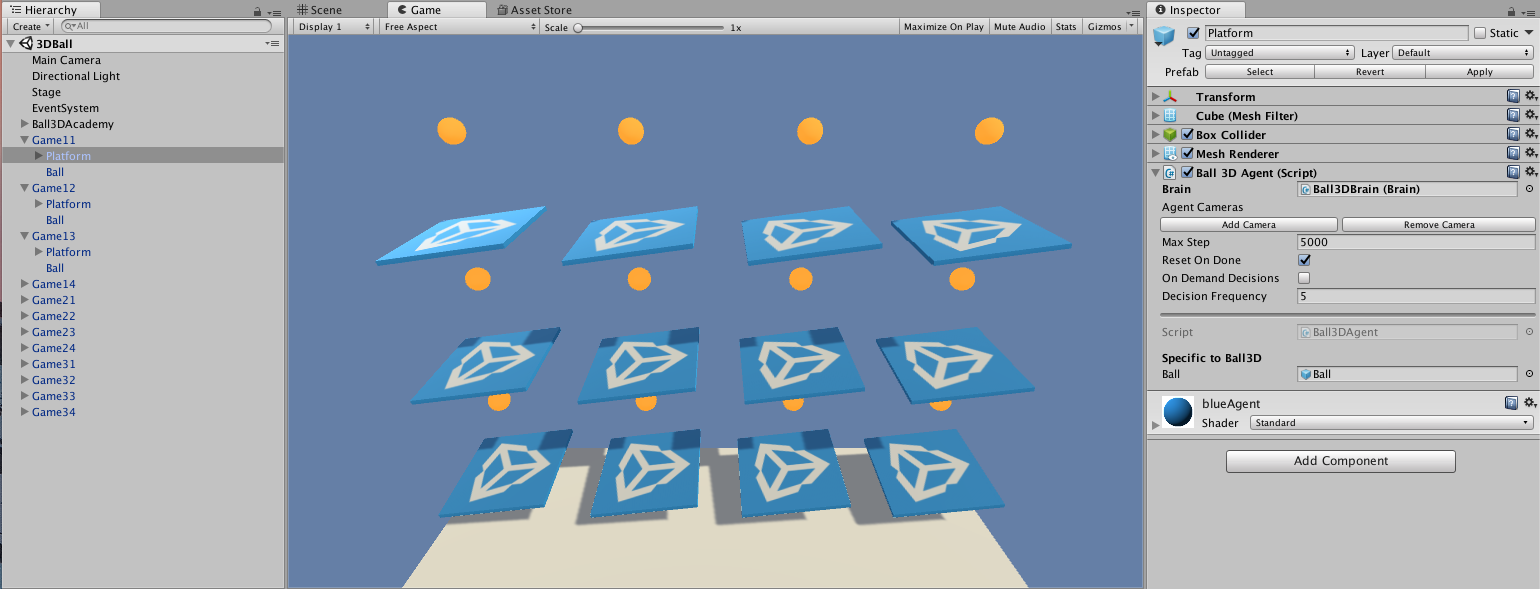
The first thing you may notice after opening the 3D Balance Ball scene is that it contains not one, but several platforms. Each platform in the scene is an independent agent, but they all share the same Brain. 3D Balance Ball does this to speed up training since all twelve agents contribute to training in parallel.
Academy
The Academy object for the scene is placed on the Ball3DAcademy GameObject. When
you look at an Academy component in the inspector, you can see several
properties that control how the environment works.
The Broadcast Hub keeps track of which Brains will send data during training,
If a Brain is added to the hub, his data will be sent to the external training
process. If the Control checkbox is checked, the training process will be able to
control the agents linked to the Brain to train them.
The Training and Inference Configuration properties
set the graphics and timescale properties for the Unity application.
The Academy uses the Training Configuration during training and the
Inference Configuration when not training. (Inference means that the
Agent is using a trained model or heuristics or direct control — in other
words, whenever not training.)
Typically, you set low graphics quality and a high time scale for the Training
configuration and a high graphics quality and the timescale to 1.0 for the
Inference Configuration .
