# Summary
The Grid Sensor combines the generality of data extraction from Raycasts with the image processing power of Convolutional Neural Networks. The Grid Sensor can be used to collect data in the general form of a "Width x Height x Channel" matrix which can be used for training Reinforcement Learning agents or for data analysis.
 # Motivation
In MLAgents there are 2 main sensors for observing information that is "physically" around the agent.
**Raycasts**
Raycasts provide the agent the ability to see things along prespecified lines of sight, similar to LIDAR. The kind of data it can extract is open to the developer from things like:
* The type of an object (enemy, npc, etc)
* The health of a unit
* the damage-per-second of a weapon on the ground
This is simple to implement and provides enough information for most simple games. When few are used, they are computationally fast. However, there are multiple limiting factors:
* The rays need to be at the same height as the things the agent should observe
* Objects can remain hidden by line of sight and if the knowledge of those objects is crucial to the success of the agent, then this limitation must be compensated for by the agents networks capacity (i.e., need a bigger brain with memory)
* The order of the raycasts (one raycast being to the left/right of another) is thrown away at the model level and must be learned by the agent which extends training time. Multiple raycasts exacerbates this issue.
* Typically the length of the raycasts is limited because the agent need not know about objects that are at the other side of the level. Combined with few raycasts for computational efficiency, this means that an agent may not observe objects that fall between these rays and the issue becomes worse as the objects reduce in size.
**Camera**
The Camera provides the agent with either a grayscale or an RGB image of the game environment. It goes without saying that there non-linear relationships between nearby pixels in an image. It is this intuition that helps form the basis of Convolutional Neural Networks (CNNs) and established the literature of designing networks that take advantage of these relationships between pixels. Following this established literature of CNNs on image based data, the MLAgent's Camera Sensor provides a means by which the agent can include high dimensional inputs (images) into its observation stream.
However the Camera Sensor has its own drawbacks as well.
* It requires render the scene and thus is computationally slower than alternatives that do not use rendering
* It has yet been shown that the Camera Sensor can be used on a headless machine which means it is not yet possible (if at all) to train an agent on a headless infrastructure.
* If the textures of the important objects in the game are updated, the agent needs to be retrained.
* The RGB of the camera only provides a maximum of 3 channels to the agent.
These limitations provided the motivation towards the development of the Grid Sensor and Grid Observations as described below.
# Contribution
An image can be thought of as a matrix of a predefined width (W) and a height (H) and each pixel can be thought of as simply an array of length 3 (in the case of RGB), `[Red, Green, Blue]` holding the different channel information of the color (channel) intensities at that pixel location. Thus an image is just a 3 dimensional matrix of size WxHx3. A Grid Observation can be thought of as a generalization of this setup where in place of a pixel there is a "cell" which is an array of length N representing different channel intensities at that cell position. From a Convolutional Neural Network point of view, the introduction of multiple channels in an "image" isn't a new concept. One such example is using an RGB-Depth image which is used in several robotics applications. The distinction of Grid Observations is what the data within the channels represents. Instead of limiting the channels to color intensities, the channels within a cell of a Grid Observation generalize to any data that can be represented by a single number (float or int).
Before jumping into the details of the Grid Sensor, an important thing to note is the agent performance and qualitatively different behavior over raycasts. Unity MLAgent's comes with a suite of example environments. One in particular, the [Food Collector](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Examples.md#food-collector), has been the focus of the Grid Sensor development.
The Food Collector environment can be described as:
* Set-up: A multi-agent environment where agents compete to collect food.
* Goal: The agents must learn to collect as many green food spheres as possible while avoiding red spheres.
* Agents: The environment contains 5 agents with same Behavior Parameters.
When applying the Grid Sensor to this environment, in place of the Raycast Vector Sensor or the Camera Sensor, a Mean Reward of 40-50 is observed. This performance is on par with what is seen by agents trained with RayCasts but the side-by-side comparison of trained agents, shows a qualitative difference in behavior. A deeper study and interpretation of the qualitative differences between agents trained with Raycasts and Vector Sensors verses Grid Sensors is left to future studies.
# Motivation
In MLAgents there are 2 main sensors for observing information that is "physically" around the agent.
**Raycasts**
Raycasts provide the agent the ability to see things along prespecified lines of sight, similar to LIDAR. The kind of data it can extract is open to the developer from things like:
* The type of an object (enemy, npc, etc)
* The health of a unit
* the damage-per-second of a weapon on the ground
This is simple to implement and provides enough information for most simple games. When few are used, they are computationally fast. However, there are multiple limiting factors:
* The rays need to be at the same height as the things the agent should observe
* Objects can remain hidden by line of sight and if the knowledge of those objects is crucial to the success of the agent, then this limitation must be compensated for by the agents networks capacity (i.e., need a bigger brain with memory)
* The order of the raycasts (one raycast being to the left/right of another) is thrown away at the model level and must be learned by the agent which extends training time. Multiple raycasts exacerbates this issue.
