比较提交
合并到: unity-tech-cn:main
unity-tech-cn:/main
unity-tech-cn:/develop-generalizationTraining-TrainerController
unity-tech-cn:/tag-0.2.0
unity-tech-cn:/tag-0.2.1
unity-tech-cn:/tag-0.2.1a
unity-tech-cn:/tag-0.2.1c
unity-tech-cn:/tag-0.2.1d
unity-tech-cn:/hotfix-v0.9.2a
unity-tech-cn:/develop-gpu-test
unity-tech-cn:/0.10.1
unity-tech-cn:/develop-pyinstaller
unity-tech-cn:/develop-horovod
unity-tech-cn:/PhysXArticulations20201
unity-tech-cn:/importdocfix
unity-tech-cn:/develop-resizetexture
unity-tech-cn:/hh-develop-walljump_bugfixes
unity-tech-cn:/develop-walljump-fix-sac
unity-tech-cn:/hh-develop-walljump_rnd
unity-tech-cn:/tag-0.11.0.dev0
unity-tech-cn:/develop-pytorch
unity-tech-cn:/tag-0.11.0.dev2
unity-tech-cn:/develop-newnormalization
unity-tech-cn:/tag-0.11.0.dev3
unity-tech-cn:/develop
unity-tech-cn:/release-0.12.0
unity-tech-cn:/tag-0.12.0-dev
unity-tech-cn:/tag-0.12.0.dev0
unity-tech-cn:/tag-0.12.1
unity-tech-cn:/2D-explorations
unity-tech-cn:/asymm-envs
unity-tech-cn:/tag-0.12.1.dev0
unity-tech-cn:/2D-exploration-raycast
unity-tech-cn:/tag-0.12.1.dev1
unity-tech-cn:/release-0.13.0
unity-tech-cn:/release-0.13.1
unity-tech-cn:/plugin-proof-of-concept
unity-tech-cn:/release-0.14.0
unity-tech-cn:/hotfix-bump-version-master
unity-tech-cn:/soccer-fives
unity-tech-cn:/release-0.14.1
unity-tech-cn:/bug-failed-api-check
unity-tech-cn:/test-recurrent-gail
unity-tech-cn:/hh-add-icons
unity-tech-cn:/release-0.15.0
unity-tech-cn:/release-0.15.1
unity-tech-cn:/hh-develop-all-posed-characters
unity-tech-cn:/internal-policy-ghost
unity-tech-cn:/distributed-training
unity-tech-cn:/hh-develop-improve_tennis
unity-tech-cn:/test-tf-ver
unity-tech-cn:/release_1_branch
unity-tech-cn:/tennis-time-horizon
unity-tech-cn:/whitepaper-experiments
unity-tech-cn:/r2v-yamato-linux
unity-tech-cn:/docs-update
unity-tech-cn:/release_2_branch
unity-tech-cn:/exp-mede
unity-tech-cn:/sensitivity
unity-tech-cn:/release_2_verified_load_fix
unity-tech-cn:/test-sampler
unity-tech-cn:/release_2_verified
unity-tech-cn:/hh-develop-ragdoll-testing
unity-tech-cn:/origin-develop-taggedobservations
unity-tech-cn:/MLA-1734-demo-provider
unity-tech-cn:/sampler-refactor-copy
unity-tech-cn:/PhysXArticulations20201Package
unity-tech-cn:/tag-com.unity.ml-agents_1.0.8
unity-tech-cn:/release_3_branch
unity-tech-cn:/github-actions
unity-tech-cn:/release_3_distributed
unity-tech-cn:/fix-batch-tennis
unity-tech-cn:/distributed-ppo-sac
unity-tech-cn:/gridworld-custom-obs
unity-tech-cn:/hw20-segmentation
unity-tech-cn:/hh-develop-gamedev-demo
unity-tech-cn:/active-variablespeed
unity-tech-cn:/release_4_branch
unity-tech-cn:/fix-env-step-loop
unity-tech-cn:/release_5_branch
unity-tech-cn:/fix-walker
unity-tech-cn:/release_6_branch
unity-tech-cn:/hh-32-observation-crawler
unity-tech-cn:/trainer-plugin
unity-tech-cn:/hh-develop-max-steps-demo-recorder
unity-tech-cn:/hh-develop-loco-walker-variable-speed
unity-tech-cn:/exp-0002
unity-tech-cn:/experiment-less-max-step
unity-tech-cn:/hh-develop-hallway-wall-mesh-fix
unity-tech-cn:/release_7_branch
unity-tech-cn:/exp-vince
unity-tech-cn:/hh-develop-gridsensor-tests
unity-tech-cn:/tag-release_8_test0
unity-tech-cn:/tag-release_8_test1
unity-tech-cn:/release_8_branch
unity-tech-cn:/docfix-end-episode
unity-tech-cn:/release_9_branch
unity-tech-cn:/hybrid-action-rewardsignals
unity-tech-cn:/MLA-462-yamato-win
unity-tech-cn:/exp-alternate-atten
unity-tech-cn:/hh-develop-fps_game_project
unity-tech-cn:/fix-conflict-base-env
unity-tech-cn:/release_10_branch
unity-tech-cn:/exp-bullet-hell-trainer
unity-tech-cn:/ai-summit-exp
