当前提交
c3644f56
共有 124 个文件被更改,包括 14228 次插入 和 2604 次删除
-
2.gitignore
-
92README.md
-
353docs/Getting-Started-with-Balance-Ball.md
-
61docs/Readme.md
-
2docs/Training-on-Amazon-Web-Service.md
-
8docs/Limitations-and-Common-Issues.md
-
4docs/Python-API.md
-
10docs/Using-TensorFlow-Sharp-in-Unity.md
-
2docs/Feature-Broadcasting.md
-
2docs/Feature-Monitor.md
-
73python/trainer_config.yaml
-
4python/unityagents/environment.py
-
38python/unitytrainers/models.py
-
27python/unitytrainers/ppo/models.py
-
25python/unitytrainers/ppo/trainer.py
-
2python/unitytrainers/trainer_controller.py
-
19unity-environment/Assets/ML-Agents/Examples/3DBall/Scripts/Ball3DDecision.cs
-
132unity-environment/Assets/ML-Agents/Examples/Crawler/Crawler.unity
-
14unity-environment/Assets/ML-Agents/Examples/Hallway/Scripts/HallwayAcademy.cs
-
8unity-environment/Assets/ML-Agents/Examples/Hallway/Scripts/HallwayAgent.cs
-
2unity-environment/Assets/ML-Agents/Scripts/Academy.cs
-
2unity-environment/Assets/ML-Agents/Scripts/Agent.cs
-
547docs/images/mlagents-BuildWindow.png
-
511docs/images/mlagents-TensorBoard.png
-
345docs/images/brain.png
-
377docs/images/learning_environment_basic.png
-
16docs/Background-Jupyter.md
-
183docs/Background-Machine-Learning.md
-
37docs/Background-TensorFlow.md
-
18docs/Background-Unity.md
-
20docs/Contribution-Guidelines.md
-
3docs/Glossary.md
-
3docs/Installation-Docker.md
-
61docs/Installation.md
-
25docs/Learning-Environment-Best-Practices.md
-
398docs/Learning-Environment-Create-New.md
-
42docs/Learning-Environment-Design-Academy.md
-
277docs/Learning-Environment-Design-Agents.md
-
52docs/Learning-Environment-Design-Brains.md
-
89docs/Learning-Environment-Design.md
-
186docs/Learning-Environment-Examples.md
-
403docs/ML-Agents-Overview.md
-
68docs/Training-Curriculum-Learning.md
-
3docs/Training-Imitation-Learning.md
-
4docs/Training-ML-Agents.md
-
118docs/Training-PPO.md
-
5docs/Using-Tensorboard.md
-
1001docs/dox-ml-agents.conf
-
5docs/doxygen/Readme.md
-
1001docs/doxygen/doxygenbase.css
-
14docs/doxygen/footer.html
-
56docs/doxygen/header.html
-
18docs/doxygen/logo.png
-
146docs/doxygen/navtree.css
-
15docs/doxygen/splitbar.png
-
410docs/doxygen/unity.css
-
219docs/images/academy.png
-
58docs/images/basic.png
-
119docs/images/broadcast.png
-
110docs/images/internal_brain.png
-
744docs/images/learning_environment.png
-
469docs/images/learning_environment_example.png
-
1001docs/images/mlagents-3DBall.png
-
712docs/images/mlagents-3DBallHierarchy.png
-
144docs/images/mlagents-NewProject.png
-
183docs/images/mlagents-NewTutAcademy.png
-
810docs/images/mlagents-NewTutAssignBrain.png
-
186docs/images/mlagents-NewTutBlock.png
-
184docs/images/mlagents-NewTutBrain.png
-
209docs/images/mlagents-NewTutFloor.png
-
54docs/images/mlagents-NewTutHierarchy.png
-
192docs/images/mlagents-NewTutSphere.png
-
591docs/images/mlagents-NewTutSplash.png
-
580docs/images/mlagents-Open3DBall.png
-
1001docs/images/mlagents-Scene.png
-
79docs/images/mlagents-SetExternalBrain.png
-
64docs/images/normalization.png
-
129docs/images/player_brain.png
-
111docs/images/rl_cycle.png
-
79docs/images/scene-hierarchy.png
-
15docs/images/splitbar.png
-
71docs/Agents-Editor-Interface.md
-
127docs/Making-a-new-Unity-Environment.md
-
33docs/Organizing-the-Scene.md
-
43docs/Unity-Agents-Overview.md
-
23docs/best-practices.md
-
55docs/installation.md
-
114docs/best-practices-ppo.md
-
87docs/curriculum.md
-
29docs/Instantiating-Destroying-Agents.md
-
174docs/Example-Environments.md
-
343images/academy.png
-
241images/player_brain.png
-
58python/README.md
-
52unity-environment/README.md
-
0/docs/Limitations-and-Common-Issues.md
-
0/docs/Python-API.md
-
0/docs/Using-TensorFlow-Sharp-in-Unity.md
|
|||
<img src="images/unity-wide.png" align="middle" width="3000"/> |
|||
<img src="docs/images/unity-wide.png" align="middle" width="3000"/> |
|||
# Unity ML - Agents (Beta) |
|||
# Unity ML-Agents (Beta) |
|||
**Unity Machine Learning Agents** allows researchers and developers to |
|||
create games and simulations using the Unity Editor which serve as |
|||
environments where intelligent agents can be trained using |
|||
reinforcement learning, neuroevolution, or other machine learning |
|||
methods through a simple-to-use Python API. For more information, see |
|||
the [documentation page](docs). |
|||
|
|||
For a walkthrough on how to train an agent in one of the provided |
|||
example environments, start |
|||
[here](docs/Getting-Started-with-Balance-Ball.md). |
|||
**Unity Machine Learning Agents** (ML-Agents) is an open-source Unity plugin |
|||
that enables games and simulations to serve as environments for training |
|||
intelligent agents. Agents can be trained using reinforcement learning, |
|||
imitation learning, neuroevolution, or other machine learning methods through |
|||
a simple-to-use Python API. We also provide implementations (based on |
|||
TensorFlow) of state-of-the-art algorithms to enable game developers |
|||
and hobbyists to easily train intelligent agents for 2D, 3D and VR/AR games. |
|||
These trained agents can be used for multiple purposes, including |
|||
controlling NPC behavior (in a variety of settings such as multi-agent and |
|||
adversarial), automated testing of game builds and evaluating different game |
|||
design decisions pre-release. ML-Agents is mutually beneficial for both game |
|||
developers and AI researchers as it provides a central platform where advances |
|||
in AI can be evaluated on Unity’s rich environments and then made accessible |
|||
to the wider research and game developer communities. |
|||
* Multiple observations (cameras) |
|||
* Flexible Multi-agent support |
|||
* Flexible single-agent and multi-agent support |
|||
* Multiple visual observations (cameras) |
|||
* Python (2 and 3) control interface |
|||
* Visualizing network outputs in environment |
|||
* Tensorflow Sharp Agent Embedding _[Experimental]_ |
|||
* Built-in support for Imitation Learning (coming soon) |
|||
* Visualizing network outputs within the environment |
|||
* Python control interface |
|||
* TensorFlow Sharp Agent Embedding _[Experimental]_ |
|||
## Creating an Environment |
|||
## Documentation and References |
|||
The _Agents SDK_, including example environment scenes is located in |
|||
`unity-environment` folder. For requirements, instructions, and other |
|||
information, see the contained Readme and the relevant |
|||
[documentation](docs/Making-a-new-Unity-Environment.md). |
|||
For more information on ML-Agents, in addition to installation, and usage |
|||
instructions, see our [documentation home](docs). |
|||
## Training your Agents |
|||
We have also published a series of blog posts that are relevant for ML-Agents: |
|||
- Overviewing reinforcement learning concepts |
|||
([multi-armed bandit](https://blogs.unity3d.com/2017/06/26/unity-ai-themed-blog-entries/) |
|||
and [Q-learning](https://blogs.unity3d.com/2017/08/22/unity-ai-reinforcement-learning-with-q-learning/)) |
|||
- [Using Machine Learning Agents in a real game: a beginner’s guide](https://blogs.unity3d.com/2017/12/11/using-machine-learning-agents-in-a-real-game-a-beginners-guide/) |
|||
- [Post]() announcing the winners of our |
|||
[first ML-Agents Challenge](https://connect.unity.com/challenges/ml-agents-1) |
|||
- [Post](https://blogs.unity3d.com/2018/01/23/designing-safer-cities-through-simulations/) |
|||
overviewing how Unity can be leveraged as a simulator to design safer cities. |
|||
|
|||
In addition to our own documentation, here are some additional, relevant articles: |
|||
- [Unity AI - Unity 3D Artificial Intelligence](https://www.youtube.com/watch?v=bqsfkGbBU6k) |
|||
- [A Game Developer Learns Machine Learning](https://mikecann.co.uk/machine-learning/a-game-developer-learns-machine-learning-intent/) |
|||
- [Unity3D Machine Learning – Setting up the environment & TensorFlow for AgentML on Windows 10](https://unity3d.college/2017/10/25/machine-learning-in-unity3d-setting-up-the-environment-tensorflow-for-agentml-on-windows-10/) |
|||
- [Explore Unity Technologies ML-Agents Exclusively on Intel Architecture](https://software.intel.com/en-us/articles/explore-unity-technologies-ml-agents-exclusively-on-intel-architecture) |
|||
Once you've built a Unity Environment, example Reinforcement Learning |
|||
algorithms and the Python API are available in the `python` |
|||
folder. For requirements, instructions, and other information, see the |
|||
contained Readme and the relevant |
|||
[documentation](docs/Unity-Agents---Python-API.md). |
|||
## Community and Feedback |
|||
|
|||
ML-Agents is an open-source project and we encourage and welcome contributions. |
|||
If you wish to contribute, be sure to review our |
|||
[contribution guidelines](docs/Contribution-Guidelines.md) and |
|||
[code of conduct](CODE_OF_CONDUCT.md). |
|||
|
|||
You can connect with us and the broader community |
|||
through Unity Connect and GitHub: |
|||
* Join our |
|||
[Unity Machine Learning Channel](https://connect.unity.com/messages/c/035fba4f88400000) |
|||
to connect with others using ML-Agents and Unity developers enthusiastic |
|||
about machine learning. We use that channel to surface updates |
|||
regarding ML-Agents (and, more broadly, machine learning in games). |
|||
* If you run into any problems using ML-Agents, |
|||
[submit an issue](https://github.com/Unity-Technologies/ml-agents/issues) and |
|||
make sure to include as much detail as possible. |
|||
|
|||
For any other questions or feedback, connect directly with the ML-Agents |
|||
team at ml-agents@unity3d.com. |
|||
|
|||
## License |
|||
|
|||
[Apache License 2.0](LICENSE) |
|||
|
|||
# Getting Started with the Balance Ball Example |
|||
# Getting Started with the 3D Balance Ball Example |
|||
 |
|||
This tutorial walks through the end-to-end process of opening an ML-Agents |
|||
example environment in Unity, building the Unity executable, training an agent |
|||
in it, and finally embedding the trained model into the Unity environment. |
|||
This tutorial will walk through the end-to-end process of installing Unity Agents, building an example environment, training an agent in it, and finally embedding the trained model into the Unity environment. |
|||
ML-Agents includes a number of [example environments](Learning-Environment-Examples.md) |
|||
which you can examine to help understand the different ways in which ML-Agents |
|||
can be used. These environments can also serve as templates for new |
|||
environments or as ways to test new ML algorithms. After reading this tutorial, |
|||
you should be able to explore and build the example environments. |
|||
Unity ML Agents contains a number of example environments which can be used as templates for new environments, or as ways to test a new ML algorithm to ensure it is functioning correctly. |
|||
 |
|||
In this walkthrough we will be using the **3D Balance Ball** environment. The environment contains a number of platforms and balls. Platforms can act to keep the ball up by rotating either horizontally or vertically. Each platform is an agent which is rewarded the longer it can keep a ball balanced on it, and provided a negative reward for dropping the ball. The goal of the training process is to have the platforms learn to never drop the ball. |
|||
This walkthrough uses the **3D Balance Ball** environment. 3D Balance Ball |
|||
contains a number of platforms and balls (which are all copies of each other). |
|||
Each platform tries to keep its ball from falling by rotating either |
|||
horizontally or vertically. In this environment, a platform is an **agent** |
|||
that receives a reward for every step that it balances the ball. An agent is |
|||
also penalized with a negative reward for dropping the ball. The goal of the |
|||
training process is to have the platforms learn to never drop the ball. |
|||
In order to install and set-up the Python and Unity environments, see the instructions [here](installation.md). |
|||
In order to install and set up ML-Agents, the Python dependencies and Unity, |
|||
see the [installation instructions](Installation.md). |
|||
|
|||
## Understanding a Unity Environment (Balance Ball) |
|||
|
|||
An agent is an autonomous actor that observes and interacts with an |
|||
_environment_. In the context of Unity, an environment is a scene containing |
|||
an Academy and one or more Brain and Agent objects, and, of course, the other |
|||
entities that an agent interacts with. |
|||
|
|||
 |
|||
|
|||
**Note:** In Unity, the base object of everything in a scene is the |
|||
_GameObject_. The GameObject is essentially a container for everything else, |
|||
including behaviors, graphics, physics, etc. To see the components that make |
|||
up a GameObject, select the GameObject in the Scene window, and open the |
|||
Inspector window. The Inspector shows every component on a GameObject. |
|||
|
|||
The first thing you may notice after opening the 3D Balance Ball scene is that |
|||
it contains not one, but several platforms. Each platform in the scene is an |
|||
independent agent, but they all share the same brain. Balance Ball does this |
|||
to speed up training since all twelve agents contribute to training in parallel. |
|||
|
|||
### Academy |
|||
|
|||
The Academy object for the scene is placed on the Ball3DAcademy GameObject. |
|||
When you look at an Academy component in the inspector, you can see several |
|||
properties that control how the environment works. For example, the |
|||
**Training** and **Inference Configuration** properties set the graphics and |
|||
timescale properties for the Unity application. The Academy uses the |
|||
**Training Configuration** during training and the **Inference Configuration** |
|||
when not training. (*Inference* means that the agent is using a trained model |
|||
or heuristics or direct control — in other words, whenever **not** training.) |
|||
Typically, you set low graphics quality and a high time scale for the |
|||
**Training configuration** and a high graphics quality and the timescale to |
|||
`1.0` for the **Inference Configuration** . |
|||
|
|||
**Note:** if you want to observe the environment during training, you can |
|||
adjust the **Inference Configuration** settings to use a larger window and a |
|||
timescale closer to 1:1. Be sure to set these parameters back when training in |
|||
earnest; otherwise, training can take a very long time. |
|||
|
|||
Another aspect of an environment to look at is the Academy implementation. |
|||
Since the base Academy class is abstract, you must always define a subclass. |
|||
There are three functions you can implement, though they are all optional: |
|||
|
|||
* Academy.InitializeAcademy() — Called once when the environment is launched. |
|||
* Academy.AcademyStep() — Called at every simulation step before |
|||
Agent.AgentStep() (and after the agents collect their state observations). |
|||
* Academy.AcademyReset() — Called when the Academy starts or restarts the |
|||
simulation (including the first time). |
|||
|
|||
The 3D Balance Ball environment does not use these functions — each agent |
|||
resets itself when needed — but many environments do use these functions to |
|||
control the environment around the agents. |
|||
|
|||
### Brain |
|||
|
|||
The Ball3DBrain GameObject in the scene, which contains a Brain component, |
|||
is a child of the Academy object. (All Brain objects in a scene must be |
|||
children of the Academy.) All the agents in the 3D Balance Ball environment |
|||
use the same Brain instance. A Brain doesn't save any state about an agent, |
|||
it just routes the agent's collected state observations to the decision making |
|||
process and returns the chosen action to the agent. Thus, all agents can share |
|||
the same brain, but act independently. The Brain settings tell you quite a bit |
|||
about how an agent works. |
|||
|
|||
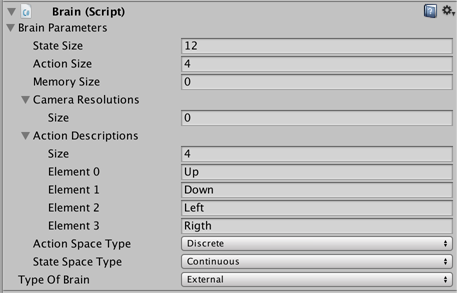
The **Brain Type** determines how an agent makes its decisions. The |
|||
**External** and **Internal** types work together — use **External** when |
|||
training your agents; use **Internal** when using the trained model. |
|||
The **Heuristic** brain allows you to hand-code the agent's logic by extending |
|||
the Decision class. Finally, the **Player** brain lets you map keyboard |
|||
commands to actions, which can be useful when testing your agents and |
|||
environment. If none of these types of brains do what you need, you can |
|||
implement your own CoreBrain to create your own type. |
|||
|
|||
In this tutorial, you will set the **Brain Type** to **External** for training; |
|||
when you embed the trained model in the Unity application, you will change the |
|||
**Brain Type** to **Internal**. |
|||
|
|||
**State Observation Space** |
|||
|
|||
Before making a decision, an agent collects its observation about its state |
|||
in the world. ML-Agents classifies observations into two types: **Continuous** |
|||
and **Discrete**. The **Continuous** state space collects observations in a |
|||
vector of floating point numbers. The **Discrete** state space is an index |
|||
into a table of states. Most of the example environments use a continuous |
|||
state space. |
|||
|
|||
The Brain instance used in the 3D Balance Ball example uses the **Continuous** |
|||
state space with a **State Size** of 8. This means that the feature vector |
|||
containing the agent's observations contains eight elements: the `x` and `z` |
|||
components of the platform's rotation and the `x`, `y`, and `z` components of |
|||
the ball's relative position and velocity. (The state values are defined in |
|||
the agent's `CollectState()` function.) |
|||
|
|||
**Action Space** |
|||
|
|||
An agent is given instructions from the brain in the form of *actions*. Like |
|||
states, ML-Agents classifies actions into two types: the **Continuous** action |
|||
space is a vector of numbers that can vary continuously. What each element of |
|||
the vector means is defined by the agent logic (the PPO training process just |
|||
learns what values are better given particular state observations based on the |
|||
rewards received when it tries different values). For example, an element might |
|||
represent a force or torque applied to a Rigidbody in the agent. The |
|||
**Discrete** action space defines its actions as a table. A specific action |
|||
given to the agent is an index into this table. |
|||
|
|||
The 3D Balance Ball example is programmed to use both types of action space. |
|||
You can try training with both settings to observe whether there is a |
|||
difference. (Set the `Action Size` to 4 when using the discrete action space |
|||
and 2 when using continuous.) |
|||
|
|||
### Agent |
|||
|
|||
The Agent is the actor that observes and takes actions in the environment. |
|||
In the 3D Balance Ball environment, the Agent components are placed on the |
|||
twelve Platform GameObjects. The base Agent object has a few properties that |
|||
affect its behavior: |
|||
|
|||
* **Brain** — Every agent must have a Brain. The brain determines how an agent |
|||
makes decisions. All the agents in the 3D Balance Ball scene share the same |
|||
brain. |
|||
* **Observations** — Defines any Camera objects used by the agent to observe |
|||
its environment. 3D Balance Ball does not use camera observations. |
|||
* **Max Step** — Defines how many simulation steps can occur before the agent |
|||
decides it is done. In 3D Balance Ball, an agent restarts after 5000 steps. |
|||
* **Reset On Done** — Defines whether an agent starts over when it is finished. |
|||
3D Balance Ball sets this true so that the agent restarts after reaching the |
|||
**Max Step** count or after dropping the ball. |
|||
|
|||
Perhaps the more interesting aspect of an agent is the Agent subclass |
|||
implementation. When you create an agent, you must extend the base Agent class. |
|||
The Ball3DAgent subclass defines the following methods: |
|||
|
|||
* Agent.AgentReset() — Called when the Agent resets, including at the beginning |
|||
of a session. The Ball3DAgent class uses the reset function to reset the |
|||