* Typically the length of the raycasts is limited because the agent need not know about objects that are at the other side of the level. Combined with few raycasts for computational efficiency, this means that an agent may not observe objects that fall between these rays and the issue becomes worse as the objects reduce in size.
**Camera**
The Camera provides the agent with either a grayscale or an RGB image of the game environment. It goes without saying that there non-linear relationships between nearby pixels in an image. It is this intuition that helps form the basis of Convolutional Neural Networks (CNNs) and established the literature of designing networks that take advantage of these relationships between pixels. Following this established literature of CNNs on image based data, the MLAgent's Camera Sensor provides a means by which the agent can include high dimensional inputs (images) into its observation stream.
However the Camera Sensor has its own drawbacks as well.
* It requires render the scene and thus is computationally slower than alternatives that do not use rendering
* It has yet been shown that the Camera Sensor can be used on a headless machine which means it is not yet possible (if at all) to train an agent on a headless infrastructure.
* If the textures of the important objects in the game are updated, the agent needs to be retrained.
* The RGB of the camera only provides a maximum of 3 channels to the agent.
These limitations provided the motivation towards the development of the Grid Sensor and Grid Observations as described below.
# Contribution
An image can be thought of as a matrix of a predefined width (W) and a height (H) and each pixel can be thought of as simply an array of length 3 (in the case of RGB), `[Red, Green, Blue]` holding the different channel information of the color (channel) intensities at that pixel location. Thus an image is just a 3 dimensional matrix of size WxHx3. A Grid Observation can be thought of as a generalization of this setup where in place of a pixel there is a "cell" which is an array of length N representing different channel intensities at that cell position. From a Convolutional Neural Network point of view, the introduction of multiple channels in an "image" isn't a new concept. One such example is using an RGB-Depth image which is used in several robotics applications. The distinction of Grid Observations is what the data within the channels represents. Instead of limiting the channels to color intensities, the channels within a cell of a Grid Observation generalize to any data that can be represented by a single number (float or int).
Before jumping into the details of the Grid Sensor, an important thing to note is the agent performance and qualitatively different behavior over raycasts. Unity MLAgent's comes with a suite of example environments. One in particular, the [Food Collector](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Learning-Environment-Examples.md#food-collector), has been the focus of the Grid Sensor development.