unity-tech-cn:/comms-grad
unity-tech-cn:/walljump-pushblock
unity-tech-cn:/goal-conditioning
unity-tech-cn:/release_11_branch
unity-tech-cn:/hh-develop-water-balloon-fight
unity-tech-cn:/gc-hyper
unity-tech-cn:/layernorm
unity-tech-cn:/yamato-linux-debug-venv
unity-tech-cn:/soccer-comms
unity-tech-cn:/hh-develop-pushblockcollab
unity-tech-cn:/release_12_branch
unity-tech-cn:/fix-get-step-sp-curr
unity-tech-cn:/continuous-comms
unity-tech-cn:/no-comms
unity-tech-cn:/hh-develop-zombiepushblock
unity-tech-cn:/hypernetwork
unity-tech-cn:/revert-4859-develop-update-readme
unity-tech-cn:/sequencer-env-attention
unity-tech-cn:/hh-develop-variableobs
unity-tech-cn:/exp-tanh
unity-tech-cn:/reward-dist
unity-tech-cn:/exp-weight-decay
unity-tech-cn:/exp-robot
unity-tech-cn:/bullet-hell-barracuda-test-1.3.1
unity-tech-cn:/release_13_branch
unity-tech-cn:/release_14_branch
unity-tech-cn:/exp-clipped-gaussian-entropy
unity-tech-cn:/tic-tac-toe
unity-tech-cn:/hh-develop-dodgeball
unity-tech-cn:/repro-vis-obs-perf
unity-tech-cn:/v2-staging-rebase
unity-tech-cn:/release_15_branch
unity-tech-cn:/release_15_removeendepisode
unity-tech-cn:/release_16_branch
unity-tech-cn:/release_16_fix_gridsensor
unity-tech-cn:/ai-hw-2021
unity-tech-cn:/check-for-ModelOverriders
unity-tech-cn:/fix-grid-obs-shape-init
unity-tech-cn:/fix-gym-needs-reset
unity-tech-cn:/fix-resume-imi
unity-tech-cn:/release_17_branch
unity-tech-cn:/release_17_branch_gpu_test
unity-tech-cn:/colab-links
unity-tech-cn:/exp-continuous-div
unity-tech-cn:/release_17_branch_gpu_2
unity-tech-cn:/exp-diverse-behavior
unity-tech-cn:/grid-onehot-extra-dim-empty
unity-tech-cn:/2.0-verified
unity-tech-cn:/faster-entropy-coeficient-convergence
unity-tech-cn:/pre-r18-update-changelog
unity-tech-cn:/release_18_branch
unity-tech-cn:/main/tracking
unity-tech-cn:/main/reward-providers
unity-tech-cn:/main/project-upgrade
unity-tech-cn:/main/limitation-docs
unity-tech-cn:/develop/nomaxstep-test
unity-tech-cn:/develop/tf2.0
unity-tech-cn:/develop/tanhsquash
unity-tech-cn:/develop/magic-string
unity-tech-cn:/develop/trainerinterface
unity-tech-cn:/develop/separatevalue
unity-tech-cn:/develop/nopreviousactions
unity-tech-cn:/develop/reenablerepeatactions
unity-tech-cn:/develop/0memories
unity-tech-cn:/develop/fixmemoryleak
unity-tech-cn:/develop/reducewalljump
unity-tech-cn:/develop/removeactionholder-onehot
unity-tech-cn:/develop/canonicalize-quaternions
unity-tech-cn:/develop/self-playassym
unity-tech-cn:/develop/demo-load-seek
unity-tech-cn:/develop/progress-bar
unity-tech-cn:/develop/sac-apex
unity-tech-cn:/develop/cubewars
unity-tech-cn:/develop/add-fire
unity-tech-cn:/develop/gym-wrapper
unity-tech-cn:/develop/mm-docs-main-readme
unity-tech-cn:/develop/mm-docs-overview
unity-tech-cn:/develop/no-threading
unity-tech-cn:/develop/dockerfile
unity-tech-cn:/develop/model-store
unity-tech-cn:/develop/checkout-conversion-rebase
unity-tech-cn:/develop/model-transfer
unity-tech-cn:/develop/bisim-review
unity-tech-cn:/develop/taggedobservations
unity-tech-cn:/develop/transfer-bisim
unity-tech-cn:/develop/bisim-sac-transfer
unity-tech-cn:/develop/basketball
unity-tech-cn:/develop/torchmodules
unity-tech-cn:/develop/fixmarkdown
unity-tech-cn:/develop/shortenstrikervsgoalie
unity-tech-cn:/develop/shortengoalie
unity-tech-cn:/develop/torch-save-rp
unity-tech-cn:/develop/torch-to-np
unity-tech-cn:/develop/torch-omp-no-thread
unity-tech-cn:/develop/actionmodel-csharp
unity-tech-cn:/develop/torch-extra
unity-tech-cn:/develop/restructure-torch-networks
unity-tech-cn:/develop/jit