Note: if you want to observe the environment during training, you can adjust the Training Configuration settings to use a larger window and a timescale closer to 1:1. Be sure to set these parameters back when training in earnest; otherwise, training can take a very long time.
Another aspect of an environment to look at is the Academy implementation. Since the base Academy class is abstract, you must always define a subclass. There are three functions you can implement, though they are all optional:
- Academy.InitializeAcademy() — Called once when the environment is launched.
- Academy.AcademyStep() — Called at every simulation step before agent.AgentAction() (and after the Agents collect their observations).
- Academy.AcademyReset() — Called when the Academy starts or restarts the simulation (including the first time).
The 3D Balance Ball environment does not use these functions — each Agent resets itself when needed — but many environments do use these functions to control the environment around the Agents.
Brain
Brains are assets that exist in your project folder. The Ball3DAgents are connected to a Brain, for example : the 3DBallLearning. A Brain doesn't store any information about an Agent, it just routes the Agent's collected observations to the decision making process and returns the chosen action to the Agent. Thus, all Agents can share the same Brain, but act independently. The Brain settings tell you quite a bit about how an Agent works.
You can create Brain objects by selecting Assets -> Create -> ML-Agents -> Brain. There are 3 kinds of Brains :
The Learning Brain is a Brain that uses a Neural Network to take decisions.
When the Brain is checked as Control in the Academy Broadcast Hub, the
external process will be taking decisions for the agents
and generate a neural network when the training is over. You can also use the
Learning Brain with a pre-trained model.
The Heuristic Brain allows you to hand-code the Agent's logic by extending
the Decision class.
Finally, the Player Brain lets you map keyboard commands to actions, which
can be useful when testing your agents and environment. If none of these types
of Brains do what you need, you can implement your own Brain.
In this tutorial, you will use a Learning Brain for training.
Vector Observation Space
Before making a decision, an agent collects its observation about its state in the world. The vector observation is a vector of floating point numbers which contain relevant information for the agent to make decisions.
The Brain instance used in the 3D Balance Ball example uses the Continuous
vector observation space with a State Size of 8. This means that the feature
vector containing the Agent's observations contains eight elements: the x and
z components of the platform's rotation and the x, y, and z components
of the ball's relative position and velocity. (The observation values are
defined in the Agent's CollectObservations() function.)
Vector Action Space
An Agent is given instructions from the Brain in the form of actions.
ML-Agents toolkit classifies actions into two types: the Continuous vector
action space is a vector of numbers that can vary continuously. What each
element of the vector means is defined by the Agent logic (the PPO training
process just learns what values are better given particular state observations
based on the rewards received when it tries different values). For example, an
element might represent a force or torque applied to a Rigidbody in the Agent.
The Discrete action vector space defines its actions as tables. An action
given to the Agent is an array of indices into tables.
The 3D Balance Ball example is programmed to use both types of vector action
space. You can try training with both settings to observe whether there is a
difference. (Set the Vector Action Space Size to 4 when using the discrete
action space and 2 when using continuous.)
Agent
The Agent is the actor that observes and takes actions in the environment. In the 3D Balance Ball environment, the Agent components are placed on the twelve Platform GameObjects. The base Agent object has a few properties that affect its behavior:
- Brain — Every Agent must have a Brain. The Brain determines how an Agent makes decisions. All the Agents in the 3D Balance Ball scene share the same Brain.
- Visual Observations — Defines any Camera objects used by the Agent to observe its environment. 3D Balance Ball does not use camera observations.
- Max Step — Defines how many simulation steps can occur before the Agent decides it is done. In 3D Balance Ball, an Agent restarts after 5000 steps.
- Reset On Done — Defines whether an Agent starts over when it is finished. 3D Balance Ball sets this true so that the Agent restarts after reaching the Max Step count or after dropping the ball.