The Food Collector environment can be described as:
* Set-up: A multi-agent environment where agents compete to collect food.
* Goal: The agents must learn to collect as many green food spheres as possible while avoiding red spheres.
* Agents: The environment contains 5 agents with same Behavior Parameters.
When applying the Grid Sensor to this environment, in place of the Raycast Vector Sensor or the Camera Sensor, a Mean Reward of 40-50 is observed. This performance is on par with what is seen by agents trained with RayCasts but the side-by-side comparison of trained agents, shows a qualitative difference in behavior. A deeper study and interpretation of the qualitative differences between agents trained with Raycasts and Vector Sensors verses Grid Sensors is left to future studies.
 ## Overview
There are 3 main phases to the Grid Sensor:
1. **Collection** - data is extracted from observed objects
2. **Encoding** - the extracted data is encoded into a grid observation
3. **Communication** - the grid observation is sent to python or used by a trained model
These phases are described in the following sections.
## Collection
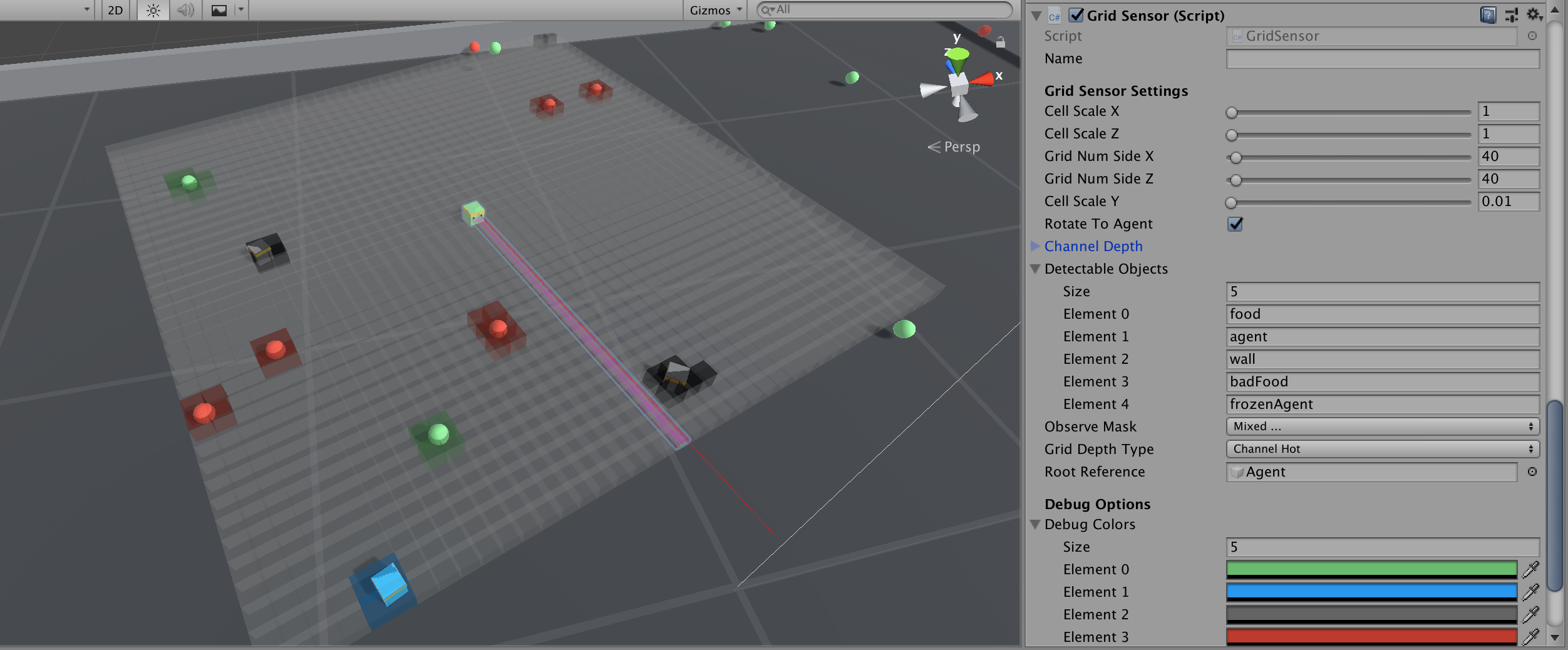
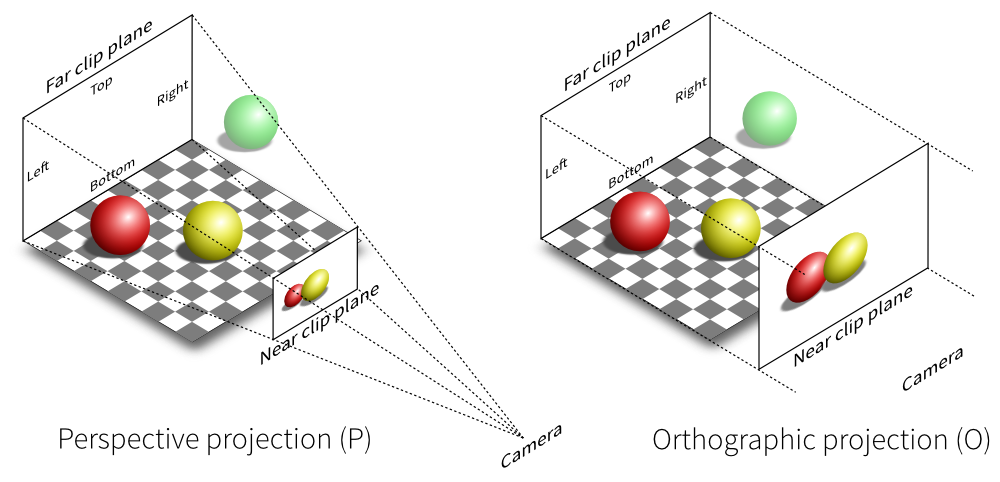
A Grid Sensor is the Grid Observation analog of a Unity Camera but with some notable differences. The sensor is made up of a grid of identical Box Colliders which designate the "cells" of the grid. The Grid Sensor also has a list of "detectable objects" in the form of Unity gameobject tags. When an object that is tagged as a detectable object is present within a cell's Box Collider, that cell is "activated" and a method on the Grid Sensor extracts data from said object and associates that data with the position of the activated cell. Thus the Grid Sensor is always orthographic:
## Overview
There are 3 main phases to the Grid Sensor:
1. **Collection** - data is extracted from observed objects
2. **Encoding** - the extracted data is encoded into a grid observation
3. **Communication** - the grid observation is sent to python or used by a trained model
These phases are described in the following sections.
## Collection
A Grid Sensor is the Grid Observation analog of a Unity Camera but with some notable differences. The sensor is made up of a grid of identical Box Colliders which designate the "cells" of the grid. The Grid Sensor also has a list of "detectable objects" in the form of Unity gameobject tags. When an object that is tagged as a detectable object is present within a cell's Box Collider, that cell is "activated" and a method on the Grid Sensor extracts data from said object and associates that data with the position of the activated cell. Thus the Grid Sensor is always orthographic:
 geofx.com
In practice it has been useful to center the Grid Sensor on the agent in such a way that it is equivalent to having a "top-down" orthographic view of the agent.