platform and ball. The function randomizes the reset values so that the |
|||
training generalizes to more than a specific starting position and platform |
|||
attitude. |
|||
* Agent.CollectState() — Called every simulation step. Responsible for |
|||
collecting the agent's observations of the environment. Since the Brain |
|||
instance assigned to the agent is set to the continuous state space with a |
|||
state size of 8, the `CollectState()` function returns a vector (technically |
|||
a List<float> object) containing 8 elements. |
|||
* Agent.AgentStep() — Called every simulation step (unless the brain's |
|||
`Frame Skip` property is > 0). Receives the action chosen by the brain. The |
|||
Ball3DAgent example handles both the continuous and the discrete action space |
|||
types. There isn't actually much difference between the two state types in |
|||
this environment — both action spaces result in a small change in platform |
|||
rotation at each step. The `AgentStep()` function assigns a reward to the |
|||
agent; in this example, an agent receives a small positive reward for each |
|||
step it keeps the ball on the platform and a larger, negative reward for |
|||
dropping the ball. An agent is also marked as done when it drops the ball |
|||
so that it will reset with a new ball for the next simulation step. |
|||
## Building Unity Environment |
|||
Launch the Unity Editor, and log in, if necessary. |
|||
## Building the Environment |
|||
1. Open the `unity-environment` folder using the Unity editor. *(If this is not first time running Unity, you'll be able to skip most of these immediate steps, choose directly from the list of recently opened projects)* |
|||
- On the initial dialog, choose `Open` on the top options |
|||
- On the file dialog, choose `unity-environment` and click `Open` *(It is safe to ignore any warning message about non-matching editor installation)* |
|||
- Once the project is open, on the `Project` panel (bottom of the tool), navigate to the folder `Assets/ML-Agents/Examples/3DBall/` |
|||
- Double-click the `Scene` icon (Unity logo) to load all environment assets |
|||
2. Go to `Edit -> Project Settings -> Player` |
|||
- Ensure that `Resolution and Presentation -> Run in Background` is Checked. |
|||
- Ensure that `Resolution and Presentation -> Display Resolution Dialog` is set to Disabled. |
|||
3. Expand the `Ball3DAcademy` GameObject and locate its child object `Ball3DBrain` within the Scene hierarchy in the editor. Ensure Type of Brain for this object is set to `External`. |
|||
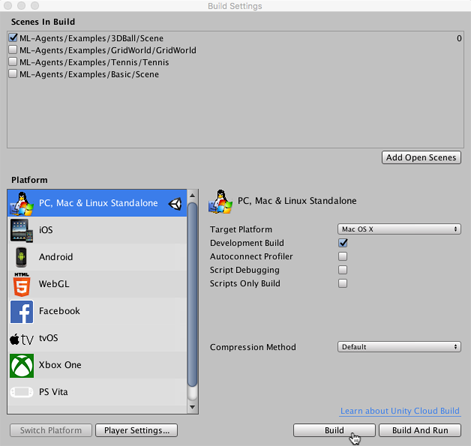
4. *File -> Build Settings* |
|||
5. Choose your target platform: |
|||
- (optional) Select “Development Build” to log debug messages. |
|||
6. Click *Build*: |
|||
- Save environment binary to the `python` sub-directory of the cloned repository *(you may need to click on the down arrow on the file chooser to be able to select that folder)* |
|||
The first step is to open the Unity scene containing the 3D Balance Ball |
|||
environment: |
|||
## Training the Brain with Reinforcement Learning |
|||
1. Launch Unity. |
|||
2. On the Projects dialog, choose the **Open** option at the top of the window. |
|||
3. Using the file dialog that opens, locate the `unity-environment` folder |
|||
within the ML-Agents project and click **Open**. |
|||
4. In the `Project` window, navigate to the folder |
|||
`Assets/ML-Agents/Examples/3DBall/`. |
|||
5. Double-click the `Scene` file to load the scene containing the Balance |
|||
Ball environment. |
|||
### Testing Python API |
|||
 |
|||
To launch jupyter, run in the command line: |
|||
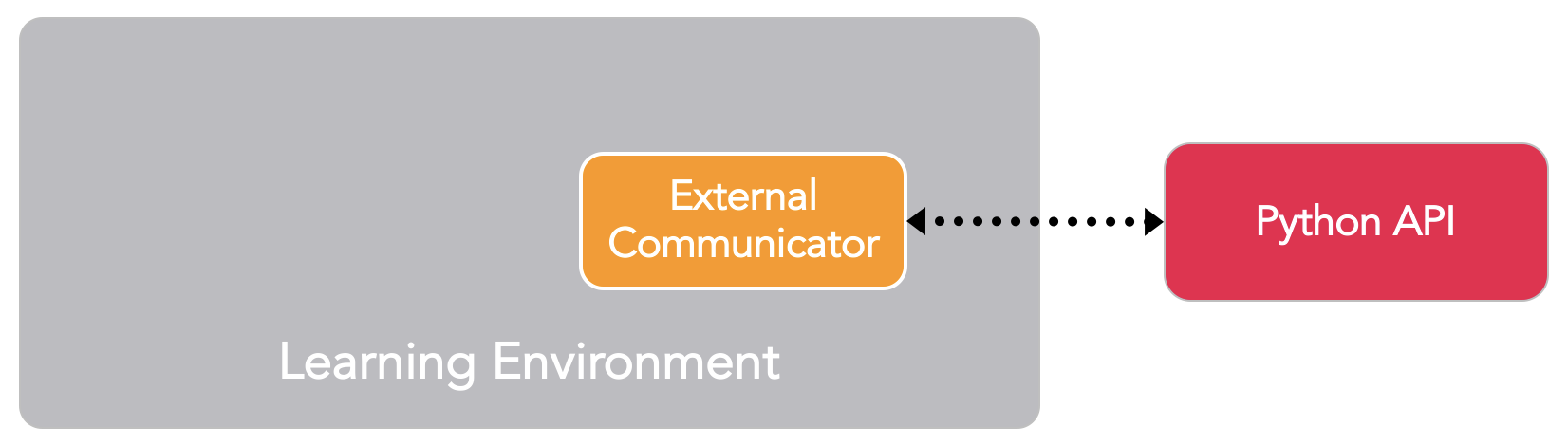
Since we are going to build this environment to conduct training, we need to |
|||
set the brain used by the agents to **External**. This allows the agents to |
|||
communicate with the external training process when making their decisions. |
|||
`jupyter notebook` |
|||
1. In the **Scene** window, click the triangle icon next to the Ball3DAcademy |
|||
object. |
|||
2. Select its child object `Ball3DBrain`. |
|||
3. In the Inspector window, set **Brain Type** to `External`. |
|||
Then navigate to `localhost:8888` to access the notebooks. If you're new to jupyter, check out the [quick start guide](https://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/execute.html) before you continue. |
|||
 |
|||
To ensure that your environment and the Python API work as expected, you can use the `python/Basics` Jupyter notebook. This notebook contains a simple walkthrough of the functionality of the API. Within `Basics`, be sure to set `env_name` to the name of the environment file you built earlier. |
|||
Next, we want the set up scene to to play correctly when the training process |
|||
launches our environment executable. This means: |
|||
* The environment application runs in the background |
|||
* No dialogs require interaction |
|||
* The correct scene loads automatically |
|||
|
|||
1. Open Player Settings (menu: **Edit** > **Project Settings** > **Player**). |
|||
2. Under **Resolution and Presentation**: |
|||
- Ensure that **Run in Background** is Checked. |
|||
- Ensure that **Display Resolution Dialog** is set to Disabled. |
|||
3. Open the Build Settings window (menu:**File** > **Build Settings**). |
|||
4. Choose your target platform. |
|||
- (optional) Select “Development Build” to |
|||
[log debug messages](https://docs.unity3d.com/Manual/LogFiles.html). |
|||
5. If any scenes are shown in the **Scenes in Build** list, make sure that |
|||
the 3DBall Scene is the only one checked. (If the list is empty, than only the |
|||
current scene is included in the build). |
|||
6. Click *Build*: |
|||
a. In the File dialog, navigate to the `python` folder in your ML-Agents |
|||
directory. |
|||
b. Assign a file name and click **Save**. |
|||
|
|||
 |
|||
|
|||
## Training the Brain with Reinforcement Learning |
|||
|
|||
Now that we have a Unity executable containing the simulation environment, we |
|||
can perform the training. |
|||
In order to train an agent to correctly balance the ball, we will use a Reinforcement Learning algorithm called Proximal Policy Optimization (PPO). This is a method that has been shown to be safe, efficient, and more general purpose than many other RL algorithms, as such we have chosen it as the example algorithm for use with ML Agents. For more information on PPO, OpenAI has a recent [blog post](https://blog.openai.com/openai-baselines-ppo/) explaining it. |
|||
|
|||
In order to train an agent to correctly balance the ball, we will use a |
|||
Reinforcement Learning algorithm called Proximal Policy Optimization (PPO). |
|||
This is a method that has been shown to be safe, efficient, and more general |
|||
purpose than many other RL algorithms, as such we have chosen it as the |
|||
example algorithm for use with ML-Agents. For more information on PPO, |
|||
OpenAI has a recent [blog post](https://blog.openai.com/openai-baselines-ppo/) |
|||
explaining it. |
|||
3. (optional) Set `run_path` directory to your choice. |
|||
4. Run all cells of notebook with the exception of the last one under "Export the trained Tensorflow graph." |
|||
3. (optional) In order to get the best results quickly, set `max_steps` to |
|||
50000, set `buffer_size` to 5000, and set `batch_size` to 512. For this |
|||
exercise, this will train the model in approximately ~5-10 minutes. |
|||
4. (optional) Set `run_path` directory to your choice. When using TensorBoard |
|||
to observe the training statistics, it helps to set this to a sequential value |
|||
for each training run. In other words, "BalanceBall1" for the first run, |
|||
"BalanceBall2" or the second, and so on. If you don't, the summaries for |
|||
every training run are saved to the same directory and will all be included |
|||
on the same graph. |
|||
5. Run all cells of notebook with the exception of the last one under "Export |
|||
the trained Tensorflow graph." |
|||
In order to observe the training process in more detail, you can use Tensorboard. |
|||
In your command line, enter into `python` directory and then run : |
|||
In order to observe the training process in more detail, you can use |
|||
TensorBoard. In your command line, enter into `python` directory and then run : |
|||
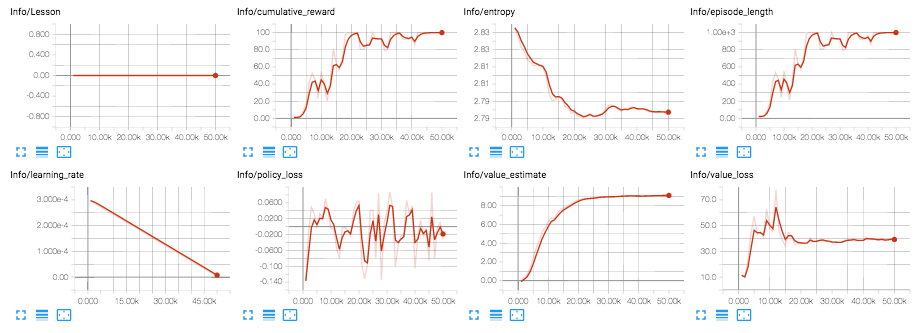
From Tensorboard, you will see the summary statistics of six variables: |
|||
* Cumulative Reward - The mean cumulative episode reward over all agents. Should increase during a successful training session. |
|||
* Value Loss - The mean loss of the value function update. Correlates to how well the model is able to predict the value of each state. This should decrease during a succesful training session. |
|||
* Policy Loss - The mean loss of the policy function update. Correlates to how much the policy (process for deciding actions) is changing. The magnitude of this should decrease during a succesful training session. |
|||
* Episode Length - The mean length of each episode in the environment for all agents. |
|||
* Value Estimates - The mean value estimate for all states visited by the agent. Should increase during a successful training session. |
|||
* Policy Entropy - How random the decisions of the model are. Should slowly decrease during a successful training process. If it decreases too quickly, the `beta` hyperparameter should be increased. |
|||
From TensorBoard, you will see the summary statistics: |
|||
## Embedding Trained Brain into Unity Environment _[Experimental]_ |
|||
Once the training process displays an average reward of ~75 or greater, and there has been a recently saved model (denoted by the `Saved Model` message) you can choose to stop the training process by stopping the cell execution. Once this is done, you now have a trained TensorFlow model. You must now convert the saved model to a Unity-ready format which can be embedded directly into the Unity project by following the steps below. |
|||
* Lesson - only interesting when performing |
|||
[curriculum training](Training-Curriculum-Learning.md). |
|||
This is not used in the 3d Balance Ball environment. |
|||
* Cumulative Reward - The mean cumulative episode reward over all agents. |
|||
Should increase during a successful training session. |
|||
* Entropy - How random the decisions of the model are. Should slowly decrease |
|||
during a successful training process. If it decreases too quickly, the `beta` |
|||
hyperparameter should be increased. |
|||
* Episode Length - The mean length of each episode in the environment for all |
|||
agents. |
|||
* Learning Rate - How large a step the training algorithm takes as it searches |
|||
for the optimal policy. Should decrease over time. |
|||
* Policy Loss - The mean loss of the policy function update. Correlates to how |
|||
much the policy (process for deciding actions) is changing. The magnitude of |
|||
this should decrease during a successful training session. |
|||
* Value Estimate - The mean value estimate for all states visited by the agent. |
|||
Should increase during a successful training session. |
|||
* Value Loss - The mean loss of the value function update. Correlates to how |
|||
well the model is able to predict the value of each state. This should decrease |
|||
during a successful training session. |
|||
|
|||
 |
|||
|
|||
## Embedding the Trained Brain into the Unity Environment _[Experimental]_ |
|||
|
|||
Once the training process completes, and the training process saves the model |
|||
(denoted by the `Saved Model` message) you can add it to the Unity project and |
|||
use it with agents having an **Internal** brain type. |
|||
Because TensorFlowSharp support is still experimental, it is disabled by default. In order to enable it, you must follow these steps. Please note that the `Internal` Brain mode will only be available once completing these steps. |
|||
1. Make sure you are using Unity 2017.1 or newer. |
|||
2. Make sure the TensorFlowSharp plugin is in your `Assets` folder. A Plugins folder which includes TF# can be downloaded [here](https://s3.amazonaws.com/unity-agents/0.2/TFSharpPlugin.unitypackage). Double click and import it once downloaded. |
|||
3. Go to `Edit` -> `Project Settings` -> `Player` |
|||
4. For each of the platforms you target (**`PC, Mac and Linux Standalone`**, **`iOS`** or **`Android`**): |
|||
1. Go into `Other Settings`. |
|||
2. Select `Scripting Runtime Version` to `Experimental (.NET 4.6 Equivalent)` |
|||
3. In `Scripting Defined Symbols`, add the flag `ENABLE_TENSORFLOW` |
|||
Because TensorFlowSharp support is still experimental, it is disabled by |
|||
default. In order to enable it, you must follow these steps. Please note that |
|||
the `Internal` Brain mode will only be available once completing these steps. |
|||
|
|||
1. Make sure the TensorFlowSharp plugin is in your `Assets` folder. A Plugins |
|||
folder which includes TF# can be downloaded |
|||
[here](https://s3.amazonaws.com/unity-agents/0.2/TFSharpPlugin.unitypackage). |
|||
Double click and import it once downloaded. You can see if this was |
|||
successfully installed by checking the TensorFlow files in the Project tab |
|||
under `Assets` -> `ML-Agents` -> `Plugins` -> `Computer` |
|||
2. Go to `Edit` -> `Project Settings` -> `Player` |
|||
3. For each of the platforms you target |
|||
(**`PC, Mac and Linux Standalone`**, **`iOS`** or **`Android`**): |
|||
1. Go into `Other Settings`. |
|||
2. Select `Scripting Runtime Version` to |
|||
`Experimental (.NET 4.6 Equivalent)` |
|||
3. In `Scripting Defined Symbols`, add the flag `ENABLE_TENSORFLOW`. |
|||
After typing in, press Enter. |
|||
4. Go to `File` -> `Save Project` |
|||
1. Run the final cell of the notebook under "Export the trained TensorFlow graph" to produce an `<env_name >.bytes` file. |
|||
2. Move `<env_name>.bytes` from `python/models/ppo/` into `unity-environment/Assets/ML-Agents/Examples/3DBall/TFModels/`. |
|||
1. Run the final cell of the notebook under "Export the trained TensorFlow |
|||
graph" to produce an `<env_name >.bytes` file. |
|||
2. Move `<env_name>.bytes` from `python/models/ppo/` into |
|||
`unity-environment/Assets/ML-Agents/Examples/3DBall/TFModels/`. |
|||
6. Drag the `<env_name>.bytes` file from the Project window of the Editor to the `Graph Model` placeholder in the `3DBallBrain` inspector window. |
|||
6. Drag the `<env_name>.bytes` file from the Project window of the Editor |
|||
to the `Graph Model` placeholder in the `3DBallBrain` inspector window. |
|||
If you followed these steps correctly, you should now see the trained model being used to control the behavior of the balance ball within the Editor itself. From here you can re-build the Unity binary, and run it standalone with your agent's new learned behavior built right in. |
|||
If you followed these steps correctly, you should now see the trained model |
|||
being used to control the behavior of the balance ball within the Editor |
|||
itself. From here you can re-build the Unity binary, and run it standalone |
|||
with your agent's new learned behavior built right in. |
|||
|
|||
# Unity ML Agents Documentation |
|||
|
|||
## About |
|||
* [Unity ML Agents Overview](Unity-Agents-Overview.md) |
|||
* [Example Environments](Example-Environments.md) |
|||
# Unity ML-Agents Documentation |
|||
## Tutorials |
|||
* [Installation & Set-up](installation.md) |
|||
## Getting Started |
|||
* [ML-Agents Overview](ML-Agents-Overview.md) |
|||
* [Background: Unity](Background-Unity.md) |
|||
* [Background: Machine Learning](Background-Machine-Learning.md) |
|||
* [Background: TensorFlow](Background-TensorFlow.md) |
|||
* [Installation & Set-up](Installation.md) |
|||
* [Background: Jupyter Notebooks](Background-Jupyter.md) |
|||
* [Docker Set-up (Experimental)](Using-Docker.md) |
|||
* [Making a new Unity Environment](Making-a-new-Unity-Environment.md) |
|||
* [How to use the Python API](Unity-Agents---Python-API.md) |
|||
* [Example Environments](Learning-Environment-Examples.md) |
|||
## Features |
|||
* [Agents SDK Inspector Descriptions](Agents-Editor-Interface.md) |
|||
* [Scene Organization](Organizing-the-Scene.md) |
|||
* [Curriculum Learning](curriculum.md) |
|||
* [Broadcast](broadcast.md) |
|||
* [Monitor](monitor.md) |
|||
## Creating Learning Environments |
|||
* [Making a new Learning Environment](Learning-Environment-Create-New.md) |
|||
* [Designing a Learning Environment](Learning-Environment-Design.md) |
|||
* [Agents](Learning-Environment-Design-Agents.md) |
|||
* [Academy](Learning-Environment-Design-Academy.md) |
|||
* [Brains](Learning-Environment-Design-Brains.md) |
|||
* [Learning Environment Best Practices](Learning-Environment-Best-Practices.md) |
|||
* [TensorFlowSharp in Unity (Experimental)](Using-TensorFlow-Sharp-in-Unity.md) |
|||
|
|||
## Training |
|||
* [Training ML-Agents](Training-ML-Agents.md) |
|||
* [Training with Proximal Policy Optimization](Training-PPO.md) |
|||
* [Training with Curriculum Learning](Training-Curriculum-Learning.md) |
|||
* [Training with Imitation Learning](Training-Imitation-Learning.md) |
|||
* [TensorflowSharp in Unity [Experimental]](Using-TensorFlow-Sharp-in-Unity-(Experimental).md) |
|||
* [Instanciating and Destroying agents](Instantiating-Destroying-Agents.md) |
|||
|
|||
## Best Practices |
|||
* [Best practices when creating an Environment](best-practices.md) |
|||
* [Best practices when training using PPO](best-practices-ppo.md) |
|||
* [Using TensorBoard to Observe Training](Using-Tensorboard.md) |
|||
* [Limitations & Common Issues](Limitations-&-Common-Issues.md) |
|||
* [ML-Agents Glossary](Glossary.md) |
|||
* [Limitations & Common Issues](Limitations-and-Common-Issues.md) |
|||
|
|||
## C# API and Components |
|||
* Academy |
|||
* Brain |
|||
* Agent |
|||
* CoreBrain |
|||
* Decision |
|||
* Monitor |
|||
|
|||
## Python API |
|||
* [How to use the Python API](Python-API.md) |
|||
|
|||
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
| 宽度: 471 | 高度: 446 | 大小: 72 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
| 宽度: 921 | 高度: 333 | 大小: 77 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
| 宽度: 457 | 高度: 293 | 大小: 47 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
| 宽度: 1652 | 高度: 470 | 大小: 64 KiB |
|
|||
# Jupyter |
|||
|
|||
**Work In Progress** |
|||
|
|||
[Jupyter](https://jupyter.org) is a fantastic tool for writing code with |
|||
embedded visualizations. We provide several such notebooks for testing your |
|||
Python installation and training behaviors. For a walkthrough of how to use |
|||
Jupyter, see |
|||
[Running the Jupyter Notebook](http://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/execute.html) |
|||
in the _Jupyter/IPython Quick Start Guide_. |
|||
|
|||
To launch Jupyter, run in the command line: |
|||
|
|||
`jupyter notebook` |
|||
|
|||
Then navigate to `localhost:8888` to access the notebooks. |
|||
|
|||
# Background: Machine Learning |
|||
|
|||
**Work In Progress** |
|||
|
|||
We will not attempt to provide a thorough treatment of machine learning |
|||
as there are fantastic resources online. However, given that a number |
|||
of users of ML-Agents might not have a formal machine learning background, |
|||
this section provides an overview of terminology to facilitate the |
|||
understanding of ML-Agents. |
|||
|
|||
Machine learning, a branch of artificial intelligence, focuses on learning patterns |
|||
from data. The three main classes of machine learning algorithms include: |
|||
unsupervised learning, supervised learning and reinforcement learning. |
|||
Each class of algorithm learns from a different type of data. The following paragraphs |
|||
provide an overview for each of these classes of machine learning, as well as introductory examples. |
|||
|
|||
## Unsupervised Learning |
|||
|
|||
The goal of unsupervised learning is to group or cluster similar items in a |
|||
data set. For example, consider the players of a game. We may want to group |
|||
the players depending on how engaged they are with the game. This would enable |
|||
us to target different groups (e.g. for highly-engaged players we might |
|||