unity-tech-cn:/develop/adjust-cpu-settings-experiment
unity-tech-cn:/develop/torch-sac-threading
unity-tech-cn:/develop/wb
unity-tech-cn:/develop/amrl
unity-tech-cn:/develop/memorydump
unity-tech-cn:/develop/permutepytorch
unity-tech-cn:/develop/sac-targetq
unity-tech-cn:/develop/actions-out
unity-tech-cn:/develop/reshapeonnxmemories
unity-tech-cn:/develop/crawlergail
unity-tech-cn:/develop/debugtorchfood
unity-tech-cn:/develop/hybrid-actions
unity-tech-cn:/develop/bullet-hell
unity-tech-cn:/develop/action-spec-gym
unity-tech-cn:/develop/battlefoodcollector
unity-tech-cn:/develop/use-action-buffers
unity-tech-cn:/develop/hardswish
unity-tech-cn:/develop/leakyrelu
unity-tech-cn:/develop/torch-clip-scale
unity-tech-cn:/develop/contentropy
unity-tech-cn:/develop/manch
unity-tech-cn:/develop/torchcrawlerdebug
unity-tech-cn:/develop/fix-nan
unity-tech-cn:/develop/multitype-buffer
unity-tech-cn:/develop/windows-delay
unity-tech-cn:/develop/torch-tanh
unity-tech-cn:/develop/gail-norm
unity-tech-cn:/develop/multiprocess
unity-tech-cn:/develop/unified-obs
unity-tech-cn:/develop/rm-rf-new-models
unity-tech-cn:/develop/skipcritic
unity-tech-cn:/develop/centralizedcritic
unity-tech-cn:/develop/dodgeball-tests
unity-tech-cn:/develop/cc-teammanager
unity-tech-cn:/develop/weight-decay
unity-tech-cn:/develop/singular-embeddings
unity-tech-cn:/develop/zombieteammanager
unity-tech-cn:/develop/superpush
unity-tech-cn:/develop/teammanager
unity-tech-cn:/develop/zombie-exp
unity-tech-cn:/develop/update-readme
unity-tech-cn:/develop/readme-fix
unity-tech-cn:/develop/coma-noact
unity-tech-cn:/develop/coma-withq
unity-tech-cn:/develop/coma2
unity-tech-cn:/develop/action-slice
unity-tech-cn:/develop/gru
unity-tech-cn:/develop/critic-op-lstm-currentmem
unity-tech-cn:/develop/decaygail
unity-tech-cn:/develop/gail-srl-hack
unity-tech-cn:/develop/rear-pad
unity-tech-cn:/develop/mm-copyright-dates
unity-tech-cn:/develop/dodgeball-raycasts
unity-tech-cn:/develop/collab-envs-exp-ervin
unity-tech-cn:/develop/pushcollabonly
unity-tech-cn:/develop/sample-curation
unity-tech-cn:/develop/soccer-groupman
unity-tech-cn:/develop/input-actuator-tanks
unity-tech-cn:/develop/validate-release-fix
unity-tech-cn:/develop/new-console-log
unity-tech-cn:/develop/lex-walker-model
unity-tech-cn:/develop/lstm-burnin
unity-tech-cn:/develop/grid-vaiable-names
unity-tech-cn:/develop/fix-attn-embedding
unity-tech-cn:/develop/api-documentation-update-some-fixes
unity-tech-cn:/develop/update-grpc
unity-tech-cn:/develop/grid-rootref-debug
unity-tech-cn:/develop/pbcollab-rays
unity-tech-cn:/develop/2.0-verified-pre
unity-tech-cn:/develop/parameterizedenvs
unity-tech-cn:/develop/custom-ray-sensor
unity-tech-cn:/develop/mm-add-v2blog
unity-tech-cn:/develop/custom-raycast
unity-tech-cn:/develop/area-manager
unity-tech-cn:/develop/remove-unecessary-lr
unity-tech-cn:/develop/use-base-env-in-learn
unity-tech-cn:/soccer-fives/multiagent
unity-tech-cn:/develop/cubewars/splashdamage
unity-tech-cn:/develop/add-fire/exp
unity-tech-cn:/develop/add-fire/jit
unity-tech-cn:/develop/add-fire/speedtest
unity-tech-cn:/develop/add-fire/bc
unity-tech-cn:/develop/add-fire/ckpt-2
unity-tech-cn:/develop/add-fire/normalize-context
unity-tech-cn:/develop/add-fire/components-dir
unity-tech-cn:/develop/add-fire/halfentropy
unity-tech-cn:/develop/add-fire/memoryclass
unity-tech-cn:/develop/add-fire/categoricaldist
unity-tech-cn:/develop/add-fire/mm
unity-tech-cn:/develop/add-fire/sac-lst
unity-tech-cn:/develop/add-fire/mm3
unity-tech-cn:/develop/add-fire/continuous
unity-tech-cn:/develop/add-fire/ghost
unity-tech-cn:/develop/add-fire/policy-tests