Just like the Raycasts mentioned earlier, the Grid Sensor can extract any kind of data from a detected object and just like the Camera, the Grid Sensor maintains the spacial relationship between nearby cells that allows one to take advantage of the CNN literature. Thus the Grid Sensor tries to take the best of both sensors and combines them to something that is more expressive.
### Example of Grid Observations
A Grid Observation is best described using an example and a side by side comparison with the Raycasts and the Camera.
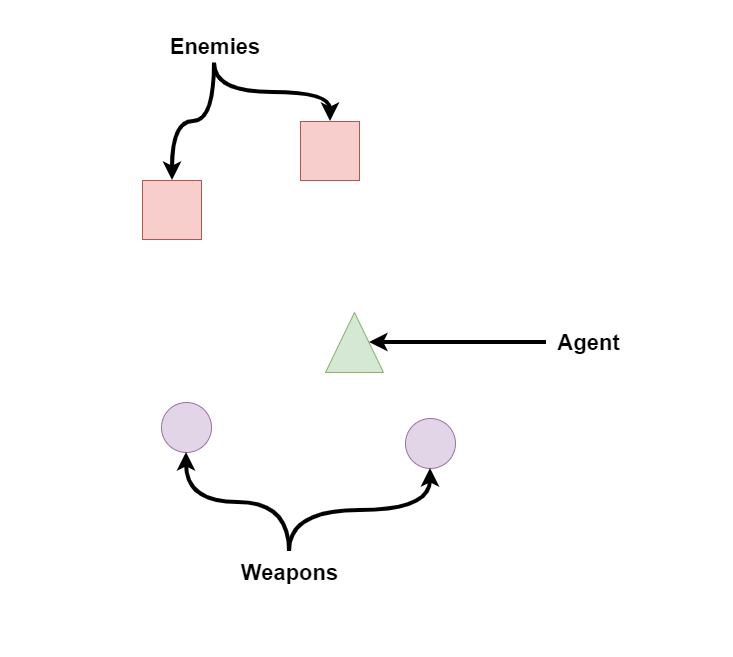
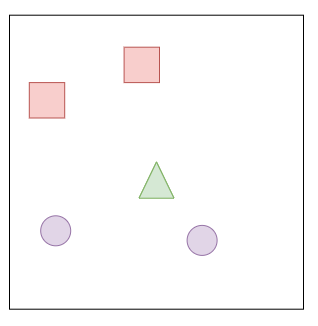
Lets imagine a scenario where an agent is faced with 2 enemies and there are 2 "equipable" weapons somewhat behind the agent. Lets also keep in mind some important properties of the enemies and weapons that would be useful for the agent to know. For simplicity, lets assume enemies represent their health as a percentage (0-100%). Lets also assume that enemies and weapons are the only 2 kind of objects that the agent would see in the entire game.
geofx.com
In practice it has been useful to center the Grid Sensor on the agent in such a way that it is equivalent to having a "top-down" orthographic view of the agent.
Just like the Raycasts mentioned earlier, the Grid Sensor can extract any kind of data from a detected object and just like the Camera, the Grid Sensor maintains the spacial relationship between nearby cells that allows one to take advantage of the CNN literature. Thus the Grid Sensor tries to take the best of both sensors and combines them to something that is more expressive.
### Example of Grid Observations
A Grid Observation is best described using an example and a side by side comparison with the Raycasts and the Camera.
Lets imagine a scenario where an agent is faced with 2 enemies and there are 2 "equipable" weapons somewhat behind the agent. Lets also keep in mind some important properties of the enemies and weapons that would be useful for the agent to know. For simplicity, lets assume enemies represent their health as a percentage (0-100%). Lets also assume that enemies and weapons are the only 2 kind of objects that the agent would see in the entire game.
 #### Raycasts
If a raycast hits an object, not only could we get the distance (normalized by the maximum raycast distance) we would be able to extract its type (enemy vs weapon) and if its an enemy then we could get its health (e.g., .6).
There are many ways in which one could encode this information but one reasonable encoding is this:
```
raycastData = [isWeapon, isEnemy, health, normalizedDistance]
```
For example, if the raycast hit nothing then this would be represented by `[0, 0, 0, 1]`.
If instead the raycast hit an enemy with 60% health that is 50% of the maximum raycast distance, the data would be represented by `[0, 1, .6, .5]`.
The limitations of raycasts which were presented above are easy to visualize in the below image. The agent is unable to see where the weapons are and only sees one of the enemies. Typically in the MLAgents examples, this situation is mitigated by including previous frames of data so that the agent observes changes through time. However, in more complex games, it is not difficult to imagine scenarios where an agent would not be able to observe important information using only Raycasts.
#### Raycasts
If a raycast hits an object, not only could we get the distance (normalized by the maximum raycast distance) we would be able to extract its type (enemy vs weapon) and if its an enemy then we could get its health (e.g., .6).