invite them to be beta testers for new features, while for unengaged players |
|||
we might email them helpful tutorials). Say that we wish to split our players |
|||
into two groups. We would first define basic attributes of the players, such |
|||
as the number of hours played, total money spent on in-app purchases and |
|||
number of levels completed. We can then feed this data set (three attributes |
|||
for every player) to an unsupervised learning algorithm where we specify the |
|||
number of groups to be two. The algorithm would then split the data set of |
|||
players into two groups where the players within each group would be similar |
|||
to each other. Given the attributes we used to describe each player, in this |
|||
case, the output would be a split of all the players into two groups, where |
|||
one group would semantically represent the engaged players and the second |
|||
group would semantically represent the unengaged players. |
|||
|
|||
With unsupervised learning, we did not provide specific examples of which |
|||
players are considered engaged and which are considered unengaged. We just |
|||
defined the appropriate attributes and relied on the algorithm to uncover |
|||
the two groups on its own. This type of data set is typically called an |
|||
unlabeled data set as it is lacking these direct labels. Consequently, |
|||
unsupervised learning can be helpful in situations where these labels can be |
|||
expensive or hard to produce. In the next paragraph, we overview supervised |
|||
learning algorithms which accept input labels in addition to attributes. |
|||
|
|||
## Supervised Learning |
|||
|
|||
In supervised learning, we do not want to just group similar items but directly |
|||
learn a mapping from each item to the group (or class) that it belongs to. |
|||
Returning to our earlier example of |
|||
clustering players, let's say we now wish to predict which of our players are |
|||
about to churn (that is stop playing the game for the next 30 days). We |
|||
can look into our historical records and create a data set that |
|||
contains attributes of our players in addition to a label indicating whether |
|||
they have churned or not. Note that the player attributes we use for this |
|||
churn prediction task may be different from the ones we used for our earlier |
|||
clustering task. We can then feed this data set (attributes **and** label for |
|||
each player) into a supervised learning algorithm which would learn a mapping |
|||
from the player attributes to a label indicating whether that player |
|||
will churn or not. The intuition is that the supervised learning algorithm |
|||
will learn which values of these attributes typically correspond to players |
|||
who have churned and not churned (for example, it may learn that players |
|||
who spend very little and play for very short periods will most likely churn). |
|||
Now given this learned model, we can provide it the attributes of a |
|||
new player (one that recently started playing the game) and it would output |
|||
a _predicted_ label for that player. This prediction is the algorithms |
|||
expectation of whether the player will churn or not. |
|||
We can now use these predictions to target the players |
|||
who are expected to churn and entice them to continue playing the game. |
|||
|
|||
As you may have noticed, for both supervised and unsupervised learning, there |
|||
are two tasks that need to be performed: attribute selection and model |
|||
selection. Attribute selection (also called feature selection) pertains to |
|||
selecting how we wish to represent the entity of interest, in this case, the |
|||
player. Model selection, on the other hand, pertains to selecting the |
|||
algorithm (and its parameters) that perform the task well. Both of these |
|||
tasks are active areas of machine learning research and, in practice, require |
|||
several iterations to achieve good performance. |
|||
|
|||
We now switch to reinforcement learning, the third class of |
|||
machine learning algorithms, and arguably the one most relevant for ML-Agents. |
|||
|
|||
## Reinforcement Learning |
|||
|
|||
Reinforcement learning can be viewed as a form of learning for sequential |
|||
decision making that is commonly associated with controlling robots (but is, |
|||
in fact, much more general). Consider an autonomous firefighting robot that is |
|||
tasked with navigating into an area, finding the fire and neutralizing it. At |
|||
any given moment, the robot perceives the environment through its sensors (e.g. |
|||
camera, heat, touch), processes this information and produces an action (e.g. |
|||
move to the left, rotate the water hose, turn on the water). In other words, |
|||
it is continuously making decisions about how to interact in this environment |
|||
given its view of the world (i.e. sensors input) and objective (i.e. |
|||
neutralizing the fire). Teaching a robot to be a successful firefighting |
|||
machine is precisely what reinforcement learning is designed to do. |
|||
|
|||
More specifically, the goal of reinforcement learning is to learn a **policy**, |
|||
which is essentially a mapping from **observations** to **actions**. An |
|||
observation is what the robot can measure from its **environment** (in this |
|||
case, all its sensory inputs) and an action, in its most raw form, is a change |
|||
to the configuration of the robot (e.g. position of its base, position of |
|||
its water hose and whether the hose is on or off). |
|||
|
|||
The last remaining piece |
|||
of the reinforcement learning task is the **reward signal**. When training a |
|||
robot to be a mean firefighting machine, we provide it with rewards (positive |
|||
and negative) indicating how well it is doing on completing the task. |
|||
Note that the robot does not _know_ how to put out fires before it is trained. |
|||
It learns the objective because it receives a large positive reward when it puts |
|||
out the fire and a small negative reward for every passing second. The fact that |
|||
rewards are sparse (i.e. may not be provided at every step, but only when a |
|||
robot arrives at a success or failure situation), is a defining characteristic of |
|||
reinforcement learning and precisely why learning good policies can be difficult |
|||
(and/or time-consuming) for complex environments. |
|||
|
|||
<p align="center"> |
|||
<img src="images/rl_cycle.png" alt="The reinforcement learning cycle."/> |
|||
</p> |
|||
|
|||
[Learning a policy](https://blogs.unity3d.com/2017/08/22/unity-ai-reinforcement-learning-with-q-learning/) |
|||
usually requires many trials and iterative |
|||
policy updates. More specifically, the robot is placed in several |
|||
fire situations and over time learns an optimal policy which allows it |
|||
to put our fires more effectively. Obviously, we cannot expect to train a |
|||
robot repeatedly in the real world, particularly when fires are involved. This |
|||
is precisely why the use of |
|||
[Unity as a simulator](https://blogs.unity3d.com/2018/01/23/designing-safer-cities-through-simulations/) |
|||
serves as the perfect training grounds for learning such behaviors. |
|||
While our discussion of reinforcement learning has centered around robots, |
|||
there are strong parallels between robots and characters in a game. In fact, |
|||
in many ways, one can view a non-playable character (NPC) as a virtual |
|||
robot, with its own observations about the environment, its own set of actions |
|||
and a specific objective. Thus it is natural to explore how we can |
|||
train behaviors within Unity using reinforcement learning. This is precisely |
|||
what ML-Agents offers. The video linked below includes a reinforcement |
|||
learning demo showcasing training character behaviors using ML-Agents. |
|||
|
|||
<p align="center"> |
|||
<a href="http://www.youtube.com/watch?feature=player_embedded&v=fiQsmdwEGT8" target="_blank"> |
|||
<img src="http://img.youtube.com/vi/fiQsmdwEGT8/0.jpg" alt="RL Demo" width="400" border="10" /> |
|||
</a> |
|||
</p> |
|||
|
|||
Similar to both unsupervised and supervised learning, reinforcement learning |
|||
also involves two tasks: attribute selection and model selection. |
|||
Attribute selection is defining the set of observations for the robot |
|||
that best help it complete its objective, while model selection is defining |
|||
the form of the policy (mapping from observations to actions) and its |
|||
parameters. In practice, training behaviors is an iterative process that may |
|||
require changing the attribute and model choices. |
|||
|
|||
## Training and Inference |
|||
|
|||
One common aspect of all three branches of machine learning is that they |
|||
all involve a **training phase** and an **inference phase**. While the |
|||
details of the training and inference phases are different for each of the |
|||
three, at a high-level, the training phase involves building a model |
|||
using the provided data, while the inference phase involves applying this |
|||
model to new, previously unseen, data. More specifically: |
|||
* For our unsupervised learning |
|||
example, the training phase learns the optimal two clusters based |
|||
on the data describing existing players, while the inference phase assigns a |
|||
new player to one of these two clusters. |
|||
* For our supervised learning example, the |
|||
training phase learns the mapping from player attributes to player label |
|||
(whether they churned or not), and the inference phase predicts whether |
|||
a new player will churn or not based on that learned mapping. |
|||
* For our reinforcement learning example, the training phase learns the |
|||
optimal policy through guided trials, and in the inference phase, the agent |
|||
observes and tales actions in the wild using its learned policy. |
|||
|
|||
To briefly summarize: all three classes of algorithms involve training |
|||
and inference phases in addition to attribute and model selections. What |
|||
ultimately separates them is the type of data available to learn from. In |
|||
unsupervised learning our data set was a collection of attributes, in |
|||
supervised learning our data set was a collection of attribute-label pairs, |
|||
and, lastly, in reinforcement learning our data set was a collection of |
|||
observation-action-reward tuples. |
|||
|
|||
## Deep Learning |
|||
|
|||
To be completed. |
|||
|
|||
Link to TensorFlow background page. |
|||
|
|||
# Background: TensorFlow |
|||
|
|||
**Work In Progress** |
|||
|
|||
## TensorFlow |
|||
|
|||
[TensorFlow](https://www.tensorflow.org/) is a deep learning library. |
|||
|
|||
Link to Arthur's content? |
|||
|
|||
A few words about TensorFlow and why/how it is relevant would be nice. |
|||
|
|||
TensorFlow is used for training the machine learning models in ML-Agents. |
|||
Unless you are implementing new algorithms, the use of TensorFlow |
|||
is mostly abstracted away and behind the scenes. |
|||
|
|||
## TensorBoard |
|||
|
|||
One component of training models with TensorFlow is setting the |
|||
values of certain model attributes (called _hyperparameters_). Finding the |
|||
right values of these hyperparameters can require a few iterations. |
|||
Consequently, we leverage a visualization tool within TensorFlow called |
|||
[TensorBoard](https://www.tensorflow.org/programmers_guide/summaries_and_tensorboard). |
|||
It allows the visualization of certain agent attributes (e.g. reward) |
|||
throughout training which can be helpful in both building |
|||
intuitions for the different hyperparameters and setting the optimal values for |
|||
your Unity environment. We provide more details on setting the hyperparameters |
|||
in later parts of the documentation, but, in the meantime, if you are |
|||
unfamiliar with TensorBoard we recommend this |
|||
[tutorial](https://github.com/dandelionmane/tf-dev-summit-tensorboard-tutorial). |
|||
|
|||
## TensorFlowSharp |
|||
|
|||
Third-party used in Internal Brain mode. |
|||
|
|||
|
|||
|
|||
|
|||
# Background: Unity |
|||
|
|||
If you are not familiar with the [Unity Engine](https://unity3d.com/unity), |
|||
we highly recommend the |
|||
[Unity Manual](https://docs.unity3d.com/Manual/index.html) and |
|||
[Tutorials page](https://unity3d.com/learn/tutorials). The |
|||
[Roll-a-ball tutorial](https://unity3d.com/learn/tutorials/s/roll-ball-tutorial) |
|||
is sufficient to learn all the basic concepts of Unity to get started with |
|||
ML-Agents: |
|||
* [Editor](https://docs.unity3d.com/Manual/UsingTheEditor.html) |
|||
* [Interface](https://docs.unity3d.com/Manual/LearningtheInterface.html) |
|||
* [Scene](https://docs.unity3d.com/Manual/CreatingScenes.html) |
|||
* [GameObjects](https://docs.unity3d.com/Manual/GameObjects.html) |
|||
* [Rigidbody](https://docs.unity3d.com/ScriptReference/Rigidbody.html) |
|||
* [Camera](https://docs.unity3d.com/Manual/Cameras.html) |
|||
* [Scripting](https://docs.unity3d.com/Manual/ScriptingSection.html) |
|||
* [Ordering of event functions](https://docs.unity3d.com/Manual/ExecutionOrder.html) |
|||
(e.g. FixedUpdate, Update) |
|||
|
|||
# Contribution Guidelines |
|||
|
|||
Reference code of conduct. |
|||
|
|||
## GitHub Workflow |
|||
|
|||
## Environments |
|||
|
|||
We are also actively open to adding community contributed environments as |
|||
examples, as long as they are small, simple, demonstrate a unique feature of |
|||
the platform, and provide a unique non-trivial challenge to modern |
|||
machine learning algorithms. Feel free to submit these environments with a |
|||
Pull-Request explaining the nature of the environment and task. |
|||
|
|||
TODO: above paragraph needs expansion. |
|||
|
|||
## Algorithms |
|||
|
|||
## Style Guide |
|||
|
|||
|
|||
# ML-Agents Glossary |
|||
|
|||
**Work In Progress** |
|||
|
|||
# Docker Set-up _[Experimental]_ |
|||
|
|||
**Work In Progress** |
|||
|
|||
# Installation & Set-up |
|||
|
|||
To install and use ML-Agents, you need install Unity, clone this repository |
|||
and install Python with additional dependencies. Each of the subsections |
|||
below overviews each step, in addition to an experimental Docker set-up. |
|||
|
|||
## Install **Unity 2017.1** or Later |
|||
|
|||
[Download](https://store.unity.com/download) and install Unity. |
|||
|
|||
## Clone the ml-agents Repository |
|||
|
|||
Once installed, you will want to clone the ML-Agents GitHub repository. |
|||
|
|||
git clone git@github.com:Unity-Technologies/ml-agents.git |
|||
|
|||
The `unity-environment` directory in this repository contains the Unity Assets |
|||
to add to your projects. The `python` directory contains the training code. |
|||
Both directories are located at the root of the repository. |
|||
|
|||
## Install Python |
|||
|
|||
In order to use ML-Agents, you need Python (2 or 3; 64 bit required) along with |
|||
the dependencies listed in the [requirements file](../python/requirements.txt). |
|||
Some of the primary dependencies include: |
|||
- [TensorFlow](Background-TensorFlow.md) |
|||
- [Jupyter](Background-Jupyter.md) |
|||
|
|||
### Windows Users |
|||
|
|||
If you are a Windows user who is new to Python and TensorFlow, follow |
|||
[this guide](https://unity3d.college/2017/10/25/machine-learning-in-unity3d-setting-up-the-environment-tensorflow-for-agentml-on-windows-10/) |
|||
to set up your Python environment. |
|||
|
|||
### Mac and Unix Users |
|||
|
|||
If your Python environment doesn't include `pip`, see these |
|||
[instructions](https://packaging.python.org/guides/installing-using-linux-tools/#installing-pip-setuptools-wheel-with-linux-package-managers) |
|||
on installing it. |
|||
|
|||
To install dependencies, go into the `python` subdirectory of the repository, |
|||
and run (depending on your Python version) from the command line: |
|||
|
|||
pip install . |
|||
|
|||
or |
|||
|
|||
pip3 install . |
|||
|
|||
## Docker-based Installation _[Experimental]_ |
|||
|
|||
If you'd like to use Docker for ML-Agents, please follow |
|||
[this guide](Using-Docker.md). |
|||
|
|||
## Help |
|||
|
|||
If you run into any problems installing ML-Agents, |
|||
[submit an issue](https://github.com/Unity-Technologies/ml-agents/issues) and |
|||
make sure to cite relevant information on OS, Python version, and exact error |
|||
message (whenever possible). |
|||
|
|||
|
|||
# Environment Design Best Practices |
|||
|
|||
## General |
|||
* It is often helpful to start with the simplest version of the problem, to ensure the agent can learn it. From there increase |
|||
complexity over time. This can either be done manually, or via Curriculum Learning, where a set of lessons which progressively increase in difficulty are presented to the agent ([learn more here](Training-Curriculum-Learning.md)). |
|||
* When possible, it is often helpful to ensure that you can complete the task by using a Player Brain to control the agent. |
|||
|
|||
## Rewards |
|||
* The magnitude of any given reward should typically not be greater than 1.0 in order to ensure a more stable learning process. |
|||
* Positive rewards are often more helpful to shaping the desired behavior of an agent than negative rewards. |
|||
* For locomotion tasks, a small positive reward (+0.1) for forward velocity is typically used. |
|||
* If you want the agent to finish a task quickly, it is often helpful to provide a small penalty every step (-0.05) that the agent does not complete the task. In this case completion of the task should also coincide with the end of the episode. |
|||
* Overly-large negative rewards can cause undesirable behavior where an agent learns to avoid any behavior which might produce the negative reward, even if it is also behavior which can eventually lead to a positive reward. |
|||
|
|||
## States |
|||
* States should include all variables relevant to allowing the agent to take the optimally informed decision. |
|||
* Categorical state variables such as type of object (Sword, Shield, Bow) should be encoded in one-hot fashion (ie `3` -> `0, 0, 1`). |
|||
* Besides encoding non-numeric values, all inputs should be normalized to be in the range 0 to +1 (or -1 to 1). For example rotation information on GameObjects should be recorded as `state.Add(transform.rotation.eulerAngles.y/180.0f-1.0f);` rather than `state.Add(transform.rotation.y);`. See the equation below for one approach of normaliztaion. |
|||
* Positional information of relevant GameObjects should be encoded in relative coordinates wherever possible. This is often relative to the agent position. |
|||
|
|||
 |
|||
|
|||
## Actions |
|||
* When using continuous control, action values should be clipped to an appropriate range. |
|||
* Be sure to set the action-space-size to the number of used actions, and not greater, as doing the latter can interfere with the efficency of the training process. |
|||
|
|||
# Making a new Learning Environment |
|||
|
|||
This tutorial walks through the process of creating a Unity Environment. A Unity Environment is an application built using the Unity Engine which can be used to train Reinforcement Learning agents. |
|||
|
|||
 |
|||
|
|||
In this example, we will train a ball to roll to a randomly placed cube. The ball also learns to avoid falling off the platform. |
|||
|
|||
## Overview |
|||
|
|||
Using ML-Agents in a Unity project involves the following basic steps: |
|||
|
|||
1. Create an environment for your agents to live in. An environment can range from a simple physical simulation containing a few objects to an entire game or ecosystem. |
|||
2. Implement an Academy subclass and add it to a GameObject in the Unity scene containing the environment. This GameObject will serve as the parent for any Brain objects in the scene. Your Academy class can implement a few optional methods to update the scene independently of any agents. For example, you can add, move, or delete agents and other entities in the environment. |
|||
3. Add one or more Brain objects to the scene as children of the Academy. |
|||
4. Implement your Agent subclasses. An Agent subclass defines the code an agent uses to observe its environment, to carry out assigned actions, and to calculate the rewards used for reinforcement training. You can also implement optional methods to reset the agent when it has finished or failed its task. |