unity-tech-cn:/develop/add-fire/export-discrete
unity-tech-cn:/develop/add-fire/test-simple-rl-fix-resnet
unity-tech-cn:/develop/add-fire/remove-currdoc
unity-tech-cn:/develop/add-fire/clean2
unity-tech-cn:/develop/add-fire/doc-cleanups
unity-tech-cn:/develop/add-fire/changelog
unity-tech-cn:/develop/add-fire/mm2
unity-tech-cn:/develop/model-transfer/add-physics
unity-tech-cn:/develop/model-transfer/train
unity-tech-cn:/develop/jit/experiments
unity-tech-cn:/exp-vince/sep30-2020
unity-tech-cn:/hh-develop-gridsensor-tests/static
unity-tech-cn:/develop/hybrid-actions/distlist
unity-tech-cn:/develop/bullet-hell/buffer
unity-tech-cn:/goal-conditioning/new
unity-tech-cn:/goal-conditioning/sensors-2
unity-tech-cn:/goal-conditioning/sensors-3-pytest-fix
unity-tech-cn:/goal-conditioning/grid-world
unity-tech-cn:/soccer-comms/disc
unity-tech-cn:/develop/centralizedcritic/counterfact
unity-tech-cn:/develop/centralizedcritic/mm
unity-tech-cn:/develop/centralizedcritic/nonego
unity-tech-cn:/develop/zombieteammanager/disableagent
unity-tech-cn:/develop/zombieteammanager/killfirst
unity-tech-cn:/develop/superpush/int
unity-tech-cn:/develop/superpush/branch-cleanup
unity-tech-cn:/develop/teammanager/int
unity-tech-cn:/develop/teammanager/cubewar-nocycle
unity-tech-cn:/develop/teammanager/cubewars
unity-tech-cn:/develop/superpush/int/hunter
unity-tech-cn:/goal-conditioning/new/allo-crawler
unity-tech-cn:/develop/coma2/clip
unity-tech-cn:/develop/coma2/singlenetwork
unity-tech-cn:/develop/coma2/samenet
unity-tech-cn:/develop/coma2/fixgroup
unity-tech-cn:/develop/coma2/samenet/sum
unity-tech-cn:/hh-develop-dodgeball/goy-input
unity-tech-cn:/develop/soccer-groupman/mod
unity-tech-cn:/develop/soccer-groupman/mod/hunter
unity-tech-cn:/develop/soccer-groupman/mod/hunter/cine
unity-tech-cn:/ai-hw-2021/tensor-applier
拉取从: unity-tech-cn:tag-0.2.1c
unity-tech-cn:/main
unity-tech-cn:/develop-generalizationTraining-TrainerController
unity-tech-cn:/tag-0.2.0
unity-tech-cn:/tag-0.2.1
unity-tech-cn:/tag-0.2.1a
unity-tech-cn:/tag-0.2.1c
unity-tech-cn:/tag-0.2.1d
unity-tech-cn:/hotfix-v0.9.2a
unity-tech-cn:/develop-gpu-test
unity-tech-cn:/0.10.1
unity-tech-cn:/develop-pyinstaller
unity-tech-cn:/develop-horovod
unity-tech-cn:/PhysXArticulations20201
unity-tech-cn:/importdocfix
unity-tech-cn:/develop-resizetexture
unity-tech-cn:/hh-develop-walljump_bugfixes
unity-tech-cn:/develop-walljump-fix-sac
unity-tech-cn:/hh-develop-walljump_rnd
unity-tech-cn:/tag-0.11.0.dev0
unity-tech-cn:/develop-pytorch
unity-tech-cn:/tag-0.11.0.dev2
unity-tech-cn:/develop-newnormalization
unity-tech-cn:/tag-0.11.0.dev3
unity-tech-cn:/develop
unity-tech-cn:/release-0.12.0
unity-tech-cn:/tag-0.12.0-dev
unity-tech-cn:/tag-0.12.0.dev0
unity-tech-cn:/tag-0.12.1
unity-tech-cn:/2D-explorations
unity-tech-cn:/asymm-envs
unity-tech-cn:/tag-0.12.1.dev0
unity-tech-cn:/2D-exploration-raycast
unity-tech-cn:/tag-0.12.1.dev1
unity-tech-cn:/release-0.13.0
unity-tech-cn:/release-0.13.1
unity-tech-cn:/plugin-proof-of-concept
unity-tech-cn:/release-0.14.0
unity-tech-cn:/hotfix-bump-version-master
unity-tech-cn:/soccer-fives
unity-tech-cn:/release-0.14.1
unity-tech-cn:/bug-failed-api-check
unity-tech-cn:/test-recurrent-gail
unity-tech-cn:/hh-add-icons
unity-tech-cn:/release-0.15.0
unity-tech-cn:/release-0.15.1
unity-tech-cn:/hh-develop-all-posed-characters
unity-tech-cn:/internal-policy-ghost
unity-tech-cn:/distributed-training
unity-tech-cn:/hh-develop-improve_tennis
unity-tech-cn:/test-tf-ver
unity-tech-cn:/release_1_branch
unity-tech-cn:/tennis-time-horizon
