您最多选择25个主题
主题必须以中文或者字母或数字开头,可以包含连字符 (-),并且长度不得超过35个字符
2.7 KiB
2.7 KiB
Environment Design Best Practices
General
- It is often helpful to start with the simplest version of the problem, to ensure the agent can learn it. From there increase complexity over time. This can either be done manually, or via Curriculum Learning, where a set of lessons which progressively increase in difficulty are presented to the agent (learn more here).
- When possible, it is often helpful to ensure that you can complete the task by using a Player Brain to control the agent.
- It is often helpful to make many copies of the agent, and attach the brain to be trained to all of these agents. In this way the brain can get more feedback information from all of these agents, which helps it train faster.
Rewards
- The magnitude of any given reward should typically not be greater than 1.0 in order to ensure a more stable learning process.
- Positive rewards are often more helpful to shaping the desired behavior of an agent than negative rewards.
- For locomotion tasks, a small positive reward (+0.1) for forward velocity is typically used.
- If you want the agent to finish a task quickly, it is often helpful to provide a small penalty every step (-0.05) that the agent does not complete the task. In this case completion of the task should also coincide with the end of the episode.
- Overly-large negative rewards can cause undesirable behavior where an agent learns to avoid any behavior which might produce the negative reward, even if it is also behavior which can eventually lead to a positive reward.
Vector Observations
- Vector Observations should include all variables relevant to allowing the agent to take the optimally informed decision.
- Categorical variables such as type of object (Sword, Shield, Bow) should be encoded in one-hot fashion (ie
3->0, 0, 1). - Besides encoding non-numeric values, all inputs should be normalized to be in the range 0 to +1 (or -1 to 1). For example, the
xposition information of an agent where the maximum possible value ismaxValueshould be recorded asAddVectorObs(transform.position.x / maxValue);rather thanAddVectorObs(transform.position.x);. See the equation below for one approach of normalization. - Positional information of relevant GameObjects should be encoded in relative coordinates wherever possible. This is often relative to the agent position.
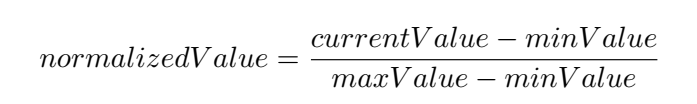
Vector Actions
- When using continuous control, action values should be clipped to an appropriate range.
- Be sure to set the Vector Action's Space Size to the number of used Vector Actions, and not greater, as doing the latter can interfere with the efficency of the training process.