* Simplified rewards and observations; Determined better settings for training within a reasonable amount of time.
* Simplified Agent rewards; Added training section that discusses hyperparameters.
* Added note about DecisionFrequency.
* Updated screenshots and a small clarification in the text.
* Tested and updated using v0.6.
* Update a couple of images, minor text edit.
* Replace with more recent training stats.
* resolve a couple of minor review commnts.
* Increased the recommended batch and buffer size hyperparameter values.
* Fix 2 typos.
1. Create an environment for your agents to live in. An environment can range
from a simple physical simulation containing a few objects to an entire game
or ecosystem.
from a simple physical simulation containing a few objects to an entire game
or ecosystem.
containing the environment. Your Academy class can implement a few optional
methods to update the scene independently of any agents. For example, you can
add, move, or delete agents and other entities in the environment.
3. Create one or more Brain assets by clicking `Assets -> Create -> ML-Agents
-> Bain`. And name them appropriately.
containing the environment. Your Academy class can implement a few optional
methods to update the scene independently of any agents. For example, you can
add, move, or delete agents and other entities in the environment.
3. Create one or more Brain assets by clicking **Assets** > **Create** >
**ML-Agents** > **Brain**, and naming them appropriately.
uses to observe its environment, to carry out assigned actions, and to
calculate the rewards used for reinforcement training. You can also implement
optional methods to reset the Agent when it has finished or failed its task.
uses to observe its environment, to carry out assigned actions, and to
calculate the rewards used for reinforcement training. You can also implement
optional methods to reset the Agent when it has finished or failed its task.
in the scene that represents the Agent in the simulation. Each Agent object
must be assigned a Brain object.
in the scene that represents the Agent in the simulation. Each Agent object
must be assigned a Brain object.
[run the training process](Training-ML-Agents.md).
[run the training process](Training-ML-Agents.md).
**Note:** If you are unfamiliar with Unity, refer to
[Learning the interface](https://docs.unity3d.com/Manual/LearningtheInterface.html)
importing the ML-Agents assets into it:
1. Launch the Unity Editor and create a new project named "RollerBall".
2. In a file system window, navigate to the folder containing your cloned
ML-Agents repository.
3. Drag the `ML-Agents` folder from `UnitySDK/Assets` to the Unity Editor
Project window.
4. Setup the ML-Agents toolkit by following the instructions [here](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Basic-Guide.md#setting-up-the-ml-agents-toolkit-within-unity).
2. Make sure that the Scripting Runtime Version for the project is set to use
**.NET 4.x Equivalent** (This is an experimental option in Unity 2017,
but is the default as of 2018.3.)
3. In a file system window, navigate to the folder containing your cloned
ML-Agents repository.
4. Drag the `ML-Agents` folder from `UnitySDK/Assets` to the Unity Editor
Project window.
Your Unity **Project** window should contain the following assets:
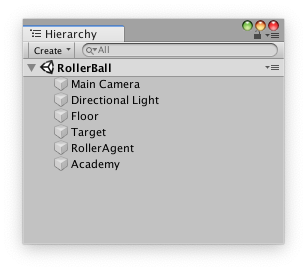
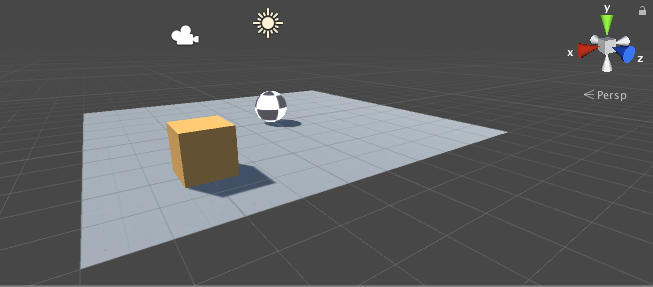
1. Right click in Hierarchy window, select 3D Object > Plane.
2. Name the GameObject "Floor."
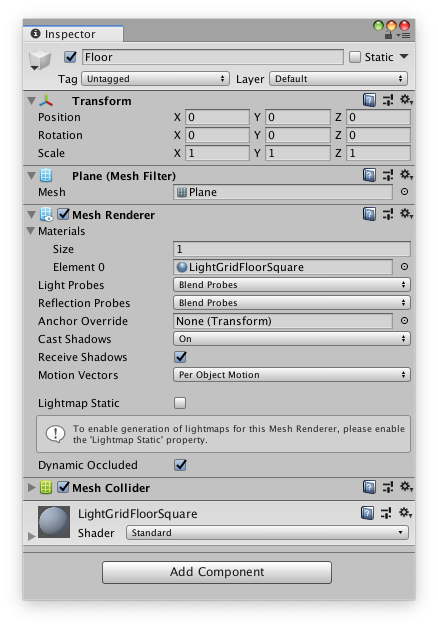
3. Select Plane to view its properties in the Inspector window.
4. Set Transform to Position = (0,0,0), Rotation = (0,0,0), Scale = (1,1,1).
4. Set Transform to Position = (0,0,0), Rotation = (0,0,0), Scale = (1,1,1).
default-material to *floor*.
default-material to *LightGridFloorSquare* (or any suitable material of your choice).
name. This opens the **Object Picker** dialog so that you can choose the a
name. This opens the **Object Picker** dialog so that you can choose a
different material from the list of all materials currently in the project.)

1. Right click in Hierarchy window, select 3D Object > Cube.
2. Name the GameObject "Target"
3. Select Target to view its properties in the Inspector window.
4. Set Transform to Position = (3,0.5,3), Rotation = (0,0,0), Scale = (1,1,1).
4. Set Transform to Position = (3,0.5,3), Rotation = (0,0,0), Scale = (1,1,1).
default-material to *Block*.
default-material to *Block*.

2. Name the GameObject "RollerAgent"
3. Select Target to view its properties in the Inspector window.
4. Set Transform to Position = (0,0.5,0), Rotation = (0,0,0), Scale = (1,1,1).
4. Set Transform to Position = (0,0.5,0), Rotation = (0,0,0), Scale = (1,1,1).
default-material to *checker 1*.
default-material to *CheckerSquare*.
7. Add the Physics/Rigidbody component to the Sphere. (Adding a Rigidbody)
7. Add the Physics/Rigidbody component to the Sphere.

Next, edit the new `RollerAcademy` script:
1. In the Unity Project window, double-click the `RollerAcademy` script to open
it in your code editor. (By default new scripts are placed directly in the
**Assets** folder.)
2. In the editor, change the base class from `MonoBehaviour` to `Academy`.
3. Delete the `Start()` and `Update()` methods that were added by default.
it in your code editor. (By default new scripts are placed directly in the
**Assets** folder.)
2. In the code editor, add the statement, `using MLAgents;`.
3. Change the base class from `MonoBehaviour` to `Academy`.
4. Delete the `Start()` and `Update()` methods that were added by default.
In such a basic scene, we don't need the Academy to initialize, reset, or
otherwise control any objects in the environment so we have the simplest

## Add Brains
## Add Brain Assets
The Brain object encapsulates the decision making process. An Agent sends its
observations to its Brain and expects a decision in return. The type of the Brain
1. Go to `Assets -> Create -> ML-Agents` and select the type of Brain you want to
create. In this tutorial, we will create a **Learning Brain** and
a **Player Brain**.
1. Go to **Assets** > **Create** > **ML-Agents** and select the type of Brain asset
you want to create. For this tutorial, create a **Learning Brain** and
a **Player Brain**.

{kind=link}

{kind=link}

{kind=link}
{kind=link}

{kind=link}
{kind=link}
{kind=link}

{kind=link}
{kind=link}