unity-tech-cn:/whitepaper-experiments
unity-tech-cn:/r2v-yamato-linux
unity-tech-cn:/docs-update
unity-tech-cn:/release_2_branch
unity-tech-cn:/exp-mede
unity-tech-cn:/sensitivity
unity-tech-cn:/release_2_verified_load_fix
unity-tech-cn:/test-sampler
unity-tech-cn:/release_2_verified
unity-tech-cn:/hh-develop-ragdoll-testing
unity-tech-cn:/origin-develop-taggedobservations
unity-tech-cn:/MLA-1734-demo-provider
unity-tech-cn:/sampler-refactor-copy
unity-tech-cn:/PhysXArticulations20201Package
unity-tech-cn:/tag-com.unity.ml-agents_1.0.8
unity-tech-cn:/release_3_branch
unity-tech-cn:/github-actions
unity-tech-cn:/release_3_distributed
unity-tech-cn:/fix-batch-tennis
unity-tech-cn:/distributed-ppo-sac
unity-tech-cn:/gridworld-custom-obs
unity-tech-cn:/hw20-segmentation
unity-tech-cn:/hh-develop-gamedev-demo
unity-tech-cn:/active-variablespeed
unity-tech-cn:/release_4_branch
unity-tech-cn:/fix-env-step-loop
unity-tech-cn:/release_5_branch
unity-tech-cn:/fix-walker
unity-tech-cn:/release_6_branch
unity-tech-cn:/hh-32-observation-crawler
unity-tech-cn:/trainer-plugin
unity-tech-cn:/hh-develop-max-steps-demo-recorder
unity-tech-cn:/hh-develop-loco-walker-variable-speed
unity-tech-cn:/exp-0002
unity-tech-cn:/experiment-less-max-step
unity-tech-cn:/hh-develop-hallway-wall-mesh-fix
unity-tech-cn:/release_7_branch
unity-tech-cn:/exp-vince
unity-tech-cn:/hh-develop-gridsensor-tests
unity-tech-cn:/tag-release_8_test0
unity-tech-cn:/tag-release_8_test1
unity-tech-cn:/release_8_branch
unity-tech-cn:/docfix-end-episode
unity-tech-cn:/release_9_branch
unity-tech-cn:/hybrid-action-rewardsignals
unity-tech-cn:/MLA-462-yamato-win
unity-tech-cn:/exp-alternate-atten
unity-tech-cn:/hh-develop-fps_game_project
unity-tech-cn:/fix-conflict-base-env
unity-tech-cn:/release_10_branch
unity-tech-cn:/exp-bullet-hell-trainer
unity-tech-cn:/ai-summit-exp
unity-tech-cn:/comms-grad
unity-tech-cn:/walljump-pushblock
unity-tech-cn:/goal-conditioning
unity-tech-cn:/release_11_branch
unity-tech-cn:/hh-develop-water-balloon-fight
unity-tech-cn:/gc-hyper
unity-tech-cn:/layernorm
unity-tech-cn:/yamato-linux-debug-venv
unity-tech-cn:/soccer-comms
unity-tech-cn:/hh-develop-pushblockcollab
unity-tech-cn:/release_12_branch
unity-tech-cn:/fix-get-step-sp-curr
unity-tech-cn:/continuous-comms
unity-tech-cn:/no-comms
unity-tech-cn:/hh-develop-zombiepushblock
unity-tech-cn:/hypernetwork
unity-tech-cn:/revert-4859-develop-update-readme
unity-tech-cn:/sequencer-env-attention
unity-tech-cn:/hh-develop-variableobs
unity-tech-cn:/exp-tanh
unity-tech-cn:/reward-dist
unity-tech-cn:/exp-weight-decay
unity-tech-cn:/exp-robot
unity-tech-cn:/bullet-hell-barracuda-test-1.3.1
unity-tech-cn:/release_13_branch
unity-tech-cn:/release_14_branch
unity-tech-cn:/exp-clipped-gaussian-entropy
unity-tech-cn:/tic-tac-toe
unity-tech-cn:/hh-develop-dodgeball
unity-tech-cn:/repro-vis-obs-perf
unity-tech-cn:/v2-staging-rebase
unity-tech-cn:/release_15_branch
unity-tech-cn:/release_15_removeendepisode
unity-tech-cn:/release_16_branch
unity-tech-cn:/release_16_fix_gridsensor
unity-tech-cn:/ai-hw-2021
unity-tech-cn:/check-for-ModelOverriders
unity-tech-cn:/fix-grid-obs-shape-init
unity-tech-cn:/fix-gym-needs-reset
unity-tech-cn:/fix-resume-imi
unity-tech-cn:/release_17_branch
unity-tech-cn:/release_17_branch_gpu_test
unity-tech-cn:/colab-links
unity-tech-cn:/exp-continuous-div
unity-tech-cn:/release_17_branch_gpu_2
unity-tech-cn:/exp-diverse-behavior
unity-tech-cn:/grid-onehot-extra-dim-empty
unity-tech-cn:/2.0-verified
unity-tech-cn:/faster-entropy-coeficient-convergence
unity-tech-cn:/pre-r18-update-changelog