There are many ways in which one could encode this information but one reasonable encoding is this:
```
raycastData = [isWeapon, isEnemy, health, normalizedDistance]
```
For example, if the raycast hit nothing then this would be represented by `[0, 0, 0, 1]`.
If instead the raycast hit an enemy with 60% health that is 50% of the maximum raycast distance, the data would be represented by `[0, 1, .6, .5]`.
The limitations of raycasts which were presented above are easy to visualize in the below image. The agent is unable to see where the weapons are and only sees one of the enemies. Typically in the MLAgents examples, this situation is mitigated by including previous frames of data so that the agent observes changes through time. However, in more complex games, it is not difficult to imagine scenarios where an agent would not be able to observe important information using only Raycasts.
 #### Camera
Instead, if we used a camera, the agent would be able to see around itself. It would be able to see both enemies and weapons (assuming its field of view was wide enough) and this could be processed by a CNN to encode this information. However, ignoring the obvious limitation that the game would have to be rendered, the agent would not have immediate access to the health value of the enemies. Perhaps textures are added to include "visible damage" to the enemies or there may be health bars above the enemies heads but both of these additions are subject to change, especially in a game that is in development. By using the camera only, it forces the agent to learn a different behavior as it is not able to access what would otherwise be accessible data.
#### Camera
Instead, if we used a camera, the agent would be able to see around itself. It would be able to see both enemies and weapons (assuming its field of view was wide enough) and this could be processed by a CNN to encode this information. However, ignoring the obvious limitation that the game would have to be rendered, the agent would not have immediate access to the health value of the enemies. Perhaps textures are added to include "visible damage" to the enemies or there may be health bars above the enemies heads but both of these additions are subject to change, especially in a game that is in development. By using the camera only, it forces the agent to learn a different behavior as it is not able to access what would otherwise be accessible data.
 #### Grid Sensor
The data extraction method of the Grid Sensor is as open-ended as using the Raycasts to collect data. The `GetObjectData` method on the Grid Sensor can be overridden to collect whatever information is deemed useful for the performance of the agent. By default, only the tag is used.
```csharp
protected virtual float[] GetObjectData(GameObject currentColliderGo, float typeIndex, float normalizedDistance)
```
Following the same data extraction method presented in the section on raycasts, if a Grid Sensor was used instead of Raycasts or a Camera, then not only would the agent be able to extract the health value of the enemies but it would also be able to encode the relative positions of those objects as is done with Camera. Additionally, as the texture of the objects is not used, this data can be collected without rendering the scene.
#### Grid Sensor
The data extraction method of the Grid Sensor is as open-ended as using the Raycasts to collect data. The `GetObjectData` method on the Grid Sensor can be overridden to collect whatever information is deemed useful for the performance of the agent. By default, only the tag is used.
```csharp
protected virtual float[] GetObjectData(GameObject currentColliderGo, float typeIndex, float normalizedDistance)
```
Following the same data extraction method presented in the section on raycasts, if a Grid Sensor was used instead of Raycasts or a Camera, then not only would the agent be able to extract the health value of the enemies but it would also be able to encode the relative positions of those objects as is done with Camera. Additionally, as the texture of the objects is not used, this data can be collected without rendering the scene.
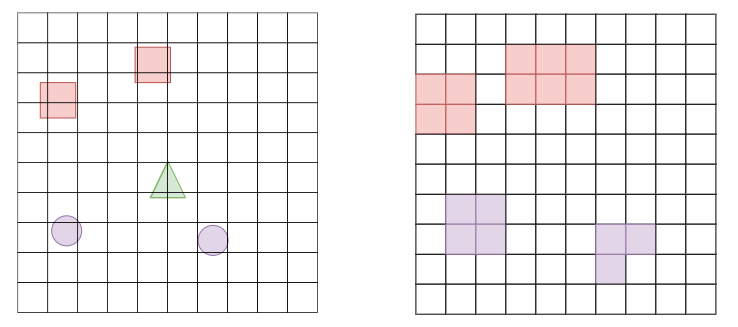 At the end of the Collection phase, each cell with an object inside of it has `GetObjectData` called and the returned values (named `channelValues`) is then processed in the Encoding phase which is described in the next section.
#### CountingGridSensor
The CountingGridSensor builds on the GridSesnor to perform the specific job of counting the number of object types that are based on the different detectable object tags. The encoding and is meant to exploit a key feature of the Grid Sensor. In both the Channel and the Channel Hot DepthTypes, the closest detectable object, in relation to the agent, that lays within a cell is used for encoding the value for that cell. In the CountingGridSensor, the number of each type of object is recorded and then normalized according to a max count, stored in the ChannelDepth.
An example of the CountingGridSensor can be found below.
## Encoding
In order to support different ways of representing the data extracted from an object, multiple "depth types" were implemented. Each has pros and cons and, depending on the use-case of the Grid Sensor, one may be more beneficial than the others.