Perhaps the more interesting aspect of an agents is the Agent subclass implementation. When you create an Agent, you must extend the base Agent class. The Ball3DAgent subclass defines the following methods:
- agent.AgentReset() — Called when the Agent resets, including at the beginning of a session. The Ball3DAgent class uses the reset function to reset the platform and ball. The function randomizes the reset values so that the training generalizes to more than a specific starting position and platform attitude.
- agent.CollectObservations() — Called every simulation step. Responsible for
collecting the Agent's observations of the environment. Since the Brain
instance assigned to the Agent is set to the continuous vector observation
space with a state size of 8, the
CollectObservations()must callAddVectorObssuch that vector size adds up to 8. - agent.AgentAction() — Called every simulation step. Receives the action chosen
by the Brain. The Ball3DAgent example handles both the continuous and the
discrete action space types. There isn't actually much difference between the
two state types in this environment — both vector action spaces result in a
small change in platform rotation at each step. The
AgentAction()function assigns a reward to the Agent; in this example, an Agent receives a small positive reward for each step it keeps the ball on the platform and a larger, negative reward for dropping the ball. An Agent is also marked as done when it drops the ball so that it will reset with a new ball for the next simulation step.
Training the Brain with Reinforcement Learning
Now that we have an environment, we can perform the training.
Training with PPO
In order to train an agent to correctly balance the ball, we will use a Reinforcement Learning algorithm called Proximal Policy Optimization (PPO). This is a method that has been shown to be safe, efficient, and more general purpose than many other RL algorithms, as such we have chosen it as the example algorithm for use with ML-Agents toolkit. For more information on PPO, OpenAI has a recent blog post explaining it.
To train the agents within the Ball Balance environment, we will be using the
Python package. We have provided a convenient script called mlagents-learn
which accepts arguments used to configure both training and inference phases.
We can use run_id to identify the experiment and create a folder where the
model and summary statistics are stored. When using TensorBoard to observe the
training statistics, it helps to set this to a sequential value for each
training run. In other words, "BalanceBall1" for the first run, "BalanceBall2"
or the second, and so on. If you don't, the summaries for every training run are
saved to the same directory and will all be included on the same graph.
To summarize, go to your command line, enter the ml-agents directory and type:
mlagents-learn config/trainer_config.yaml --run-id=<run-identifier> --train
When the message "Start training by pressing the Play button in the Unity Editor" is displayed on the screen, you can press the ▶️ button in Unity to start training in the Editor.