unity-tech-cn:/release_18_branch
unity-tech-cn:/main/tracking
unity-tech-cn:/main/reward-providers
unity-tech-cn:/main/project-upgrade
unity-tech-cn:/main/limitation-docs
unity-tech-cn:/develop/nomaxstep-test
unity-tech-cn:/develop/tf2.0
unity-tech-cn:/develop/tanhsquash
unity-tech-cn:/develop/magic-string
unity-tech-cn:/develop/trainerinterface
unity-tech-cn:/develop/separatevalue
unity-tech-cn:/develop/nopreviousactions
unity-tech-cn:/develop/reenablerepeatactions
unity-tech-cn:/develop/0memories
unity-tech-cn:/develop/fixmemoryleak
unity-tech-cn:/develop/reducewalljump
unity-tech-cn:/develop/removeactionholder-onehot
unity-tech-cn:/develop/canonicalize-quaternions
unity-tech-cn:/develop/self-playassym
unity-tech-cn:/develop/demo-load-seek
unity-tech-cn:/develop/progress-bar
unity-tech-cn:/develop/sac-apex
unity-tech-cn:/develop/cubewars
unity-tech-cn:/develop/add-fire
unity-tech-cn:/develop/gym-wrapper
unity-tech-cn:/develop/mm-docs-main-readme
unity-tech-cn:/develop/mm-docs-overview
unity-tech-cn:/develop/no-threading
unity-tech-cn:/develop/dockerfile
unity-tech-cn:/develop/model-store
unity-tech-cn:/develop/checkout-conversion-rebase
unity-tech-cn:/develop/model-transfer
unity-tech-cn:/develop/bisim-review
unity-tech-cn:/develop/taggedobservations
unity-tech-cn:/develop/transfer-bisim
unity-tech-cn:/develop/bisim-sac-transfer
unity-tech-cn:/develop/basketball
unity-tech-cn:/develop/torchmodules
unity-tech-cn:/develop/fixmarkdown
unity-tech-cn:/develop/shortenstrikervsgoalie
unity-tech-cn:/develop/shortengoalie
unity-tech-cn:/develop/torch-save-rp
unity-tech-cn:/develop/torch-to-np
unity-tech-cn:/develop/torch-omp-no-thread
unity-tech-cn:/develop/actionmodel-csharp
unity-tech-cn:/develop/torch-extra
unity-tech-cn:/develop/restructure-torch-networks
unity-tech-cn:/develop/jit
unity-tech-cn:/develop/adjust-cpu-settings-experiment
unity-tech-cn:/develop/torch-sac-threading
unity-tech-cn:/develop/wb
unity-tech-cn:/develop/amrl
unity-tech-cn:/develop/memorydump
unity-tech-cn:/develop/permutepytorch
unity-tech-cn:/develop/sac-targetq
unity-tech-cn:/develop/actions-out
unity-tech-cn:/develop/reshapeonnxmemories
unity-tech-cn:/develop/crawlergail
unity-tech-cn:/develop/debugtorchfood
unity-tech-cn:/develop/hybrid-actions
unity-tech-cn:/develop/bullet-hell
unity-tech-cn:/develop/action-spec-gym
unity-tech-cn:/develop/battlefoodcollector
unity-tech-cn:/develop/use-action-buffers
unity-tech-cn:/develop/hardswish
unity-tech-cn:/develop/leakyrelu
unity-tech-cn:/develop/torch-clip-scale
unity-tech-cn:/develop/contentropy
unity-tech-cn:/develop/manch
unity-tech-cn:/develop/torchcrawlerdebug
unity-tech-cn:/develop/fix-nan
unity-tech-cn:/develop/multitype-buffer
unity-tech-cn:/develop/windows-delay
unity-tech-cn:/develop/torch-tanh
unity-tech-cn:/develop/gail-norm
unity-tech-cn:/develop/multiprocess
unity-tech-cn:/develop/unified-obs
unity-tech-cn:/develop/rm-rf-new-models
unity-tech-cn:/develop/skipcritic
unity-tech-cn:/develop/centralizedcritic
unity-tech-cn:/develop/dodgeball-tests
unity-tech-cn:/develop/cc-teammanager
unity-tech-cn:/develop/weight-decay
unity-tech-cn:/develop/singular-embeddings
unity-tech-cn:/develop/zombieteammanager
unity-tech-cn:/develop/superpush
unity-tech-cn:/develop/teammanager
unity-tech-cn:/develop/zombie-exp
unity-tech-cn:/develop/update-readme
unity-tech-cn:/develop/readme-fix
unity-tech-cn:/develop/coma-noact
unity-tech-cn:/develop/coma-withq
unity-tech-cn:/develop/coma2
unity-tech-cn:/develop/action-slice
unity-tech-cn:/develop/gru
unity-tech-cn:/develop/critic-op-lstm-currentmem