|||
5. Add your Agent subclasses to appropriate GameObjects, typically, the object in the scene that represents the agent in the simulation. Each Agent object must be assigned a Brain object. |
|||
6. If training, set the Brain type to External and [run the training process](Training-PPO.md). |
|||
|
|||
|
|||
**Note:** If you are unfamiliar with Unity, refer to [Learning the interface](https://docs.unity3d.com/Manual/LearningtheInterface.html) in the Unity Manual if an Editor task isn't explained sufficiently in this tutorial. |
|||
|
|||
If you haven't already, follow the [installation instructions](Installation.md). |
|||
|
|||
## Set Up the Unity Project |
|||
|
|||
The first task to accomplish is simply creating a new Unity project and importing the ML-Agents assets into it: |
|||
|
|||
1. Launch the Unity Editor and create a new project named "RollerBall". |
|||
|
|||
2. In a file system window, navigate to the folder containing your cloned ML-Agents repository. |
|||
|
|||
3. Drag the `ML-Agents` folder from `unity-environments/Assets` to the Unity Editor Project window. |
|||
|
|||
Your Unity **Project** window should contain the following assets: |
|||
|
|||
 |
|||
|
|||
## Create the Environment: |
|||
|
|||
Next, we will create a very simple scene to act as our ML-Agents environment. The "physical" components of the environment include a Plane to act as the floor for the agent to move around on, a Cube to act as the goal or target for the agent to seek, and a Sphere to represent the agent itself. |
|||
|
|||
**Create the floor plane:** |
|||
|
|||
1. Right click in Hierarchy window, select 3D Object > Plane. |
|||
2. Name the GameObject "Floor." |
|||
3. Select Plane to view its properties in the Inspector window. |
|||
4. Set Transform to Position = (0,0,0), Rotation = (0,0,0), Scale = (1,1,1). |
|||
5. On the Plane's Mesh Renderer, expand the Materials property and change the default-material to *floor*. |
|||
|
|||
(To set a new material, click the small circle icon next to the current material name. This opens the **Object Picker** dialog so that you can choose the a different material from the list of all materials currently in the project.) |
|||
|
|||
 |
|||
|
|||
**Add the Target Cube** |
|||
|
|||
1. Right click in Hierarchy window, select 3D Object > Cube. |
|||
2. Name the GameObject "Target" |
|||
3. Select Target to view its properties in the Inspector window. |
|||
4. Set Transform to Position = (3,0.5,3), Rotation = (0,0,0), Scale = (1,1,1). |
|||
5. On the Cube's Mesh Renderer, expand the Materials property and change the default-material to *block*. |
|||
|
|||
 |
|||
|
|||
**Add the Agent Sphere** |
|||
|
|||
1. Right click in Hierarchy window, select 3D Object > Sphere. |
|||
2. Name the GameObject "RollerAgent" |
|||
3. Select Target to view its properties in the Inspector window. |
|||
4. Set Transform to Position = (0,0.5,0), Rotation = (0,0,0), Scale = (1,1,1). |
|||
5. On the Sphere's Mesh Renderer, expand the Materials property and change the default-material to *checker 1*. |
|||
6. Click **Add Component**. |
|||
7. Add the Physics/Rigidbody component to the Sphere. (Adding a Rigidbody ) |
|||
|
|||
 |
|||
|
|||
Note that we will create an Agent subclass to add to this GameObject as a component later in the tutorial. |
|||
|
|||
**Add Empty GameObjects to Hold the Academy and Brain** |
|||
|
|||
1. Right click in Hierarchy window, select Create Empty. |
|||
2. Name the GameObject "Academy" |
|||
3. Right-click on the Academy GameObject and select Create Empty. |
|||
4. Name this child of the Academy, "Brain". |
|||
|
|||
 |
|||
|
|||
You can adjust the camera angles to give a better view of the scene at runtime. The next steps will be to create and add the ML-Agent components. |
|||
|
|||
## Implement an Academy |
|||
|
|||
The Academy object coordinates the ML-Agents in the scene and drives the decision-making portion of the simulation loop. Every ML-Agent scene needs one Academy instance. Since the base Academy classis abstract, you must make your own subclass even if you don't need to use any of the methods for a particular environment. |
|||
|
|||
First, add a New Script component to the Academy GameObject created earlier: |
|||
|
|||
1. Select the Academy GameObject to view it in the Inspector window. |
|||
2. Click **Add Component**. |
|||
3. Click **New Script** in the list of components (at the bottom). |
|||
4. Name the script "RollerAcademy". |
|||
5. Click **Create and Add**. |
|||
|
|||
Next, edit the new `RollerAcademy` script: |
|||
|
|||
1. In the Unity Project window, double-click the `RollerAcademy` script to open it in your code editor. (By default new scripts are placed directly in the **Assets** folder.) |
|||
2. In the editor, change the base class from `MonoBehaviour` to `Academy`. |
|||
3. Delete the `Start()` and `Update()` methods that were added by default. |
|||
|
|||
In such a basic scene, we don't need the Academy to initialize, reset, or otherwise control any objects in the environment so we have the simplest possible Academy implementation: |
|||
|
|||
public class RollerAcademy : Academy { } |
|||
|
|||
The default settings for the Academy properties are also fine for this environment, so we don't need to change anything for the RollerAcademy component in the Inspector window. |
|||
|
|||
 |
|||
|
|||
## Add a Brain |
|||
|
|||
The Brain object encapsulates the decision making process. An Agent sends its observations to its Brain and expects a decision in return. The Brain Type setting determines how the Brain makes decisions. Unlike the Academy and Agent classes, you don't make your own Brain subclasses. (You can extend CoreBrain to make your own *types* of Brain, but the four built-in brain types should cover almost all scenarios.) |
|||
|
|||
To create the Brain: |
|||
|
|||
1. Right-click the Academy GameObject in the Hierarchy window and choose *Create Empty* to add a child GameObject. |
|||
2. Name the new GameObject, "Brain". |
|||
3. Select the Brain GameObject to show its properties in the Inspector window. |
|||
4. Click **Add Component**. |
|||
5. Select the **Scripts/Brain** component to add it to the GameObject. |
|||
|
|||
We will come back to the Brain properties later, but leave the Brain Type as **Player** for now. |
|||
|
|||
 |
|||
|
|||
## Implement an Agent |
|||
|
|||
To create the Agent: |
|||
|
|||
1. Select the RollerAgent GameObject to view it in the Inspector window. |
|||
2. Click **Add Component**. |
|||
3. Click **New Script** in the list of components (at the bottom). |
|||
4. Name the script "RollerAgent". |
|||
5. Click **Create and Add**. |
|||
|
|||
Then, edit the new `RollerAgent` script: |
|||
|
|||
1. In the Unity Project window, double-click the `RollerAgent` script to open it in your code editor. |
|||
2. In the editor, change the base class from `MonoBehaviour` to `Agent`. |
|||
3. Delete the `Update()` method, but we will use the `Start()` function, so leave it alone for now. |
|||
|
|||
So far, these are the basic steps that you would use to add ML-Agents to any Unity project. Next, we will add the logic that will let our agent learn to roll to the cube. |
|||
|
|||
In this simple scenario, we don't use the Academy object to control the environment. If we wanted to change the environment, for example change the size of the floor or add or remove agents or other objects before or during the simulation, we could implement the appropriate methods in the Academy. Instead, we will have the Agent do all the work of resetting itself and the target when it succeeds or falls trying. |
|||
|
|||
**Initialization and Resetting the Agent** |
|||
|
|||
When the agent reaches its target, it marks itself done and its agent reset function moves the target to a random location. In addition, if the agent rolls off the platform, the reset function puts it back onto the floor. |
|||
|
|||
To move the target GameObject, we need a reference to its Transform (which stores a GameObject's position, orientation and scale in the 3D world). To get this reference, add a public field of type `Transform` to the RollerAgent class. Public fields of a component in Unity get displayed in the Inspector window, allowing you to choose which GameObject to use as the target in the Unity Editor. To reset the agent's velocity (and later to apply force to move the agent) we need a reference to the Rigidbody component. A [Rigidbody](https://docs.unity3d.com/ScriptReference/Rigidbody.html) is Unity's primary element for physics simulation. (See [Physics](https://docs.unity3d.com/Manual/PhysicsSection.html) for full documentation of Unity physics.) Since the Rigidbody component is on the same GameObject as our Agent script, the best way to get this reference is using `GameObject.GetComponent<T>()`, which we can call in our script's `Start()` method. |
|||
|
|||
So far, our RollerAgent script looks like: |
|||
|
|||
using System.Collections.Generic; |
|||
using UnityEngine; |
|||
|
|||
public class RollerAgent : Agent |
|||
{ |
|||
|
|||
Rigidbody rBody; |
|||
void Start () { |
|||
rBody = GetComponent<Rigidbody>(); |
|||
} |
|||
|
|||
public Transform Target; |
|||
public override void AgentReset() |
|||
{ |
|||
if (this.transform.position.y < -1.0) |
|||
{ |
|||
// The agent fell |
|||
this.transform.position = Vector3.zero; |
|||
this.rBody.angularVelocity = Vector3.zero; |
|||
this.rBody.velocity = Vector3.zero; |
|||
} |
|||
else |
|||
{ |
|||
// Move the target to a new spot |
|||
Target.position = new Vector3(Random.value * 8 - 4, |
|||
0.5f, |
|||
Random.value * 8 - 4); |
|||
} |
|||
} |
|||
} |
|||
|
|||
Next, let's implement the Agent.CollectState() function. |
|||
|
|||
**Observing the Environment** |
|||
|
|||
The Agent sends the information we collect to the Brain, which uses it to make a decision. When you train the agent using the PPO training algorithm (or use a trained PPO model), the data is fed into a neural network as a feature vector. For an agent to successfully learn a task, we need to provide the correct information. A good rule of thumb for deciding what information to collect is to consider what you would need to calculate an analytical solution to the problem. |
|||
|
|||
In our case, the information our agent collects includes: |
|||
|
|||
* Position of the target. In general, it is better to use the relative position of other objects rather than the absolute position for more generalizable training. Note that the agent only collects the x and z coordinates since the floor is aligned with the xz plane and the y component of the target's position never changes. |
|||
|
|||
// Calculate relative position |
|||
Vector3 relativePosition = Target.position - this.transform.position; |
|||
|
|||
// Relative position |
|||
observation.Add(relativePosition.x/5); |
|||
observation.Add(relativePosition.z/5); |
|||
|
|||
* Position of the agent itself within the confines of the floor. This data is collected as the agent's distance from each edge of the floor. |
|||
|
|||
// Distance to edges of platform |
|||
observation.Add((this.transform.position.x + 5) / 5); |
|||
observation.Add((this.transform.position.x - 5) / 5); |
|||
observation.Add((this.transform.position.z + 5) / 5); |
|||
observation.Add((this.transform.position.z - 5) / 5); |
|||
|
|||
* The velocity of the agent. This helps the agent learn to control its speed so it doesn't overshoot the target and roll off the platform. |
|||
|
|||
// Agent velocity |
|||
observation.Add(rBody.velocity.x/5); |
|||
observation.Add(rBody.velocity.z/5); |
|||
|
|||
All the values are divided by 5 to normalize the inputs to the neural network to the range [-1,1]. (The number five is used because the platform is 10 units across.) |
|||
|
|||
In total, the state observation contains 8 values and we need to use the continuous state space when we get around to setting the Brain properties: |
|||
|
|||
List<float> observation = new List<float>(); |
|||
public override List<float> CollectState() |
|||
{ |
|||
// Remove last step's observations from the list |
|||
observation.Clear(); |
|||
|
|||
// Calculate relative position |
|||
Vector3 relativePosition = Target.position - this.transform.position; |
|||
|
|||
// Relative position |
|||
observation.Add(relativePosition.x/5); |
|||
observation.Add(relativePosition.z/5); |
|||
|
|||
// Distance to edges of platform |
|||
observation.Add((this.transform.position.x + 5)/5); |
|||
observation.Add((this.transform.position.x - 5)/5); |
|||
observation.Add((this.transform.position.z + 5)/5); |
|||
observation.Add((this.transform.position.z - 5)/5); |
|||
|
|||
// Agent velocity |
|||
observation.Add(rBody.velocity.x/5); |
|||
observation.Add(rBody.velocity.z/5); |
|||
return observation; |
|||
} |
|||
|
|||
The final part of the Agent code is the Agent.AgentStep() function, which receives the decision from the Brain. |
|||
|
|||
**Actions** |
|||
|
|||
The decision of the Brain comes in the form of an action array passed to the `AgentStep()` function. The number of elements in this array is determined by the `Action Space Type` and `ActionSize` settings of the agent's Brain. The RollerAgent uses the continuous action space and needs two continuous control signals from the brain. Thus, we will set the Brain `Action Size` to 2. The first element,`action[0]` determines the force applied along the x axis; `action[1]` determines the force applied along the z axis. (If we allowed the agent to move in three dimensions, then we would need to set `Action Size` to 3. Note the Brain really has no idea what the values in the action array mean. The training process adjust the action values in response to the observation input and then sees what kind of rewards it gets as a result. |
|||
|
|||
Before we can add a force to the agent, we need a reference to its Rigidbody component. A [Rigidbody](https://docs.unity3d.com/ScriptReference/Rigidbody.html) is Unity's primary element for physics simulation. (See [Physics](https://docs.unity3d.com/Manual/PhysicsSection.html) for full documentation of Unity physics.) A good place to set references to other components of the same GameObject is in the standard Unity `Start()` method: |
|||
|
|||
|
|||
With the reference to the Rigidbody, the agent can apply the values from the action[] array using the `Rigidbody.AddForce` function: |
|||
|
|||
Vector3 controlSignal = Vector3.zero; |
|||
controlSignal.x = Mathf.Clamp(action[0], -1, 1); |
|||
controlSignal.z = Mathf.Clamp(action[1], -1, 1); |
|||
rBody.AddForce(controlSignal * speed); |
|||
|
|||
The agent clamps the action values to the range [-1,1] for two reasons. First, the learning algorithm has less incentive to try very large values (since there won't be any affect on agent behavior), which can avoid numeric instability in the neural network calculations. Second, nothing prevents the neural network from returning excessively large values, so we want to limit them to reasonable ranges in any case. |
|||
|
|||
**Rewards** |
|||
|
|||
Rewards are also assigned in the AgentStep() function. The learning algorithm uses the rewards assigned to the Agent.reward property at each step in the simulation and learning process to determine whether it is giving the agent to optimal actions. You want to reward an agent for completing the assigned task (reaching the Target cube, in this case) and punish the agent if it irrevocably fails (falls off the platform). You can sometimes speed up training with sub-rewards that encourage behavior that helps the agent complete the task. For example, the RollerAgent reward system provides a small reward if the agent moves closer to the target in a step. |
|||
|
|||
The RollerAgent calculates the distance to detect when it reaches the target. When it does, the code increments the Agent.reward variable by 1.0 and marks the agent as finished by setting the Agent.done variable to `true`. |
|||
|
|||
float distanceToTarget = Vector3.Distance(this.transform.position, |
|||
Target.position); |
|||
// Reached target |
|||
if (distanceToTarget < 1.42f) |
|||
{ |
|||
this.done = true; |
|||
reward += 1.0f; |
|||
} |
|||
|
|||
**Note:** When you mark an agent as done, it stops its activity until it is reset. You can have the agent reset immediately, by setting the Agent.ResetOnDone property in the inspector or you can wait for the Academy to reset the environment. This RollerBall environment relies on the `ResetOnDone` mechanism and doesn't set a `Max Steps` limit for the Academy (so it never resets the environment). |
|||
|
|||
To encourage the agent along, we also reward it for getting closer to the target (saving the previous distance measurement between steps): |
|||
|
|||
// Getting closer |
|||
if (distanceToTarget < previousDistance) |
|||
{ |
|||
reward += 0.1f; |
|||
} |
|||
|
|||
It can also encourage an agent to finish a task more quickly to assign a negative reward at each step: |
|||
|
|||
// Time penalty |
|||
reward += -0.05f; |
|||
|
|||
Finally, to punish the agent for falling off the platform, assign a large negative reward and, of course, set the agent to done so that it resets itself in the next step: |
|||
|
|||
// Fell off platform |
|||
if (this.transform.position.y < -1.0) |
|||
{ |
|||
this.done = true; |
|||
reward += -1.0f; |
|||
} |
|||
|
|||
**AgentStep()** |
|||
|
|||
With the action and reward logic outlined above, the final version of the `AgentStep()` function looks like: |
|||
|
|||
public float speed = 10; |
|||
private float previousDistance = float.MaxValue; |
|||
|
|||
public override void AgentStep(float[] action) |
|||
{ |
|||
// Rewards |
|||
float distanceToTarget = Vector3.Distance(this.transform.position, |
|||
Target.position); |
|||
|
|||
// Reached target |
|||
if (distanceToTarget < 1.42f) |
|||
{ |
|||
this.done = true; |
|||
reward += 1.0f; |
|||
} |
|||
|
|||
// Getting closer |
|||
if (distanceToTarget < previousDistance) |
|||
{ |
|||
reward += 0.1f; |
|||
} |
|||
|
|||
// Time penalty |
|||
reward += -0.05f; |
|||
|
|||
// Fell off platform |
|||
if (this.transform.position.y < -1.0) |
|||
{ |
|||
this.done = true; |
|||
reward += -1.0f; |
|||
} |
|||
previousDistance = distanceToTarget; |
|||
|
|||
// Actions, size = 2 |
|||
Vector3 controlSignal = Vector3.zero; |
|||
controlSignal.x = Mathf.Clamp(action[0], -1, 1); |
|||
controlSignal.z = Mathf.Clamp(action[1], -1, 1); |
|||
rBody.AddForce(controlSignal * speed); |
|||
} |
|||
|
|||
Note the `speed` and `previousDistance` class variables defined before the function. Since `speed` is public, you can set the value from the Inspector window. |
|||
|
|||
## Final Editor Setup |
|||
|
|||
Now, that all the GameObjects and ML-Agent components are in place, it is time to connect everything together in the Unity Editor. This involves assigning the Brain object to the Agent and setting the Brain properties so that they are compatible with our agent code. |
|||
|
|||
1. Expand the Academy GameObject in the Hierarchy window, so that the Brain object is visible. |
|||
2. Select the RollerAgent GameObject to show its properties in the Inspector window. |
|||
3. Drag the Brain object from the Hierarchy window to the RollerAgent Brain field. |
|||
|
|||
 |
|||
|
|||
Also, drag the Target GameObject from the Hierarchy window to the RollerAgent Target field. |
|||
|
|||
Finally, select the Brain GameObject so that you can see its properties in the Inspector window. Set the following properties: |
|||
|
|||
* `State Size` = 8 |
|||
* `Action Size` = 2 |
|||
* `Action Space Type` = **Continuous** |
|||
* `State Space Type` = **Continuous** |
|||
* `Brain Type` = **Player** |
|||
|
|||
Now you are ready to test the environment before training. |
|||
|
|||
## Testing the Environment |
|||
|
|||
It is always a good idea to test your environment manually before embarking on an extended training run. The reason we have left the Brain set to the **Player** type is so that we can control the agent using direct keyboard control. But first, you need to define the keyboard to action mapping. Although the RollerAgent only has an `Action Size` of two, we will use one key to specify positive values and one to specify negative values for each action, for a total of four keys. |