The data stored that is extracted during the *Collection* phase, and stored in `channelValues`, may come from different sources. For instance, going back the Enemy/Weapon example in the previous section, an enemy's health is continuous whereas the object type (enemy or weapon) is categorical data. This distinction is important as categorical data requires a different encoding mechanism than continuous data.
The Grid Sensor handles this distinction with 4 properties that define how this data is to be encoded:
* DepthType - Enum signifying the encoding mode: Channel, ChannelHot
* ObservationPerCell - the total number of values that are in each cell of the grid observation
* ChannelDepth - int[] describing the range of each data within the `channelValues`
* ChannelOffset - int[] describing the number of encoded values that come before each data within `channelValues`
The ChannelDepth and the DepthType are user defined and gives control to the developer to how they can encode their data. The ChannelDepth and ChannelOffset are both initialized and used in different ways depending on the ChannelDepth and the DepthType.
How categorical and continuous data is treated is different between the different DepthTypes as will be explored in the sections below. The sections will use an on-going example similar to example mentioned earlier where, within a cell, the sensor observes: `an enemy with 60% health`. Thus the cell contains 2 kinds of data: categorical data (object type) and the continuous data (health). Additionally, the order of the observed tags is important as it allows one to encode the tag of the observed object by its index within list of observed tags. Note that in the example, the observed tags is defined as ["weapon", "enemy"].
### Channel Based
The Channel Based Grid Observations is perhaps the simplest in terms of usability and similarity with other machine learning applications. Each grid is of size WxHxC where C is the number of channels. To distinguish between categorical and continuous data, one would use the ChannelDepth array to signify the ranges that the values in the `channelValues` array could take. If one sets ChannelDepth[i] to be 1, it is assumed that the value of `channelValues[i]` is already normalized. Else ChannelDepth[i] represents the total number of possible values that `channelValues[i]` can take.
Using the example described earlier, if one was using Channel Based Grid Observations, they would have a ChannelDepth = {2, 1} to describe that there are two possible values for the first channel and the 1 represents that the second channel is already normalized.
As the "enemy" is in the second position of the observed tags, its value can be normalized by:
```
num = detectableObjects.IndexOfTag("enemy")/ChannelDepth[0] = 2/2 = 1;
```
By using this formula, if there wasn't an object within the cell then the value would be 0.
As the ChannelDepth for the second channel is defined as 1, the collected health value (60% = 0.6) can be encoded directly. Thus the encoded data at this cell is:
`[1, .6]`
At the end of the Encoding phase, the resulting Grid Observation would be a WxHx2 matrix.
### Channel Hot
The Channel Hot DepthType generalizes the classic OneHot encoding to differentiate combinations of different data. Rather than normalizing the data like in the Channel Based section, each element of `channelValues` is represented by an encoding based on the ChannelDepth. If ChannelDepth[i] = 1, then this represents that `channelValues[i]` is already normalized (between 0-1) and will be used directly within the encoding. However if ChannelDepth[i] is an integer greater than 1, then the value in `channelValues[i]` will be converted into a OneHot encoding based on the following:
```
float[] arr = new float[ChannelDepth[i] + 1];
int index = (int) channelValues[i] + 1;
arr[index] = 1;
return arr;
```
The `+ 1` allows the first index of `arr` to be reserved for encoding "empty".
The encoding of each channel is then concatenated together. Clearly using this setup allows the developer to be able to encode values using the classic OneHot encoding. Below are some different variations of the ChannelDepth which create different encodings of the example:
##### ChannelDepth = {3, 1}
The first element, 3, signifies that there are 3 possibilities for the first channel and as the "enemy" is 2nd in the detected objects list, the "enemy" in the example is encoded as `[0, 0, 1]` where the first index represents "no object". The second element, 1, signifies that the health is already normalized and, following the table, is used directly. The resulting encoding is thus:
```
[0, 0, 1, 0.6]
```
##### ChannelDepth = {3, 5}
Like in the previous example, the "enemy" in the example is encoded as `[0, 0, 1]`. For the "health" however, the 5 signifies that the health should be represented by a OneHot encoding of 5 possible values, and in this case that encoding is `round(.6*5) = round(3) = 3 => [0, 0, 0, 1, 0]`.
This encoding would then be concatenated together with the "enemy" encoding resulting in:
```
enemy encoding => [0, 0, 1]
health encoding => [0, 0, 0, 1, 0]
final encoding => [0, 0, 1, 0, 0, 0, 1, 0]
```
The table below describes how other values of health would be mapped to OneHot encoding representations:
| Range | OneHot Encoding |
|------------------|-----------------|
| health = 0 | [1, 0, 0, 0, 0] |
| 0 < health < .3 | [0, 1, 0, 0, 0] |
| .3 < health < .5 | [0, 0, 1, 0, 0] |
| .5 < health < .7 | [0, 0, 0, 1, 0] |
| .7 < health <= 1 | [0, 0, 0, 0, 1] |
##### ChannelDepth = {1, 1}
This setting of ChannelDepth would throw an error as there is not enough information to encode the categorical data of the object type.