unity-tech-cn:/develop/decaygail
unity-tech-cn:/develop/gail-srl-hack
unity-tech-cn:/develop/rear-pad
unity-tech-cn:/develop/mm-copyright-dates
unity-tech-cn:/develop/dodgeball-raycasts
unity-tech-cn:/develop/collab-envs-exp-ervin
unity-tech-cn:/develop/pushcollabonly
unity-tech-cn:/develop/sample-curation
unity-tech-cn:/develop/soccer-groupman
unity-tech-cn:/develop/input-actuator-tanks
unity-tech-cn:/develop/validate-release-fix
unity-tech-cn:/develop/new-console-log
unity-tech-cn:/develop/lex-walker-model
unity-tech-cn:/develop/lstm-burnin
unity-tech-cn:/develop/grid-vaiable-names
unity-tech-cn:/develop/fix-attn-embedding
unity-tech-cn:/develop/api-documentation-update-some-fixes
unity-tech-cn:/develop/update-grpc
unity-tech-cn:/develop/grid-rootref-debug
unity-tech-cn:/develop/pbcollab-rays
unity-tech-cn:/develop/2.0-verified-pre
unity-tech-cn:/develop/parameterizedenvs
unity-tech-cn:/develop/custom-ray-sensor
unity-tech-cn:/develop/mm-add-v2blog
unity-tech-cn:/develop/custom-raycast
unity-tech-cn:/develop/area-manager
unity-tech-cn:/develop/remove-unecessary-lr
unity-tech-cn:/develop/use-base-env-in-learn
unity-tech-cn:/soccer-fives/multiagent
unity-tech-cn:/develop/cubewars/splashdamage
unity-tech-cn:/develop/add-fire/exp
unity-tech-cn:/develop/add-fire/jit
unity-tech-cn:/develop/add-fire/speedtest
unity-tech-cn:/develop/add-fire/bc
unity-tech-cn:/develop/add-fire/ckpt-2
unity-tech-cn:/develop/add-fire/normalize-context
unity-tech-cn:/develop/add-fire/components-dir
unity-tech-cn:/develop/add-fire/halfentropy
unity-tech-cn:/develop/add-fire/memoryclass
unity-tech-cn:/develop/add-fire/categoricaldist
unity-tech-cn:/develop/add-fire/mm
unity-tech-cn:/develop/add-fire/sac-lst
unity-tech-cn:/develop/add-fire/mm3
unity-tech-cn:/develop/add-fire/continuous
unity-tech-cn:/develop/add-fire/ghost
unity-tech-cn:/develop/add-fire/policy-tests
unity-tech-cn:/develop/add-fire/export-discrete
unity-tech-cn:/develop/add-fire/test-simple-rl-fix-resnet
unity-tech-cn:/develop/add-fire/remove-currdoc
unity-tech-cn:/develop/add-fire/clean2
unity-tech-cn:/develop/add-fire/doc-cleanups
unity-tech-cn:/develop/add-fire/changelog
unity-tech-cn:/develop/add-fire/mm2
unity-tech-cn:/develop/model-transfer/add-physics
unity-tech-cn:/develop/model-transfer/train
unity-tech-cn:/develop/jit/experiments
unity-tech-cn:/exp-vince/sep30-2020
unity-tech-cn:/hh-develop-gridsensor-tests/static
unity-tech-cn:/develop/hybrid-actions/distlist
unity-tech-cn:/develop/bullet-hell/buffer
unity-tech-cn:/goal-conditioning/new
unity-tech-cn:/goal-conditioning/sensors-2
unity-tech-cn:/goal-conditioning/sensors-3-pytest-fix
unity-tech-cn:/goal-conditioning/grid-world
unity-tech-cn:/soccer-comms/disc
unity-tech-cn:/develop/centralizedcritic/counterfact
unity-tech-cn:/develop/centralizedcritic/mm
unity-tech-cn:/develop/centralizedcritic/nonego
unity-tech-cn:/develop/zombieteammanager/disableagent
unity-tech-cn:/develop/zombieteammanager/killfirst
unity-tech-cn:/develop/superpush/int
unity-tech-cn:/develop/superpush/branch-cleanup
unity-tech-cn:/develop/teammanager/int
unity-tech-cn:/develop/teammanager/cubewar-nocycle
unity-tech-cn:/develop/teammanager/cubewars
unity-tech-cn:/develop/superpush/int/hunter
unity-tech-cn:/goal-conditioning/new/allo-crawler
unity-tech-cn:/develop/coma2/clip
unity-tech-cn:/develop/coma2/singlenetwork
unity-tech-cn:/develop/coma2/samenet
unity-tech-cn:/develop/coma2/fixgroup
unity-tech-cn:/develop/coma2/samenet/sum
unity-tech-cn:/hh-develop-dodgeball/goy-input
unity-tech-cn:/develop/soccer-groupman/mod
unity-tech-cn:/develop/soccer-groupman/mod/hunter