Note: If you're using Anaconda, don't forget to activate the ml-agents environment first.
The --train flag tells the ML-Agents toolkit to run in training mode.
Note: You can train using an executable rather than the Editor. To do so, follow the instructions in Using an Executable.
Observing Training Progress
Once you start training using mlagents-learn in the way described in the
previous section, the ml-agents directory will contain a summaries
directory. In order to observe the training process in more detail, you can use
TensorBoard. From the command line run:
tensorboard --logdir=summaries
Then navigate to localhost:6006 in your browser.
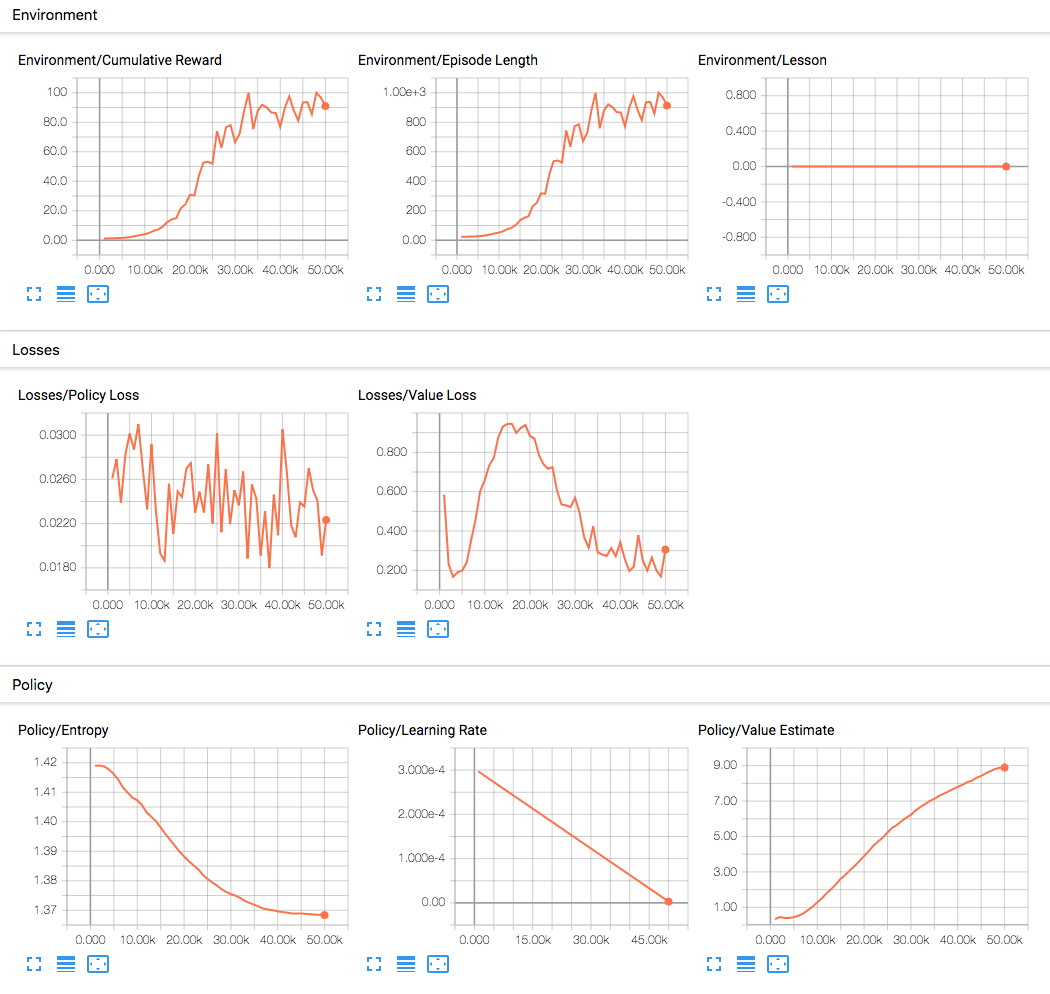
From TensorBoard, you will see the summary statistics:
- Lesson - only interesting when performing curriculum training. This is not used in the 3D Balance Ball environment.
- Cumulative Reward - The mean cumulative episode reward over all agents. Should increase during a successful training session.
- Entropy - How random the decisions of the model are. Should slowly decrease
during a successful training process. If it decreases too quickly, the
betahyperparameter should be increased. - Episode Length - The mean length of each episode in the environment for all agents.
- Learning Rate - How large a step the training algorithm takes as it searches for the optimal policy. Should decrease over time.
- Policy Loss - The mean loss of the policy function update. Correlates to how much the policy (process for deciding actions) is changing. The magnitude of this should decrease during a successful training session.
- Value Estimate - The mean value estimate for all states visited by the agent. Should increase during a successful training session.
- Value Loss - The mean loss of the value function update. Correlates to how well the model is able to predict the value of each state. This should decrease during a successful training session.
Embedding the Trained Brain into the Unity Environment (Experimental)
Once the training process completes, and the training process saves the model
(denoted by the Saved Model message) you can add it to the Unity project and
use it with Agents having a Learning Brain.
Note: Do not just close the Unity Window once the Saved Model message appears.
Either wait for the training process to close the window or press Ctrl+C at the
command-line prompt. If you close the window manually, the .bytes file
containing the trained model is not exported into the ml-agents folder.
Setting up TensorFlowSharp
Because TensorFlowSharp support is still experimental, it is disabled by
default. Please note that the Learning Brain inference can only be used with
TensorFlowSharp.
To set up the TensorFlowSharp Support, follow Setting up ML-Agents Toolkit within Unity section. of the Basic Guide page.
Embedding the trained model into Unity
To embed the trained model into Unity, follow the later part of Training the Brain with Reinforcement Learning section of the Basic Guide page.