### CountingGridSensor
As introduced above, the CountingGridSensor inherits from the GridSensor for the sole purpose of counting the different objects that lay within a cell. In order to normalize the counts so that the grid can be properly encoded as PNG, the ChannelDepth is used to represent the "maximum count" of each type. For the working example, if the ChannelDepth is set as {50, 10}, which represents that the maximum count for objects with the "weapon" and "enemy" tag is 50 and 10, respectively, then the resulting data would be:
```
encoding = [0 weapons/ 50 weapons, 1 enemy / 10 enemies] = [0, .1]
```
## Communication
At the end of the Encoding phase, all of the data for a Grid Observation is placed into a float[] referred to as the perception buffer. Now the data is ready to be sent to either the python side for training or to be used by a trained model within Unity. This is where the Grid Sensor takes advantage of 2D textures and the PNG encoding schema to reduce the number of bytes that are being sent.
The 2D texture is a Unity class that encodes the colors of an image. It is used for many ways through out Unity but it has 2 specific methods that the Grid Sensor takes advantage of:
`SetPixels` takes a 2D array of Colors and assigns the color values to the texture.
`EncodeToPNG` returns a byte[] containing the PNG encoding of the colors of the texture.
Together these 2 functions allow one to "push" a WxHx3 normalized array to a PNG byte[]. And indeed, this is how the Camera Sensor in Unity MLAgents sends its data to python. However, the grid sensor can have N channels so there needs to be a more generic way to send the data.
The core idea behind how a Grid Observation is encoded is the following:
1. split the channels of a Grid Observation into groups of 3
2. encode each of these groups as a PNG byte[]
3. concatenate all byte[] and send the combined array to python
4. reconstruct the Grid Observation by splitting up the array and decoding the sections
Once the bytes are sent to python, they are then decoded and used as a tensor of the correct shape within the mlagents python codebase.
At the end of the Collection phase, each cell with an object inside of it has `GetObjectData` called and the returned values (named `channelValues`) is then processed in the Encoding phase which is described in the next section.
#### CountingGridSensor
The CountingGridSensor builds on the GridSesnor to perform the specific job of counting the number of object types that are based on the different detectable object tags. The encoding and is meant to exploit a key feature of the Grid Sensor. In both the Channel and the Channel Hot DepthTypes, the closest detectable object, in relation to the agent, that lays within a cell is used for encoding the value for that cell. In the CountingGridSensor, the number of each type of object is recorded and then normalized according to a max count, stored in the ChannelDepth.
An example of the CountingGridSensor can be found below.
## Encoding
In order to support different ways of representing the data extracted from an object, multiple "depth types" were implemented. Each has pros and cons and, depending on the use-case of the Grid Sensor, one may be more beneficial than the others.
The data stored that is extracted during the *Collection* phase, and stored in `channelValues`, may come from different sources. For instance, going back the Enemy/Weapon example in the previous section, an enemy's health is continuous whereas the object type (enemy or weapon) is categorical data. This distinction is important as categorical data requires a different encoding mechanism than continuous data.
The Grid Sensor handles this distinction with 4 properties that define how this data is to be encoded:
* DepthType - Enum signifying the encoding mode: Channel, ChannelHot
* ObservationPerCell - the total number of values that are in each cell of the grid observation
* ChannelDepth - int[] describing the range of each data within the `channelValues`
* ChannelOffset - int[] describing the number of encoded values that come before each data within `channelValues`
The ChannelDepth and the DepthType are user defined and gives control to the developer to how they can encode their data. The ChannelDepth and ChannelOffset are both initialized and used in different ways depending on the ChannelDepth and the DepthType.
How categorical and continuous data is treated is different between the different DepthTypes as will be explored in the sections below. The sections will use an on-going example similar to example mentioned earlier where, within a cell, the sensor observes: `an enemy with 60% health`. Thus the cell contains 2 kinds of data: categorical data (object type) and the continuous data (health). Additionally, the order of the observed tags is important as it allows one to encode the tag of the observed object by its index within list of observed tags. Note that in the example, the observed tags is defined as ["weapon", "enemy"].
### Channel Based
The Channel Based Grid Observations is perhaps the simplest in terms of usability and similarity with other machine learning applications. Each grid is of size WxHxC where C is the number of channels. To distinguish between categorical and continuous data, one would use the ChannelDepth array to signify the ranges that the values in the `channelValues` array could take. If one sets ChannelDepth[i] to be 1, it is assumed that the value of `channelValues[i]` is already normalized. Else ChannelDepth[i] represents the total number of possible values that `channelValues[i]` can take.
Using the example described earlier, if one was using Channel Based Grid Observations, they would have a ChannelDepth = {2, 1} to describe that there are two possible values for the first channel and the 1 represents that the second channel is already normalized.