unity-tech-cn:/develop/soccer-groupman/mod/hunter/cine
unity-tech-cn:/ai-hw-2021/tensor-applier
此合并请求有变更与目标分支冲突。
/docs/Unity-Agents---Python-API.md
/python/unityagents/environment.py
/unity-environment/Assets/ML-Agents/Examples/3DBall/Scripts/Ball3DDecision.cs
/docs/Agents-Editor-Interface.md
/docs/Getting-Started-with-Balance-Ball.md
/docs/Making-a-new-Unity-Environment.md
/docs/Organizing-the-Scene.md
/docs/Unity-Agents-Overview.md
/docs/best-practices.md
/docs/installation.md
/docs/Using-TensorFlow-Sharp-in-Unity-(Experimental).md
/python/ppo.py
/python/ppo/history.py
/python/ppo/trainer.py
/python/ppo/models.py
/python/README.md
/python/requirements.txt
/images/normalization.png
2 次代码提交
main
...
tag-0.2.1c
| 作者 | SHA1 | 备注 | 提交日期 |
|---|---|---|---|
|
|
57a9ed38 |
Require tensorflow 1.4.1 (#315)
* Require tensorflow 1.4.1 * modified the python/README.md |
7 年前 |
|
|
ce2ce437 | Added growth parameter to stop failing with allocation under windows for #277 (#278) | 7 年前 |
共有 18 个文件被更改,包括 153 次插入 和 38 次删除
-
19unity-environment/Assets/ML-Agents/Examples/3DBall/Scripts/Ball3DDecision.cs
-
2docs/Agents-Editor-Interface.md
-
16docs/Getting-Started-with-Balance-Ball.md
-
2docs/Making-a-new-Unity-Environment.md
-
2docs/Organizing-the-Scene.md
-
4docs/Unity-Agents---Python-API.md
-
2docs/Unity-Agents-Overview.md
-
10docs/best-practices.md
-
2docs/installation.md
-
2docs/Using-TensorFlow-Sharp-in-Unity-(Experimental).md
-
6python/ppo.py
-
15python/ppo/history.py
-
12python/ppo/trainer.py
-
25python/ppo/models.py
-
4python/unityagents/environment.py
-
2python/README.md
-
2python/requirements.txt
-
64images/normalization.png
|
|||
# Environment Design Best Practices |
|||
|
|||
## General |
|||
* It is often helpful to being with the simplest version of the problem, to ensure the agent can learn it. From there increase |
|||
* It is often helpful to start with the simplest version of the problem, to ensure the agent can learn it. From there increase |
|||
* When possible, It is often helpful to ensure that you can complete the task by using a Player Brain to control the agent. |
|||
* When possible, it is often helpful to ensure that you can complete the task by using a Player Brain to control the agent. |
|||
* If you want the agent the finish a task quickly, it is often helpful to provide a small penalty every step (-0.05) that the agent does not complete the task. In this case completion of the task should also coincide with the end of the episode. |
|||
* If you want the agent to finish a task quickly, it is often helpful to provide a small penalty every step (-0.05) that the agent does not complete the task. In this case completion of the task should also coincide with the end of the episode. |
|||
* Rotation information on GameObjects should be recorded as `state.Add(transform.rotation.eulerAngles.y/180.0f-1.0f);` rather than `state.Add(transform.rotation.y);`. |
|||
* Besides encoding non-numeric values, all inputs should be normalized to be in the range 0 to +1 (or -1 to 1). For example rotation information on GameObjects should be recorded as `state.Add(transform.rotation.eulerAngles.y/180.0f-1.0f);` rather than `state.Add(transform.rotation.y);`. See the equation below for one approach of normaliztaion. |
|||
|
|||
 |
|||
|
|||
## Actions |
|||
* When using continuous control, action values should be clipped to an appropriate range. |
|||
{kind=link}
| 之前 | 之后 |
|---|---|
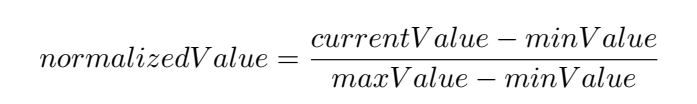
|
|
| 宽度: 697 | 高度: 104 | 大小: 14 KiB |
撰写
预览
正在加载...
取消
保存
Reference in new issue