|||
|
|||
1. Select the Brain GameObject to view its properties in the Inspector. |
|||
2. Set **Brain Type** to **Player**. |
|||
3. Expand the **Continuous Player Actions** dictionary (only visible when using the **Player* brain). |
|||
4. Set **Size** to 4. |
|||
5. Set the following mappings: |
|||
|
|||
| Element | Key | Index | Value | |
|||
| :------------ | :---: | :------: | :------: | |
|||
| Element 0 | D | 0 | 1 | |
|||
| Element 1 | A | 0 | -1 | |
|||
| Element 2 | W | 1 | 1 | |
|||
| Element 3 | S | 1 | -1 | |
|||
|
|||
The **Index** value corresponds to the index of the action array passed to `AgentStep()` function. **Value** is assigned to action[Index] when **Key** is pressed. |
|||
|
|||
Press **Play** to run the scene and use the WASD keys to move the agent around the platform. Make sure that there are no errors displayed in the Unity editor Console window and that the agent resets when it reaches its target or falls from the platform. Note that for more involved debugging, the ML-Agents SDK includes a convenient Monitor class that you can use to easily display agent status information in the Game window. |
|||
|
|||
Now you can train the Agent. To get ready for training, you must first to change the **Brain Type** from **Player** to **External**. From there the process is the same as described in [Getting Started with the 3D Balance Ball Environment](Getting-Started-with-Balance-Ball.md). |
|||
|
|||
|
|||
# Creating an Academy |
|||
|
|||
An Academy orchestrates all the Agent and Brain objects in a Unity scene. Every scene containing agents must contain a single Academy. To use an Academy, you must create your own subclass. However, all the methods you can override are optional. |
|||
|
|||
Use the Academy methods to: |
|||
|
|||
* Initialize the environment after the scene loads |
|||
* Reset the environment |
|||
* Change things in the environment at each simulation step |
|||
|
|||
See [Reinforcement Learning in Unity](Learning-Environment-Design.md) for a description of the timing of these method calls during a simulation. |
|||
|
|||
## Initializing an Academy |
|||
|
|||
Initialization is performed once in an Academy object's lifecycle. Use the `InitializeAcademy()` method for any logic you would normally perform in the standard Unity `Start()` or `Awake()` methods. |
|||
|
|||
**Note:** Because the base Academy implements a `Awake()` function, you must not implement your own. Because of the way the Unity MonoBehaviour class is defined, implementing your own `Awake()` function hides the base class version and Unity will call yours instead. Likewise, do not implement a `FixedUpdate()` function in your Academy subclass. |
|||
|
|||
## Resetting an Environment |
|||
|
|||
Implement an `AcademyReset()` function to alter the environment at the start of each episode. For example, you might want to reset an agent to its starting position or move a goal to a random position. An environment resets when the Academy `Max Steps` count is reached. |
|||
|
|||
When you reset an environment, consider the factors that should change so that training is generalizable to different conditions. For example, if you were training a maze-solving agent, you would probably want to change the maze itself for each training episode. Otherwise, the agent would probably on learn to solve one, particular maze, not mazes in general. |
|||
|
|||
## Controlling an Environment |
|||
|
|||
The `AcademyStep()` function is called at every step in the simulation before any agents are updated. Use this function to update objects in the environment at every step or during the episode between environment resets. For example, if you want to add elements to the environment at random intervals, you can put the logic for creating them in the `AcademyStep()` function. |
|||
|
|||
## Academy Properties |
|||
|
|||
 |
|||
|
|||
* `Max Steps` - Total number of steps per-episode. `0` corresponds to episodes without a maximum number of steps. Once the step counter reaches maximum, the environment will reset. |
|||
* `Frames To Skip` - How many steps of the environment to skip before asking Brains for decisions. |
|||
* `Wait Time` - How many seconds to wait between steps when running in `Inference`. |
|||
* `Configuration` - The engine-level settings which correspond to rendering quality and engine speed. |
|||
* `Width` - Width of the environment window in pixels. |
|||
* `Height` - Width of the environment window in pixels. |
|||
* `Quality Level` - Rendering quality of environment. (Higher is better) |
|||
* `Time Scale` - Speed at which environment is run. (Higher is faster) |
|||
* `Target Frame Rate` - FPS engine attempts to maintain. |
|||
* `Default Reset Parameters` - List of custom parameters that can be changed in the environment on reset. |
|||
|
|||
# Agents |
|||
|
|||
An agent is an actor that can observe its environment and decide on the best course of action using those observations. Create agents in Unity by extending the Agent class. The most important aspects of creating agents that can successfully learn are the observations the agent collects and the reward you assign to estimate the value of the agent's current state toward accomplishing its tasks. |
|||
|
|||
In the ML-Agents framework, an agent passes its observations to its brain at each simulation step. The brain, then, makes a decision and passes the chosen action back to the agent. The agent code executes the action, for example, it moves the agent in one direction or another, and also calculates a reward based on the current state. In training, the reward is used to discover the optimal decision-making policy. (The reward is not used by already trained agents.) |
|||
|
|||
The Brain class abstracts out the decision making logic from the agent itself so that you can use the same brain in multiple agents. |
|||
How a brain makes its decisions depends on the type of brain it is. An **External** brain simply passes the observations from its agents to an external process and then passes the decisions made externally back to the agents. During training, the ML-Agents [reinforcement learning](Learning-Environment-Design.md) algorithm adjusts its internal policy parameters to make decisions that optimize the rewards received over time. An Internal brain uses the trained policy parameters to make decisions (and no longer adjusts the parameters in search of a better decision). The other types of brains do not directly involve training, but you might find them useful as part of a training project. See [Brains](Learning-Environment-Design-Brains.md). |
|||
|
|||
## Observations and State |
|||
|
|||
To make decisions, an agent must observe its environment to determine its current state. A state observation can take the following forms: |
|||
|
|||
* **Continuous** — a feature vector consisting of an array of numbers. |
|||
* **Discrete** — an index into a state table (typically only useful for the simplest of environments). |
|||
* **Camera** — one or more camera images. |
|||
|
|||
When you use the **Continuous** or **Discrete** state space for an agent, implement the `Agent.CollectState()` method to create the feature vector or state index. When you use camera observations, you only need to identify which Unity Camera objects will provide images and the base Agent class handles the rest. You do not need to implement the `CollectState()` method. |
|||
|
|||
### Continuous State Space: Feature Vectors |
|||
|
|||
For agents using a continuous state space, you create a feature vector to represent the agent's observation at each step of the simulation. The Brain class calls the `CollectState()` method of each of its agents. Your implementation of this function returns the feature vector observation as a `List<float>` object. |
|||
|
|||
The observation must include all the information an agent needs to accomplish its task. Without sufficient and relevant information, an agent may learn poorly or may not learn at all. A reasonable approach for determining what information should be included is to consider what you would need to calculate an analytical solution to the problem. |
|||
|
|||
For examples of various state observation functions, you can look at the [Examples](Learning-Environment-Examples.md) included in the ML-Agents SDK. For instance, the 3DBall example uses the rotation of the platform, the relative position of the ball, and the velocity of the ball as its state observation. As an experiment, you can remove the velocity components from the observation and retrain the 3DBall agent. While it will learn to balance the ball reasonably well, the performance of the agent without using velocity is noticeably worse. |
|||
|
|||
public GameObject ball; |
|||
|
|||
private List<float> state = new List<float>(); |
|||
public override List<float> CollectState() |
|||
{ |
|||
state.Clear(); |
|||
state.Add(gameObject.transform.rotation.z); |
|||
state.Add(gameObject.transform.rotation.x); |
|||
state.Add((ball.transform.position.x - gameObject.transform.position.x)); |
|||
state.Add((ball.transform.position.y - gameObject.transform.position.y)); |
|||
state.Add((ball.transform.position.z - gameObject.transform.position.z)); |
|||
state.Add(ball.transform.GetComponent<Rigidbody>().velocity.x); |
|||
state.Add(ball.transform.GetComponent<Rigidbody>().velocity.y); |
|||
state.Add(ball.transform.GetComponent<Rigidbody>().velocity.z); |
|||
return state; |
|||
} |
|||
|
|||
<!-- Note that the above values aren't normalized, which we recommend! --> |
|||
|
|||
The feature vector must always contain the same number of elements and observations must always be in the same position within the list. If the number of observed entities in an environment can vary you can pad the feature vector with zeros for any missing entities in a specific observation or you can limit an agent's observations to a fixed subset. For example, instead of observing every enemy agent in an environment, you could only observe the closest five. |
|||
|
|||
When you set up an Agent's brain in the Unity Editor, set the following properties to use a continuous state-space feature vector: |
|||
|
|||
**State Size** — The state size must match the length of your feature vector. |
|||
**State Space Type** — Set to **Continuous**. |
|||
**Brain Type** — Set to **External** during training; set to **Internal** to use the trained model. |
|||
|
|||
The observation feature vector is a list of floating point numbers, which means you must convert any other data types to a float or a list of floats. |
|||
|
|||
Integers can be be added directly to the state vector, relying on implicit conversion in the `List.Add()` function. You must explicitly convert Boolean values to a number: |
|||
|
|||
state.Add(isTrueOrFalse ? 1 : 0); |
|||
|
|||
For entities like positions and rotations, you can add their components to the feature list individually. For example: |
|||
|
|||
Vector3 speed = ball.transform.GetComponent<Rigidbody>().velocity; |
|||
state.Add(speed.x); |
|||
state.Add(speed.y); |
|||
state.Add(speed.z); |
|||
|
|||
Type enumerations should be encoded in the _one-hot_ style. That is, add an element to the feature vector for each element of enumeration, setting the element representing the observed member to one and set the rest to zero. For example, if your enumeration contains \[Sword, Shield, Bow\] and the agent observes that the current item is a Bow, you would add the elements: 0, 0, 1 to the feature vector. The following code example illustrates how to add |
|||
|
|||
enum CarriedItems { Sword, Shield, Bow, LastItem } |
|||
private List<float> state = new List<float>(); |
|||
public override List<float> CollectState() |
|||
{ |
|||
state.Clear(); |
|||
for (int ci = 0; ci < (int)CarriedItems.LastItem; ci++) |
|||
{ |
|||
state.Add((int)currentItem == ci ? 1.0f : 0.0f); |
|||
} |
|||
return state; |
|||
} |
|||
|
|||
|
|||
<!-- |
|||
How to handle things like large numbers of words or symbols? Should you use a very long one-hot vector? Or a single index into a table? |
|||
Colors? Better to use a single color number or individual components? |
|||
--> |
|||
|
|||
#### Normalization |
|||
|
|||
For the best results when training, you should normalize the components of your feature vector to the range [-1, +1] or [0, 1]. When you normalize the values, the PPO neural network can often converge to a solution faster. Note that it isn't always necessary to normalize to these recommended ranges, but it is considered a best practice when using neural networks. The greater the variation in ranges between the components of your observation, the more likely that training will be affected. |
|||
|
|||
To normalize a value to [0, 1], you can use the following formula: |
|||
|
|||
normalizedValue = (currentValue - minValue)/(maxValue - minValue) |
|||
|
|||
Rotations and angles should also be normalized. For angles between 0 and 360 degrees, you can use the following formulas: |
|||
|
|||
Quaternion rotation = transform.rotation; |
|||
Vector3 normalized = rotation.eulerAngles/180.0f - Vector3.one; // [-1,1] |
|||
Vector3 normalized = rotation.eulerAngles/360.0f; // [0,1] |
|||
|
|||
For angles that can be outside the range [0,360], you can either reduce the angle, or, if the number of turns is significant, increase the maximum value used in your normalization formula. |
|||
|
|||
### Camera Observations |
|||
|
|||
Camera observations use rendered textures from one or more cameras in a scene. The brain vectorizes the textures and feeds them into a neural network. You can use camera observations and either continuous feature vector or discrete state observations at the same time. |
|||
|
|||
Agents using camera images can capture state of arbitrary complexity and are useful when the state is difficult to describe numerically. However, they are also typically less efficient and slower to train, and sometimes don't succeed at all. |
|||
|
|||
### Discrete State Space: Table Lookup |
|||
|
|||
You can use the discrete state space when an agent only has a limited number of possible states and those states can be enumerated by a single number. For instance, the [Basic example environment](Learning-Environment-Examples.md) in the ML Agent SDK defines an agent with a discrete state space. The states of this agent are the integer steps between two linear goals. In the Basic example, the agent learns to move to the goal that provides the greatest reward. |
|||
|
|||
More generally, the discrete state identifier could be an index into a table of the possible states. However, tables quickly become unwieldy as the environment becomes more complex. For example, even a simple game like [tic-tac-toe has 765 possible states](https://en.wikipedia.org/wiki/Game_complexity) (far more if you don't reduce the number of states by combining those that are rotations or reflections of each other). |
|||
|
|||
To implement a discrete state observation, implement the `CollectState()` method of your Agent subclass and return a `List` containing a single number representing the state: |
|||
|
|||
private List<float> state = new List<float>(); |
|||
public override List<float> CollectState() |
|||
{ |
|||
state[0] = stateIndex; // stateIndex is the state identifier |
|||
return state; |
|||
} |
|||
|
|||
## Actions |
|||
|
|||
An action is an instruction from the brain that the agent carries out. The action is passed to the agent as a parameter when the Academy invokes the agent's `AgentStep()` function. When you specify that the action space is **Continuous**, the action parameter passed to the agent is an array of control signals with length equal to the `Action Size` property. When you specify a **Discrete** action space, the action parameter is an array containing only a single value, which is an index into your list or table of commands. In the **Discrete** action space, the `Action Size` is the number of elements in your action table. Set the `Action Space` and `Action Size` properties on the Brain object assigned to the agent (using the Unity Editor Inspector window). |
|||
|
|||
Neither the Brain nor the training algorithm know anything about what the action values themselves mean. The training algorithm simply tries different values for the action list and observes the affect on the accumulated rewards over time and many training episodes. Thus, the only place actions are defined for an agent is in the `AgentStep()` function. You simply specify the type of action space, and, for the continuous action space, the number of values, and then apply the received values appropriately (and consistently) in `ActionStep()`. |
|||
|
|||
For example, if you designed an agent to move in two dimensions, you could use either continuous or the discrete actions. In the continuous case, you would set the action size to two (one for each dimension), and the agent's brain would create an action with two floating point values. In the discrete case, you would set the action size to four (one for each direction), and the brain would create an action array containing a single element with a value ranging from zero to four. |
|||
|
|||
Note that when you are programming actions for an agent, it is often helpful to test your action logic using a **Player** brain, which lets you map keyboard commands to actions. See [Brains](Learning-Environment-Design-Brains.md). |
|||
|
|||
The [3DBall and Area example projects](Learning-Environment-Examples.md) are set up to use either the continuous or the discrete action spaces. |
|||
|
|||
### Continuous Action Space |
|||
|
|||
When an agent uses a brain set to the **Continuous** action space, the action parameter passed to the agent's `AgentStep()` function is an array with length equal to the Brain object's `Action Size` property value. The individual values in the array have whatever meanings that you ascribe to them. If you assign an element in the array as the speed of an agent, for example, the training process learns to control the speed of the agent though this parameter. |
|||
|
|||
The [Reacher example](Learning-Environment-Examples.md) defines a continuous action space with four control values. |
|||
|
|||
 |
|||
|
|||
These control values are applied as torques to the bodies making up the arm : |
|||
|
|||
public override void AgentStep(float[] act) |
|||
{ |
|||
float torque_x = Mathf.Clamp(act[0], -1, 1) * 100f; |
|||
float torque_z = Mathf.Clamp(act[1], -1, 1) * 100f; |
|||
rbA.AddTorque(new Vector3(torque_x, 0f, torque_z)); |
|||
|
|||
torque_x = Mathf.Clamp(act[2], -1, 1) * 100f; |
|||
torque_z = Mathf.Clamp(act[3], -1, 1) * 100f; |
|||
rbB.AddTorque(new Vector3(torque_x, 0f, torque_z)); |
|||
} |
|||
|
|||
You should clamp continuous action values to a reasonable value (typically [-1,1]) to avoid introducing instability while training the agent with the PPO algorithm. As shown above, you can scale the control values as needed after clamping them. |
|||
|
|||
### Discrete Action Space |
|||
|
|||
When an agent uses a brain set to the **Discrete** action space, the action parameter passed to the agent's `AgentStep()` function is an array containing a single element. The value is the index of the action to in your table or list of actions. With the discrete action space, `Action Size` represents the number of actions in your action table. |
|||
|
|||
The [Area example](Learning-Environment-Examples.md) defines five actions for the discrete action space: a jump action and one action for each cardinal direction: |
|||
|
|||
// Get the action index |
|||
int movement = Mathf.FloorToInt(act[0]); |
|||
|
|||
// Look up the index in the action list: |
|||
if (movement == 1) { directionX = -1; } |
|||
if (movement == 2) { directionX = 1; } |
|||
if (movement == 3) { directionZ = -1; } |
|||
if (movement == 4) { directionZ = 1; } |
|||
if (movement == 5 && GetComponent<Rigidbody>().velocity.y <= 0) { directionY = 1; } |
|||
|
|||