As the "enemy" is in the second position of the observed tags, its value can be normalized by:
```
num = detectableObjects.IndexOfTag("enemy")/ChannelDepth[0] = 2/2 = 1;
```
By using this formula, if there wasn't an object within the cell then the value would be 0.
As the ChannelDepth for the second channel is defined as 1, the collected health value (60% = 0.6) can be encoded directly. Thus the encoded data at this cell is:
`[1, .6]`
At the end of the Encoding phase, the resulting Grid Observation would be a WxHx2 matrix.
### Channel Hot
The Channel Hot DepthType generalizes the classic OneHot encoding to differentiate combinations of different data. Rather than normalizing the data like in the Channel Based section, each element of `channelValues` is represented by an encoding based on the ChannelDepth. If ChannelDepth[i] = 1, then this represents that `channelValues[i]` is already normalized (between 0-1) and will be used directly within the encoding. However if ChannelDepth[i] is an integer greater than 1, then the value in `channelValues[i]` will be converted into a OneHot encoding based on the following:
```
float[] arr = new float[ChannelDepth[i] + 1];
int index = (int) channelValues[i] + 1;
arr[index] = 1;
return arr;
```
The `+ 1` allows the first index of `arr` to be reserved for encoding "empty".
The encoding of each channel is then concatenated together. Clearly using this setup allows the developer to be able to encode values using the classic OneHot encoding. Below are some different variations of the ChannelDepth which create different encodings of the example:
##### ChannelDepth = {3, 1}
The first element, 3, signifies that there are 3 possibilities for the first channel and as the "enemy" is 2nd in the detected objects list, the "enemy" in the example is encoded as `[0, 0, 1]` where the first index represents "no object". The second element, 1, signifies that the health is already normalized and, following the table, is used directly. The resulting encoding is thus:
```
[0, 0, 1, 0.6]
```
##### ChannelDepth = {3, 5}
Like in the previous example, the "enemy" in the example is encoded as `[0, 0, 1]`. For the "health" however, the 5 signifies that the health should be represented by a OneHot encoding of 5 possible values, and in this case that encoding is `round(.6*5) = round(3) = 3 => [0, 0, 0, 1, 0]`.
This encoding would then be concatenated together with the "enemy" encoding resulting in:
```
enemy encoding => [0, 0, 1]
health encoding => [0, 0, 0, 1, 0]
final encoding => [0, 0, 1, 0, 0, 0, 1, 0]
```
The table below describes how other values of health would be mapped to OneHot encoding representations:
| Range | OneHot Encoding |
|------------------|-----------------|
| health = 0 | [1, 0, 0, 0, 0] |
| 0 < health < .3 | [0, 1, 0, 0, 0] |
| .3 < health < .5 | [0, 0, 1, 0, 0] |
| .5 < health < .7 | [0, 0, 0, 1, 0] |
| .7 < health <= 1 | [0, 0, 0, 0, 1] |
##### ChannelDepth = {1, 1}
This setting of ChannelDepth would throw an error as there is not enough information to encode the categorical data of the object type.
### CountingGridSensor
As introduced above, the CountingGridSensor inherits from the GridSensor for the sole purpose of counting the different objects that lay within a cell. In order to normalize the counts so that the grid can be properly encoded as PNG, the ChannelDepth is used to represent the "maximum count" of each type. For the working example, if the ChannelDepth is set as {50, 10}, which represents that the maximum count for objects with the "weapon" and "enemy" tag is 50 and 10, respectively, then the resulting data would be:
```
encoding = [0 weapons/ 50 weapons, 1 enemy / 10 enemies] = [0, .1]
```
## Communication
At the end of the Encoding phase, all of the data for a Grid Observation is placed into a float[] referred to as the perception buffer. Now the data is ready to be sent to either the python side for training or to be used by a trained model within Unity. This is where the Grid Sensor takes advantage of 2D textures and the PNG encoding schema to reduce the number of bytes that are being sent.
The 2D texture is a Unity class that encodes the colors of an image. It is used for many ways through out Unity but it has 2 specific methods that the Grid Sensor takes advantage of:
`SetPixels` takes a 2D array of Colors and assigns the color values to the texture.
`EncodeToPNG` returns a byte[] containing the PNG encoding of the colors of the texture.
Together these 2 functions allow one to "push" a WxHx3 normalized array to a PNG byte[]. And indeed, this is how the Camera Sensor in Unity MLAgents sends its data to python. However, the grid sensor can have N channels so there needs to be a more generic way to send the data.
The core idea behind how a Grid Observation is encoded is the following:
1. split the channels of a Grid Observation into groups of 3
2. encode each of these groups as a PNG byte[]
3. concatenate all byte[] and send the combined array to python
4. reconstruct the Grid Observation by splitting up the array and decoding the sections
Once the bytes are sent to python, they are then decoded and used as a tensor of the correct shape within the mlagents python codebase.