// Apply the action results to move the agent |
|||
gameObject.GetComponent<Rigidbody>().AddForce( |
|||
new Vector3( |
|||
directionX * 40f, directionY * 300f, directionZ * 40f)); |
|||
|
|||
Note that the above code example is a simplified extract from the AreaAgent class, which provides alternate implementations for both the discrete and the continuous action spaces. |
|||
|
|||
## Rewards |
|||
|
|||
A reward is a signal that the agent has done something right. The PPO reinforcement learning algorithm works by optimizing the choices an agent makes such that the agent earns the highest cumulative reward over time. The better your reward mechanism, the better your agent will learn. |
|||
|
|||
Perhaps the best advice is to start simple and only add complexity as needed. In general, you should reward results rather than actions you think will lead to the desired results. To help develop your rewards, you can use the Monitor class to display the cumulative reward received by an agent. You can even use a Player brain to control the agent while watching how it accumulates rewards. |
|||
|
|||
Allocate rewards to an agent by setting the agent's `reward` property in the `AgentStep()` function. The reward assigned in any step should be in the range [-1,1]. Values outside this range can lead to unstable training. The `reward` value is reset to zero at every step. |
|||
|
|||
**Examples** |
|||
|
|||
You can examine the `AgentStep()` functions defined in the [Examples](Learning-Environment-Examples.md) to see how those projects allocate rewards. |
|||
|
|||
The `GridAgent` class in the [GridWorld example](Learning-Environment-Examples.md) uses a very simple reward system: |
|||
|
|||
Collider[] hitObjects = Physics.OverlapBox(trueAgent.transform.position, |
|||
new Vector3(0.3f, 0.3f, 0.3f)); |
|||
if (hitObjects.Where(col => col.gameObject.tag == "goal").ToArray().Length == 1) |
|||
{ |
|||
reward = 1f; |
|||
done = true; |
|||
} |
|||
if (hitObjects.Where(col => col.gameObject.tag == "pit").ToArray().Length == 1) |
|||
{ |
|||
reward = -1f; |
|||
done = true; |
|||
} |
|||
|
|||
The agent receives a positive reward when it reaches the goal and a negative reward when it falls into the pit. Otherwise, it gets no rewards. This is an example of a _sparse_ reward system. The agent must explore a lot to find the infrequent reward. |
|||
|
|||
In contrast, the `AreaAgent` in the [Area example](Learning-Environment-Examples.md) gets a small negative reward every step. In order to get the maximum reward, the agent must finish its task of reaching the goal square as quickly as possible: |
|||
|
|||
reward = -0.005f; |
|||
MoveAgent(act); |
|||
|
|||
if (gameObject.transform.position.y < 0.0f || |
|||
Mathf.Abs(gameObject.transform.position.x - area.transform.position.x) > 8f || |
|||
Mathf.Abs(gameObject.transform.position.z + 5 - area.transform.position.z) > 8) |
|||
{ |
|||
done = true; |
|||
reward = -1f; |
|||
} |
|||
|
|||
The agent also gets a larger negative penalty if it falls off the playing surface. |
|||
|
|||
The `Ball3DAgent` in the [3DBall](Learning-Environment-Examples.md) takes a similar approach, but allocates a small positive reward as long as the agent balances the ball. The agent can maximize its rewards by keeping the ball on the platform: |
|||
|
|||
if (done == false) |
|||
{ |
|||
reward = 0.1f; |
|||
} |
|||
|
|||
//When ball falls mark agent as done and give a negative penalty |
|||
if ((ball.transform.position.y - gameObject.transform.position.y) < -2f || |
|||
Mathf.Abs(ball.transform.position.x - gameObject.transform.position.x) > 3f || |
|||
Mathf.Abs(ball.transform.position.z - gameObject.transform.position.z) > 3f) |
|||
{ |
|||
done = true; |
|||
reward = -1f; |
|||
} |
|||
|
|||
The `Ball3DAgent` also assigns a negative penalty when the ball falls off the platform. |
|||
|
|||
## Agent Properties |
|||
|
|||
 |
|||
|
|||
* `Brain` - The brain to register this agent to. Can be dragged into the inspector using the Editor. |
|||
* `Observations` - A list of `Cameras` which will be used to generate observations. |
|||
* `Max Step` - The per-agent maximum number of steps. Once this number is reached, the agent will be reset if `Reset On Done` is checked. |
|||
* `Reset On Done` - Whether the agent's `AgentReset()` function should be called when the agent reaches its `Max Step` count or is marked as done in code. |
|||
|
|||
## Instantiating an Agent at Runtime |
|||
|
|||
To add an Agent to an environment at runtime, use the Unity `GameObject.Instantiate()` function. It is typically easiest to instantiate an agent from a [Prefab](https://docs.unity3d.com/Manual/Prefabs.html) (otherwise, you have to instantiate every GameObject and Component that make up your agent individually). In addition, you must assign a Brain instance to the new Agent and initialize it by calling its `AgentReset()` method. For example, the following function creates a new agent given a Prefab, Brain instance, location, and orientation: |
|||
|
|||
private void CreateAgent(GameObject agentPrefab, Brain brain, Vector3 position, Quaternion orientation) |
|||
{ |
|||
GameObject agentObj = Instantiate(agentPrefab, position, orientation); |
|||
Agent agent = agentObj.GetComponent<Agent>(); |
|||
agent.GiveBrain(brain); |
|||
agent.AgentReset(); |
|||
} |
|||
|
|||
## Destroying an Agent |
|||
|
|||
Before destroying an Agent Gameobject, you must mark it as done (and wait for the next step in the simulation) so that the Brain knows that this agent is no longer active. Thus, the best place to destroy an agent is in the `Agent.AgentOnDone()` function: |
|||
|
|||
```csharp |
|||
public override void AgentOnDone() |
|||
{ |
|||
Destroy(gameObject); |
|||
} |
|||
``` |
|||
|
|||
Note that in order for `AgentOnDone()` to be called, the agent's `ResetOnDone` property must be false. You can set `ResetOnDone` on the agent's Inspector or in code. |
|||
|
|||
# Brains |
|||
|
|||
The Brain encapsulates the decision making process. Brain objects must be children of the Academy in the Unity scene hierarchy. Every Agent must be assigned a Brain, but you can use the same Brain with more than one Agent. |
|||
|
|||
Use the Brain class directly, rather than a subclass. Brain behavior is determined by the brain type. During training, set your agent's brain type to **External**. To use the trained model, import the model file into the Unity project and change the brain type to **Internal**. You can extend the CoreBrain class to create different brain types if the four built-in types don't do what you need. |
|||
|
|||
The Brain class has several important properties that you can set using the Inspector window. These properties must be appropriate for the agents using the brain. For example, the `State Size` property must match the length of the feature vector created by an agent exactly. See [Agents](Learning-Environment-Design-Agents.md) for information about creating agents and setting up a Brain instance correctly. |
|||
|
|||
## Brain Properties |
|||
|
|||
 |
|||
|
|||
* `Brain Parameters` - Define state, observation, and action spaces for the Brain. |
|||
* `State Size` - Length of state vector for brain (In _Continuous_ state space). Or number of possible |
|||
values (in _Discrete_ state space). |
|||
* `Action Size` - Length of action vector for brain (In _Continuous_ state space). Or number of possible |
|||
values (in _Discrete_ action space). |
|||
* `Memory Size` - Length of memory vector for brain. Used with Recurrent networks and frame-stacking CNNs. |
|||
* `Camera Resolution` - Describes height, width, and whether to greyscale visual observations for the Brain. |
|||
* `Action Descriptions` - A list of strings used to name the available actions for the Brain. |
|||
* `State Space Type` - Corresponds to whether state vector contains a single integer (Discrete) or a series of real-valued floats (Continuous). |
|||
* `Action Space Type` - Corresponds to whether action vector contains a single integer (Discrete) or a series of real-valued floats (Continuous). |
|||
* `Type of Brain` - Describes how the Brain will decide actions. |
|||
* `External` - Actions are decided using Python API. |
|||
* `Internal` - Actions are decided using internal TensorFlowSharp model. |
|||
* `Player` - Actions are decided using Player input mappings. |
|||
* `Heuristic` - Actions are decided using custom `Decision` script, which should be attached to the Brain game object. |
|||
|
|||
### Internal Brain |
|||
|
|||
 |
|||
|
|||
* `Graph Model` : This must be the `bytes` file corresponding to the pretrained Tensorflow graph. (You must first drag this file into your Resources folder and then from the Resources folder into the inspector) |
|||
* `Graph Scope` : If you set a scope while training your TensorFlow model, all your placeholder name will have a prefix. You must specify that prefix here. |
|||
* `Batch Size Node Name` : If the batch size is one of the inputs of your graph, you must specify the name if the placeholder here. The brain will make the batch size equal to the number of agents connected to the brain automatically. |
|||
* `State Node Name` : If your graph uses the state as an input, you must specify the name if the placeholder here. |
|||
* `Recurrent Input Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the input placeholder here. |
|||
* `Recurrent Output Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the output placeholder here. |
|||
* `Observation Placeholder Name` : If your graph uses observations as input, you must specify it here. Note that the number of observations is equal to the length of `Camera Resolutions` in the brain parameters. |
|||
* `Action Node Name` : Specify the name of the placeholder corresponding to the actions of the brain in your graph. If the action space type is continuous, the output must be a one dimensional tensor of float of length `Action Space Size`, if the action space type is discrete, the output must be a one dimensional tensor of int of length 1. |
|||
* `Graph Placeholder` : If your graph takes additional inputs that are fixed (example: noise level) you can specify them here. Note that in your graph, these must correspond to one dimensional tensors of int or float of size 1. |
|||
* `Name` : Corresponds to the name of the placeholdder. |
|||
* `Value Type` : Either Integer or Floating Point. |
|||
* `Min Value` and `Max Value` : Specify the range of the value here. The value will be sampled from the uniform distribution ranging from `Min Value` to `Max Value` inclusive. |
|||
|
|||
|
|||
### Player Brain |
|||
|
|||
 |
|||
|
|||
If the action space is discrete, you must map input keys to their corresponding integer values. If the action space is continuous, you must map input keys to their corresponding indices and float values. |
|||
|
|||
|
|||
# Reinforcement Learning in Unity |
|||
|
|||
Reinforcement learning is an artificial intelligence technique that trains _agents_ to perform tasks by rewarding desirable behavior. During reinforcement learning, an agent explores its environment, observes the state of things, and, based on those observations, takes an action. If the action leads to a better state, the agent receives a positive reward. If it leads to a less desirable state, then the agent receives no reward or a negative reward (punishment). As the agent learns during training, it optimizes its decision making so that it receives the maximum reward over time. |
|||
|
|||
ML-Agents uses a reinforcement learning technique called [Proximal Policy Optimization (PPO)](https://blog.openai.com/openai-baselines-ppo/). PPO uses a neural network to approximate the ideal function that maps an agent's observations to the best action an agent can take in a given state. The ML-Agents PPO algorithm is implemented in TensorFlow and runs in a separate Python process (communicating with the running Unity application over a socket). |
|||
|
|||
**Note:** if you aren't studying machine and reinforcement learning as a subject and just want to train agents to accomplish tasks, you can treat PPO training as a _black box_. There are a few training-related parameters to adjust inside Unity as well as on the Python training side, but you do not need in-depth knowledge of the algorithm itself to successfully create and train agents. Step-by-step procedures for running the training process are provided in the [Training section](Training-ML-Agents.md). |
|||
|
|||
## The Simulation and Training Process |
|||
|
|||
Training and simulation proceed in steps orchestrated by the ML-Agents Academy class. The Academy works with Agent and Brain objects in the scene to step through the simulation. When either the Academy has reached its maximum number of steps or all agents in the scene are _done_, one training episode is finished. |
|||
|
|||
During training, the external Python PPO process communicates with the Academy to run a series of episodes while it collects data and optimizes its neural network model. The type of Brain assigned to an agent determines whether it participates in training or not. The **External** brain communicates with the external process to train the TensorFlow model. When training is completed successfully, you can add the trained model file to your Unity project for use with an **Internal** brain. |
|||
|
|||
The ML-Agents Academy class orchestrates the agent simulation loop as follows: |
|||
|
|||
1. Calls your Academy subclass's `AcademyReset()` function. |
|||
2. Calls the `AgentReset()` function for each agent in the scene. |
|||
3. Calls the `CollectState()` function for each agent in the scene. |
|||
4. Uses each agent's Brain class to decide on the agent's next action. |
|||
5. Calls your subclass's `AcademyStep()` function. |
|||
6. Calls the `AgentStep()` function for each agent in the scene, passing in the action chosen by the agent's brain. (This function is not called if the agent is done.) |
|||
7. Calls the agent's `AgentOnDone()` function if the agent has reached its `Max Step` count or has otherwise marked itself as `done`. Optionally, you can set an agent to restart if it finishes before the end of an episode. In this case, the Academy calls the `AgentReset()` function. |
|||
8. When the Academy reaches its own `Max Step` count, it starts the next episode again by calling your Academy subclass's `AcademyReset()` function. |
|||
|
|||
To create a training environment, extend the Academy and Agent classes to implement the above methods. The `Agent.CollectState()` and `Agent.AgentStep()` functions are required; the other methods are optional — whether you need to implement them or not depends on your specific scenario. |
|||
|
|||
**Note:** The API used by the Python PPO training process to communicate with and control the Academy during training can be used for other purposes as well. For example, you could use the API to use Unity as the simulation engine for your own machine learning algorithms. See [External ML API](Python-API.md) for more information. |
|||
|
|||
## Organizing the Unity Scene |
|||
|
|||
To train and use ML-Agents in a Unity scene, the scene must contain a single Academy subclass along with as many Brain objects and Agent subclasses as you need. Any Brain instances in the scene must be attached to GameObjects that are children of the Academy in the Unity Scene Hierarchy. Agent instances should be attached to the GameObject representing that agent. |
|||
|
|||
[Screenshot of scene hierarchy] |
|||
|
|||
You must assign a brain to every agent, but you can share brains between multiple agents. Each agent will make its own observations and act independently, but will use the same decision-making logic and, for **Internal** brains, the same trained TensorFlow model. |
|||
|
|||
### Academy |
|||
|
|||
The Academy object orchestrates agents and their decision making processes. Only place a single Academy object in a scene. |
|||
|
|||
You must create a subclass of the Academy class (since the base class is abstract). When you create your Academy subclass, you can implement the following methods (all are optional): |
|||
|
|||
* `InitializeAcademy()` — Prepare the environment the first time it launches. |
|||
* `AcademyReset()` — Prepare the environment and agents for the next training episode. Use this function to place and initialize entities in the scene as necessary. |
|||
* `AcademyStep()` — Prepare the environment for the next simulation step. The base Academy class calls this function before calling any `AgentStep()` methods for the current step. You can use this function to update other objects in the scene before the agents take their actions. Note that the agents have already collected their observations and chosen an action before the Academy invokes this method. |
|||
|
|||
The base Academy classes also defines several important properties that you can set in the Unity Editor Inspector. For training, the most important of these properties is `Max Steps`, which determines how long each training episode lasts. Once the Academy's step counter reaches this value, it calls the `AcademyReset()` function to start the next episode. |
|||
|
|||
See [Academy](Learning-Environment-Design-Academy.md) for a complete list of the Academy properties and their uses. |
|||
|
|||
### Brain |
|||
|
|||
The Brain encapsulates the decision making process. Brain objects must be children of the Academy in the Unity scene hierarchy. Every Agent must be assigned a Brain, but you can use the same Brain with more than one Agent. |
|||
|
|||
Use the Brain class directly, rather than a subclass. Brain behavior is determined by the brain type. During training, set your agent's brain type to **External**. To use the trained model, import the model file into the Unity project and change the brain type to **Internal**. See [Brain topic](Learning-Environment-Design-Brains.md) for details on using the different types of brains. You can extend the CoreBrain class to create different brain types if the four built-in types don't do what you need. |
|||
|
|||
The Brain class has several important properties that you can set using the Inspector window. These properties must be appropriate for the agents using the brain. For example, the `State Size` property must match the length of the feature vector created by an agent exactly. See [Agent topic]() for information about creating agents and setting up a Brain instance correctly. |
|||
|
|||
See [Brains](Learning-Environment-Design-Brains.md) for a complete list of the Brain properties. |
|||
|
|||
### Agent |
|||
|
|||
The Agent class represents an actor in the scene that collects observations and carries out actions. The Agent class is typically attached to the GameObject in the scene that otherwise represents the actor — for example, to a player object in a football game or a car object in a vehicle simulation. Every Agent must be assigned a Brain. |
|||
|
|||
To create an agent, extend the Agent class and implement the essential `CollectState()` and `AgentStep()` methods: |
|||
|
|||
* `CollectState()` — Collects the agent's observation of its environment. |
|||
* `AgentStep()` — Carries out the action chosen by the agent's brain and assigns a reward to the current state. |
|||
|
|||
Your implementations of these functions determine how the properties of the Brain assigned to this agent must be set. |
|||
|
|||
You must also determine how an Agent finishes its task or times out. You can manually set an agent to done in your `AgentStep()` function when the agent has finished (or irrevocably failed) its task. You can also set the agent's `Max Steps` property to a positive value and the agent will consider itself done after it has taken that many steps. When the Academy reaches its own `Max Steps` count, it starts the next episode. If you set an agent's RestOnDone property to true, then the agent can attempt its task several times in one episode. (Use the `Agent.AgentReset()` function to prepare the agent to start again.) |
|||
|
|||
See [Agents](Learning-Environment-Design-Agents.md) for detailed information about programing your own agents. |
|||
|
|||
## Environments |
|||
|
|||
An _environment_ in ML-Agents can be any scene built in Unity. The Unity scene provides the environment in which agents observe, act, and learn. How you set up the Unity scene to serve as a learning environment really depends on your goal. You may be trying to solve a specific reinforcement learning problem of limited scope, in which case you can use the same scene for both training and for testing trained agents. Or, you may be training agents to operate in a complex game or simulation. In this case, it might be more efficient and practical to create a purpose-built training scene. |
|||
|
|||
Both training and testing (or normal game) scenes must contain an Academy object to control the agent decision making process. The Academy defines several properties that can be set differently for a training scene versus a regular scene. The Academy's **Configuration** properties control rendering and time scale. You can set the **Training Configuration** to minimize the time Unity spends rendering graphics in order to speed up training. You may need to adjust the other functional, Academy settings as well. For example, `Max Steps` should be as short as possible for training — just long enough for the agent to accomplish its task, with some extra time for "wandering" while it learns. In regular scenes, you often do not want the Academy to reset the scene at all; if so, `Max Steps` should be set to zero. |
|||
|
|||
When you create a training environment in Unity, you must set up the scene so that it can be controlled by the external training process. Considerations include: |
|||
|
|||
* The training scene must start automatically when your Unity application is launched by the training process. |
|||
* The scene must include at least one **External** brain. |
|||
* The Academy must reset the scene to a valid starting point for each episode of training. |
|||
* A training episode must have a definite end — either using `Max Steps` or by each agent setting itself to `done`. |
|||
|
|||
|
|||
# Example Learning Environments |
|||
|
|||
Unity ML-Agents contains an expanding set of example environments which |
|||
demonstrate various features of the platform. Environments are located in |
|||
`unity-environment/Assets/ML-Agents/Examples` and summarised below. |
|||
Additionally, our |
|||
[first ML Challenge](https://connect.unity.com/challenges/ml-agents-1) |
|||
contains environments created by the community. |
|||
|
|||
This page only overviews the example environments we provide. To learn more |
|||
on how to design and build your own environments see our |
|||
[Making a new Learning Environment](Learning-Environment-Create-New.md) |
|||
page. |
|||
|
|||
If you would like to contribute environments, please see our |
|||
[contribution guidelines](Contribution-Guidelines.md) page. |
|||
|
|||
## Basic |
|||
|
|||
 |
|||
|
|||
* Set-up: A linear movement task where the agent must move left or right to rewarding states. |
|||
* Goal: Move to the most reward state. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* +0.1 for arriving at suboptimal state. |
|||
* +1.0 for arriving at optimal state. |
|||
* Brains: One brain with the following observation/action space. |
|||
* State space: (Discrete) One variable corresponding to current state. |
|||
* Action space: (Discrete) Two possible actions (Move left, move right). |
|||
* Visual Observations: 0 |
|||
* Reset Parameters: None |
|||
|
|||
## 3DBall |
|||
|
|||
 |
|||
|
|||
* Set-up: A balance-ball task, where the agent controls the platform. |
|||
* Goal: The agent must balance the platform in order to keep the ball on it for as long as possible. |
|||
* Agents: The environment contains 12 agents of the same kind, all linked to a single brain. |
|||
* Agent Reward Function: |
|||
* +0.1 for every step the ball remains on the platform. |
|||
* -1.0 if the ball falls from the platform. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: (Continuous) 8 variables corresponding to rotation of platform, and position, rotation, and velocity of ball. |
|||
* Vector Observation space (Hard Version): (Continuous) 5 variables corresponding to rotation of platform and position and rotation of ball. |
|||
* Action space: (Continuous) Size of 2, with one value corresponding to X-rotation, and the other to Z-rotation. |
|||
* Visual Observations: 0 |
|||
* Reset Parameters: None |
|||
|
|||
## GridWorld |
|||
|
|||
 |
|||
|
|||
* Set-up: A version of the classic grid-world task. Scene contains agent, goal, and obstacles. |
|||
* Goal: The agent must navigate the grid to the goal while avoiding the obstacles. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* -0.01 for every step. |
|||
* +1.0 if the agent navigates to the goal position of the grid (episode ends). |
|||
* -1.0 if the agent navigates to an obstacle (episode ends). |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: None |
|||
* Action space: (Discrete) Size of 4, corresponding to movement in cardinal directions. |
|||
* Visual Observations: One corresponding to top-down view of GridWorld. |
|||
* Reset Parameters: Three, corresponding to grid size, number of obstacles, and number of goals. |
|||
|
|||
|
|||
## Tennis |
|||
|
|||
 |
|||
|
|||
* Set-up: Two-player game where agents control rackets to bounce ball over a net. |
|||
* Goal: The agents must bounce ball between one another while not dropping or sending ball out of bounds. |
|||
* Agents: The environment contains two agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +0.1 To agent when hitting ball over net. |
|||
* -0.1 To agent who let ball hit their ground, or hit ball out of bounds. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: (Continuous) 8 variables corresponding to position and velocity of ball and racket. |
|||
* Action space: (Continuous) Size of 2, corresponding to movement toward net or away from net, and jumping. |
|||
* Visual Observations: None |
|||
* Reset Parameters: One, corresponding to size of ball. |
|||
|
|||
## Area |
|||
|
|||
### Push Area |
|||
|
|||
 |
|||
|
|||
* Set-up: A platforming environment where the agent can push a block around. |
|||
* Goal: The agent must push the block to the goal. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* -0.01 for every step. |
|||
* +1.0 if the block touches the goal. |
|||
* -1.0 if the agent falls off the platform. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: (Continuous) 15 variables corresponding to position and velocities of agent, block, and goal. |
|||
* Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement. |
|||
* Visual Observations: None. |
|||
* Reset Parameters: One, corresponding to number of steps in training. Used to adjust size of elements for Curriculum Learning. |
|||
|
|||
### Wall Area |
|||
|
|||
 |
|||
|
|||
* Set-up: A platforming environment where the agent can jump over a wall. |
|||
* Goal: The agent must use the block to scale the wall and reach the goal. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* -0.01 for every step. |
|||
* +1.0 if the agent touches the goal. |
|||
* -1.0 if the agent falls off the platform. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: (Continuous) 16 variables corresponding to position and velocities of agent, block, and goal, plus the height of the wall. |
|||
* Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement. |
|||
* Visual Observations: None. |
|||
* Reset Parameters: One, corresponding to number of steps in training. Used to adjust size of the wall for Curriculum Learning. |
|||
|
|||
## Reacher |
|||
|
|||
 |
|||
|
|||
* Set-up: Double-jointed arm which can move to target locations. |
|||
* Goal: The agents must move it's hand to the goal location, and keep it there. |
|||
* Agents: The environment contains 32 agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +0.1 Each step agent's hand is in goal location. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: (Continuous) 26 variables corresponding to position, rotation, velocity, and angular velocities of the two arm rigidbodies. |
|||
* Action space: (Continuous) Size of 4, corresponding to torque applicable to two joints. |
|||
* Visual Observations: None |
|||
* Reset Parameters: Two, corresponding to goal size, and goal movement speed. |
|||
|
|||
## Crawler |
|||
|
|||
 |
|||
|
|||
* Set-up: A creature with 4 arms and 4 forearms. |
|||
* Goal: The agents must move its body along the x axis without falling. |
|||
* Agents: The environment contains 3 agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +1 times velocity in the x direction |
|||
* -1 for falling. |
|||
* -0.01 times the action squared |
|||
* -0.05 times y position change |
|||
* -0.05 times velocity in the z direction |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: (Continuous) 117 variables corresponding to position, rotation, velocity, and angular velocities of each limb plus the acceleration and angular acceleration of the body. |
|||
* Action space: (Continuous) Size of 12, corresponding to torque applicable to 12 joints. |
|||
* Visual Observations: None |
|||
* Reset Parameters: None |
|||
|
|||
## Banana Collector |
|||
|
|||
 |
|||
|
|||
* Set-up: A multi-agent environment where agents compete to collect bananas. |
|||
* Goal: The agents must learn to move to as many yellow bananas as possible while avoiding red bananas. |
|||
* Agents: The environment contains 10 agents linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +1 for interaction with yellow banana |
|||
* -1 for interaction with red banana. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Vector Observation space: (Continuous) 51 corresponding to velocity of agent, plus ray-based perception of objects around agent's forward direction. |
|||
* Action space: (Continuous) Size of 3, corresponding to forward movement, y-axis rotation, and whether to use laser to disable other agents. |
|||
* Visual Observations (Optional): First-person view for each agent. |
|||
* Reset Parameters: None |
|||
|
|||
## Hallway |
|||
|
|||
 |
|||
|
|||
* Set-up: Environment where the agent needs to find information in a room, remeber it, and use it to move to the correct goal. |
|||
* Goal: Move to the goal which corresponds to the color of the block in the room. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +1 For moving to correct goal. |
|||
* -0.1 For moving to incorrect goal. |
|||
* -0.0003 Existential penalty. |
|||
* Brains: One brain with the following observation/action space: |
|||
* Vector Observation space: (Continuous) 30 corresponding to local ray-casts detecting objects, goals, and walls. |
|||
* Action space: (Discrete) 4 corresponding to agent rotation and forward/backward movement. |
|||
* Visual Observations (Optional): First-person view for the agent. |
|||
* Reset Parameters: None |
|||
|
|||
# ML-Agents Overview |
|||
|
|||
**Unity Machine Learning Agents** (ML-Agents) is an open-source Unity plugin |
|||
that enables games and simulations to serve as environments for training |
|||
intelligent agents. Agents can be trained using reinforcement learning, |
|||
imitation learning, neuroevolution, or other machine learning methods through |
|||
a simple-to-use Python API. We also provide implementations (based on |
|||
TensorFlow) of state-of-the-art algorithms to enable game developers |
|||
and hobbyists to easily train intelligent agents for 2D, 3D and VR/AR games. |
|||
These trained agents can be used for multiple purposes, including |
|||
controlling NPC behavior (in a variety of settings such as multi-agent and |
|||
adversarial), automated testing of game builds and evaluating different game |
|||
design decisions pre-release. ML-Agents is mutually beneficial for both game |
|||
developers and AI researchers as it provides a central platform where advances |
|||
in AI can be evaluated on Unity’s rich environments and then made accessible |
|||
to the wider research and game developer communities. |
|||
|
|||
Depending on your background (i.e. researcher, game developer, hobbyist), |
|||
you may have very different questions on your mind at the moment. |
|||
To make your transition to ML-Agents easier, we provide several background |
|||
pages that include overviews and helpful resources on the |
|||
[Unity Engine](Background-Unity.md), |
|||
[machine learning](Background-Machine-Learning.md) and |
|||
[TensorFlow](Background-TensorFlow.md). |
|||
|
|||
The remainder of this page contains a deep dive into ML-Agents, its key |
|||
components, different training modes and scenarios. By the end of it, you |
|||
should have a good sense of _what_ ML-Agents allows you to do. The subsequent |
|||
documentation pages provide examples of _how_ to use ML-Agents. |
|||
|
|||
## Running Example: Training NPC Behaviors |
|||
|
|||
To help explain the material and terminology in this page, we'll use a |
|||
hypothetical, running example throughout. We will explore the |
|||
problem of training the behavior of a non-playable character (NPC) in a game. |
|||
(An NPC is a game character that is never controlled by a human player and |
|||
its behavior is pre-defined by the game developer.) More specifically, let's |
|||
assume we're building a multi-player, war-themed game in which players control |
|||
the soldiers. In this game, we have a single NPC who serves as a medic, finding |
|||
and reviving wounded players. Lastly, let us assume that there |
|||
are two teams, each with five players and one NPC medic. |
|||
|
|||
The behavior of a medic is quite complex. It first needs to avoid getting |
|||
injured, which requires detecting when it is in danger and moving to a safe |
|||
location. Second, it needs to be aware of which of its team members are |
|||
injured and require assistance. In the case of multiple injuries, it needs to |
|||
assess the degree of injury and decide who to help first. Lastly, a good |
|||
medic will always place itself in a position where it can quickly help its |
|||
team members. Factoring in all of these traits means that at every instance, |
|||
the medic needs to measure several attributes of the environment (e.g. |
|||
position of team members, position of enemies, which of its team members are |
|||
injured and to what degree) and then decide on an action (e.g. hide from enemy |
|||
fire, move to help one of its members). Given the large number of settings of |
|||
the environment and the large number of actions that the medic can take, |
|||
defining and implementing such complex behaviors by hand is challenging and |
|||
prone to errors. |
|||
|
|||
With ML-Agents, it is possible to _train_ the behaviors of such NPCs |
|||
(called **agents**) using a variety of methods. The basic idea is quite simple. |
|||
We need to define three entities at every moment of the game |
|||
(called **environment**): |
|||
- **Observations** - what the medic perceives about the environment. |
|||
Observations can be numeric and/or visual. Numeric observations measure |
|||
attributes of the environment from the point of view of the agent. For |
|||
our medic this would be attributes of the battlefield that are visible to it. |
|||
Observations can either be _discrete_ or _continuous_ depending on the complexity |
|||
of the game and agent. For most interesting environments, an agent will require |
|||
several continuous numeric observations, while for simple environments with |
|||
a small number of unique configurations, a discrete observation will suffice. |
|||
Visual observations, on the other hand, are images generated from the cameras |
|||
attached to the agent and represent what the agent is seeing at that point |
|||
in time. It is common to confuse an agent's observation with the environment |
|||
(or game) **state**. The environment state represents information about the |
|||
entire scene containing all the game characters. The agents observation, |
|||
however, only contains information that the agent is aware of and is typically |
|||
a subset of the environment state. For example, the medic observation cannot |
|||
include information about an enemy in hiding that the medic is unaware of. |
|||
- **Actions** - what actions the medic can take. Similar |
|||
to observations, actions can either be continuous or discrete depending |
|||
on the complexity of the environment and agent. In the case of the medic, |
|||
if the environment is a simple grid world where only their location matters, |
|||
then a discrete action taking on one of four values (north, south, east, west) |
|||
suffices. However, if the environment is more complex and the medic can move |
|||
freely then using two continuous actions (one for direction and another |
|||
for speed) is more appropriate. |
|||
- **Reward signals** - a scalar value indicating how well the medic is doing. |
|||
Note that the reward signal need not be |
|||
provided at every moment, but only when the medic performs an action that is |
|||
good or bad. For example, it can receive a large negative reward if it dies, |
|||
a modest positive reward whenever it revives a wounded team member, and a |
|||
modest negative reward when a wounded team member dies due to lack of |
|||
assistance. Note that the reward signal is how the objectives of the task |
|||
are communicated to the agent, so they need to be set up in a manner where |
|||
maximizing reward generates the desired optimal behavior. |
|||
|
|||
After defining these three entities (called a **reinforcement learning task**), |
|||
we can now _train_ the medic's behavior. This is achieved by simulating the |
|||
environment for many trials where the medic, over time, learns what is the |
|||
optimal action to take for every observation it measures by maximizing |
|||
its future reward. The key is that by learning the actions that maximize its |
|||
reward, the medic is learning the behaviors that make it a good medic (i.e. |
|||
one who saves the most number of lives). In **reinforcement learning** |
|||
terminology, the behavior that is learned is called a **policy**, which is |
|||
essentially a (optimal) mapping from observations to actions. Note that |
|||
the process of learning a policy through running simulations is called the |
|||
**training phase**, while playing the game with an NPC that is using its |
|||
learned policy is called the **inference phase**. |
|||
|
|||
ML-Agents provides all the necessary tools for using Unity as the simulation |
|||
engine for learning the policies of different objects in a Unity environment. |
|||
In the next few sections, we discuss how ML-Agents achieves this and what |
|||
features it provides. |
|||
|
|||
## Key Components |
|||
|
|||
ML-Agents is a Unity plugin that contains three high-level components: |
|||
* **Learning Environment** - which contains the Unity scene and all the game |
|||
characters. |
|||
* **Python API** - which contains all the machine learning algorithms that are |
|||
used for training (learning a behavior or policy). Note that, unlike |
|||
the Learning Environment, the Python API is not part of Unity, but lives |
|||
outside and communicates with Unity through the External Communicator. |
|||
* **External Communicator** - which connects the Learning Environment |
|||
with the Python API. It lives within the Learning Environment. |
|||
|
|||
<p align="center"> |
|||
<img src="images/learning_environment_basic.png" |
|||
alt="Simplified ML-Agents Scene Block Diagram" |
|||
width="700" border="10" /> |
|||
</p> |
|||
|
|||
_Simplified block diagram of ML-Agents._ |
|||
|
|||
The Learning Environment contains three additional components that help |
|||
organize the Unity scene: |
|||
* **Agents** - which is attached to each agent and handles generating its |
|||
observations, performing the actions it receives and assigning a reward |
|||
(positive / negative) when appropriate. Each Agent is linked to exactly one |
|||
Brain. |
|||
* **Brains** - which encapsulates the logic for making decisions for the Agent. |
|||
In essence, the Brain is what holds on to the policy for each agent and |
|||
determines which actions the agent should take at each instance. More |
|||
specifically, it is the component that receives the observations and rewards |
|||
from the Agent and returns an action. |
|||
* **Academy** - which orchestrates the observation and decision making process. |
|||
Within the Academy, several environment-wide parameters such as the rendering |
|||
quality and the speed at which the environment is run can be specified. The |
|||
External Communicator lives within the Academy. |
|||
|
|||
Every Learning Environment will always have one global Academy and one Agent |
|||
for every character in the scene. While each Agent must be linked to a Brain, |
|||
it is possible for Agent that have similar observations and actions to be |
|||
linked to the same Brain. In our sample game, we have two teams each with |
|||
their own medic. Thus we will have two Agents in our Learning Environment, |
|||
one for each medic, but both of these medics can be linked to the same Brain. |
|||
Note that these two medics are linked to the same Brain because their _space_ |
|||
of observations and actions are similar. This does not mean that at each |
|||
instance they will have identical observation and action _values_. In other |
|||
words, the Brain defines the space of all possible observations and actions, |
|||
while the Agents connected to it (in this case the medics) can each have |
|||
their own, unique observation and action values. If we expanded our game |
|||
to include tank driver NPCs, then the Agent attached to those characters |
|||
cannot share a Brain with the Agent linked to the medics. |
|||
|
|||
<p align="center"> |
|||
<img src="images/learning_environment_example.png" |
|||
alt="Example ML-Agents Scene Block Diagram" |
|||
border="10" /> |
|||
</p> |
|||
|
|||
_Example block diagram of ML-Agents for our sample game._ |
|||
|
|||
We have yet to discuss how ML-Agents trains behaviors, and what role the |
|||
Python API and External Communicator play. Before we dive into those details, |
|||
let's summarize the earlier components. Each character is attached to an Agent, |
|||
and each Agent is linked to a Brain. The Brain receives observations and |
|||
rewards from the Agent and returns actions. The Academy ensures that all the |
|||
Agents and Brains are in sync in addition to controlling environment-wide |
|||
settings. So how does the Brain control what the Agent does? |
|||
|
|||
In practice, we have four different types of Brains, which enable a wide |
|||
range of training and inference scenarios: |
|||
* **External** - where decisions are made using the Python API. Here, the |
|||
observations and rewards collected by the Brain are forwarded to the Python |
|||
API through the External Communicator. The Python API then returns the |
|||
corresponding action that needs to be taken by the Agent. |
|||
* **Internal** - where decisions are made using an embedded TensorFlow model. |
|||
The embedded TensorFlow model represents a learned policy and the Brain |
|||
directly uses this model to determine the action for each Agent. |
|||
* **Player** - where decisions are made using real input from a keyboard or |
|||
controller. Here, a human player is controlling the Agent and the observations |
|||
and rewards collected by the Brain are not used to control the Agent. |
|||
* **Heuristic** - where decisions are made using hard-coded behavior. This |
|||
resembles how most character behaviors are currently defined and can be |
|||
helpful for debugging or comparing how an Agent with hard-coded rules compares |
|||
to an Agent whose behavior has been trained. In our example, once we have |
|||
trained a Brain for the medics we could assign a medic on one team to the |
|||
trained Brain and assign the medic on the other team a Heuristic Brain |
|||
with hard-coded behaviors. We can then evaluate which medic is more effective. |
|||
|
|||
As currently described, it may seem that the External Communicator |
|||
and Python API are only leveraged by the External Brain. This is not true. |
|||
It is possible to configure the Internal, Player and Heuristic Brains to |
|||
also send the observations, rewards and actions to the Python API through |
|||
the External Communicator (a feature called _broadcasting_). As we will see |
|||
shortly, this enables additional training modes. |
|||
|
|||
<p align="center"> |
|||
<img src="images/learning_environment.png" |
|||
alt="ML-Agents Scene Block Diagram" |
|||
border="10" /> |
|||
</p> |
|||
|
|||
_An example of how a scene containing multiple Agents and Brains might be |
|||
configured._ |
|||
|
|||
ML-Agents includes several |
|||
[example environments](Learning-Environment-Examples.md) and a |
|||
[Making a new Learning Environment](Learning-Environment-Create-New.md) |
|||
tutorial to help you get started. |
|||
|
|||
## Training Modes |
|||
|
|||
Given the flexibility of ML-Agents, there are a few ways in which training and |
|||
inference can proceed. |
|||
|
|||
### Built-in Training and Inference |
|||
|
|||
As mentioned previously, ML-Agents ships with several implementations of |
|||
state-of-the-art algorithms for training intelligent agents. In this mode, the |
|||
Brain type is set to External during training and Internal during inference. |
|||
More specifically, during training, all the medics in the scene send their |
|||
observations to the Python API through the External Communicator (this is the |
|||
behavior with an External Brain). The Python API processes these observations |
|||
and sends back actions for each medic to take. During training these actions |
|||
are mostly exploratory to help the Python API learn the best policy for each |
|||
medic. Once training concludes, the learned policy for each medic can be |
|||
exported. Given that all our implementations are based on TensorFlow, the |
|||
learned policy is just a TensorFlow model file. Then during the inference |
|||
phase, we switch the Brain type to Internal and include the TensorFlow model |
|||
generated from the training phase. Now during the inference phase, the medics |
|||
still continue to generate their observations, but instead of being sent to |
|||
the Python API, they will be fed into their (internal, embedded) model to |
|||
generate the _optimal_ action for each medic to take at every point in time. |
|||
|
|||
To summarize: our built-in implementations are based on TensorFlow, thus, |
|||
during training the Python API uses the observations it receives to learn |
|||
a TensorFlow model. This model is then embedded within the Internal Brain |
|||
during inference to generate the optimal actions for all Agents linked to |
|||
that Brain. **Note that our Internal Brain is currently experimental as it |
|||
is limited to TensorFlow models and leverages the third-party |
|||
[TensorFlowSharp](https://github.com/migueldeicaza/TensorFlowSharp) |
|||
library.** |
|||
|
|||
The |
|||
[Getting Started with the 3D Balance Ball Example](Getting-Started-with-Balance-Ball.md) |
|||
tutorial covers this training mode with the Balance Ball sample environment. |
|||
|
|||
### Custom Training and Inference |
|||
|
|||
In the previous mode, the External Brain type was used for training |
|||
to generate a TensorFlow model that the Internal Brain type can understand |
|||
and use. However, any user of ML-Agents can leverage their own algorithms |
|||
for both training and inference. In this case, the Brain type would be set |
|||
to External for both training and inferences phases and the behaviors of |
|||
all the Agents in the scene will be controlled within Python. |
|||
|
|||
We do not currently have a tutorial highlighting this mode, but you can |
|||
learn more about the Python API [here](Python-API.md). |
|||
|
|||
### Curriculum Learning |
|||
|
|||
This mode is an extension of _Built-in Training and Inference_, and |
|||
is particularly helpful when training intricate behaviors for complex |
|||
environments. Curriculum learning is a way of training a machine learning |
|||
model where more difficult aspects of a problem are gradually introduced in |
|||
such a way that the model is always optimally challenged. This idea has been |
|||
around for a long time, and it is how we humans typically learn. If you |
|||
imagine any childhood primary school education, there is an ordering of |
|||
classes and topics. Arithmetic is taught before algebra, for example. |
|||
Likewise, algebra is taught before calculus. The skills and knowledge learned |
|||
in the earlier subjects provide a scaffolding for later lessons. The same |
|||
principle can be applied to machine learning, where training on easier tasks |
|||
can provide a scaffolding for harder tasks in the future. |
|||
|
|||
<p align="center"> |
|||
<img src="images/math.png" |
|||
alt="Example Math Cirriculum" |
|||
width="700" |
|||
border="10" /> |
|||
</p> |
|||
|
|||
_Example of a mathematics curriculum. Lessons progress from simpler topics to more |
|||
complex ones, with each building on the last._ |
|||
|
|||
When we think about how reinforcement learning actually works, the |
|||
learning signal is reward received occasionally throughout training. |
|||
The starting point when training an agent to accomplish this task will be a |
|||
random policy. That starting policy will have the agent running in circles, |
|||
and will likely never, or very rarely achieve the reward for complex |
|||
environments. Thus by simplifying the environment at the beginning of training, |
|||
we allow the agent to quickly update the random policy to a more meaningful |
|||
one that is successively improved as the environment gradually increases in |
|||
complexity. In our example, we can imagine first training the medic when each |
|||
team only contains one player, and then iteratively increasing the number of |
|||
players (i.e. the environment complexity). ML-Agents supports setting |
|||
custom environment parameters within the Academy. This allows |
|||
elements of the environment related to difficulty or complexity to be |
|||
dynamically adjusted based on training progress. |
|||
|
|||
The [Curriculum Learning](Training-Curriculum-Learning.md) |
|||
tutorial covers this training mode with the Wall Area sample environment. |
|||
|
|||
### Imitation Learning (coming soon) |
|||
|
|||
It is often more intuitive to simply demonstrate the behavior we |
|||
want an agent to perform, rather than attempting to have it learn via |
|||
trial-and-error methods. For example, instead of training the medic by |
|||
setting up its reward function, this mode allows providing real examples from |
|||
a game controller on how the medic should behave. More specifically, |
|||
in this mode, the Brain type during training is set to Player and all the |
|||
actions performed with the controller (in addition to the agent observations) |
|||
will be recorded and sent to the Python API. The imitation learning algorithm |
|||
will then use these pairs of observations and actions from the human player |
|||
to learn a policy. |
|||
|
|||
The [Imitation Learning](Training-Imitation-Learning.md) tutorial covers this training |
|||
mode with the **Anti-Graviator** sample environment. |
|||
|
|||
## Flexible Training Scenarios |
|||
|
|||
While the discussion so-far has mostly focused on training a single agent, with |
|||
ML-Agents, several training scenarios are possible. |
|||
We are excited to see what kinds of novel and fun environments the community |
|||
creates. For those new to training intelligent agents, below are a few examples |
|||
that can serve as inspiration: |
|||
* Single-Agent. A single Agent linked to a single Brain, with its own reward |
|||
signal. The traditional way of training an agent. An example is any |
|||
single-player game, such as Chicken. |
|||
[Video Link](https://www.youtube.com/watch?v=fiQsmdwEGT8&feature=youtu.be). |
|||
* Simultaneous Single-Agent. Multiple independent Agents with independent |
|||
reward signals linked to a single Brain. A parallelized version of the |
|||
traditional training scenario, which can speed-up and stabilize the training |
|||
process. Helpful when you have multiple versions of the same character in an |
|||
environment who should learn similar behaviors. An example might be training |
|||
a dozen robot-arms to each open a door simultaneously. |
|||
[Video Link](https://www.youtube.com/watch?v=fq0JBaiCYNA). |
|||
* Adversarial Self-Play. Two interacting Agents with inverse reward signals |
|||
linked to a single Brain. In two-player games, adversarial self-play can allow |
|||
an agent to become increasingly more skilled, while always having the perfectly |
|||
matched opponent: itself. This was the strategy employed when training AlphaGo, |
|||
and more recently used by OpenAI to train a human-beating 1-vs-1 Dota 2 agent. |
|||
* Cooperative Multi-Agent. Multiple interacting Agents with a shared reward |
|||
signal linked to either a single or multiple different Brains. In this |
|||
scenario, all agents must work together to accomplish a task that cannot be |
|||
done alone. Examples include environments where each agent only has access to |
|||
partial information, which needs to be shared in order to accomplish the task |
|||
or collaboratively solve a puzzle. |
|||
* Competitive Multi-Agent. Multiple interacting Agents with inverse reward |
|||
signals linked to either a single or multiple different Brains. In this |
|||
scenario, agents must compete with one another to either win a competition, |
|||
or obtain some limited set of resources. All team sports fall into this |
|||
scenario. |
|||
* Ecosystem. Multiple interacting Agents with independent reward signals |
|||
linked to either a single or multiple different Brains. This scenario can be |
|||
thought of as creating a small world in which animals with different goals all |
|||
interact, such as a savanna in which there might be zebras, elephants and |
|||
giraffes, or an autonomous driving simulation within an urban environment. |
|||
|
|||
## Additional Features |
|||
|
|||
Beyond the flexible training scenarios available, ML-Agents includes |
|||
additional features which improve the flexibility and interpretability of the |
|||
training process. |
|||
|
|||
* **Monitoring Agent’s Decision Making** - Since communication in ML-Agents |
|||
is a two-way street, we provide an agent Monitor class in Unity which can |
|||
display aspects of the trained agent, such as the agents perception on how |
|||
well it is doing (called **value estimates**) within the Unity environment |
|||
itself. By leveraging Unity as a visualization tool and providing these |
|||
outputs in real-time, researchers and developers can more easily debug an |
|||
agent’s behavior. You can learn more about using the Monitor class |
|||
[here](Feature-Monitor.md). |
|||
|
|||
* **Complex Visual Observations** - Unlike other platforms, where the agent’s |
|||
observation might be limited to a single vector or image, ML-Agents allows |
|||
multiple cameras to be used for observations per agent. This enables agents to |
|||
learn to integrate information from multiple visual streams. This can be |
|||
helpful in several scenarios such as training a self-driving car which requires |
|||
multiple cameras with different viewpoints, or a navigational agent which might |
|||
need to integrate aerial and first-person visuals. |
|||
|
|||
* **Broadcasting** - As discussed earlier, an External Brain sends the |
|||
observations for all its Agents to the Python API by default. This is helpful |
|||
for training or inference. Broadcasting is a feature which can be enabled |
|||
for the other three modes (Player, Internal, Heuristic) where the Agent |
|||
observations and actions are also sent to the Python API (despite the fact |
|||
that the Agent is **not** controlled by the Python API). This feature is |
|||
leveraged by Imitation Learning, where the observations and actions for a |
|||
Player Brain are used to learn the policies of an agent through demonstration. |
|||
However, this could also be helpful for the Heuristic and Internal Brains, |
|||
particularly when debugging agent behaviors. You can learn more about using |
|||
the broadcasting feature [here](Feature-Broadcasting.md). |
|||
|
|||
# Training with Curriculum Learning |
|||
|
|||
## Sample Environment |
|||
|
|||
Imagine a task in which an agent needs to scale a wall to arrive at a goal. The starting |
|||
point when training an agent to accomplish this task will be a random policy. That |
|||
starting policy will have the agent running in circles, and will likely never, or very |
|||
rarely scale the wall properly to the achieve the reward. If we start with a simpler |
|||
task, such as moving toward an unobstructed goal, then the agent can easily learn to |
|||
accomplish the task. From there, we can slowly add to the difficulty of the task by |
|||
increasing the size of the wall, until the agent can complete the initially |
|||
near-impossible task of scaling the wall. We are including just such an environment with |
|||
ML-Agents 0.2, called Wall Area. |
|||
|
|||
 |
|||
|
|||
_Demonstration of a curriculum training scenario in which a progressively taller wall |
|||
obstructs the path to the goal._ |
|||
|
|||
To see this in action, observe the two learning curves below. Each displays the reward |
|||
over time for an agent trained using PPO with the same set of training hyperparameters. |
|||
The difference is that the agent on the left was trained using the full-height wall |
|||
version of the task, and the right agent was trained using the curriculum version of |
|||
the task. As you can see, without using curriculum learning the agent has a lot of |
|||
difficulty. We think that by using well-crafted curricula, agents trained using |
|||
reinforcement learning will be able to accomplish tasks otherwise much more difficult. |
|||
|
|||
 |
|||
|
|||
## How-To |
|||
|
|||
So how does it work? In order to define a curriculum, the first step is to decide which |
|||
parameters of the environment will vary. In the case of the Wall Area environment, what |
|||
varies is the height of the wall. We can define this as a reset parameter in the Academy |
|||
object of our scene, and by doing so it becomes adjustable via the Python API. Rather |
|||
than adjusting it by hand, we then create a simple JSON file which describes the |
|||
structure of the curriculum. Within it we can set at what points in the training process |
|||
our wall height will change, either based on the percentage of training steps which have |
|||
taken place, or what the average reward the agent has received in the recent past is. |
|||
Once these are in place, we simply launch ppo.py using the `–curriculum-file` flag to |
|||
point to the JSON file, and PPO we will train using Curriculum Learning. Of course we can |
|||
then keep track of the current lesson and progress via TensorBoard. |
|||
|
|||
|
|||
```json |
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5], |
|||
"min_lesson_length" : 2, |
|||
"signal_smoothing" : true, |
|||
"parameters" : |
|||
{ |
|||
"min_wall_height" : [0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5], |
|||
"max_wall_height" : [1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0] |
|||
} |
|||
} |
|||
``` |
|||
|
|||
* `measure` - What to measure learning progress, and advancement in lessons by. |
|||
* `reward` - Uses a measure received reward. |
|||
* `progress` - Uses ratio of steps/max_steps. |
|||
* `thresholds` (float array) - Points in value of `measure` where lesson should be increased. |
|||
* `min_lesson_length` (int) - How many times the progress measure should be reported before |
|||
incrementing the lesson. |
|||
* `signal_smoothing` (true/false) - Whether to weight the current progress measure by previous values. |
|||
* If `true`, weighting will be 0.75 (new) 0.25 (old). |
|||
* `parameters` (dictionary of key:string, value:float array) - Corresponds to academy reset parameters to control. Length of each array |
|||
should be one greater than number of thresholds. |
|||
|
|||
# Imitation Learning |
|||
|
|||
This feature and its associated documentation are still in development. |
|||
|
|||
# Training ML-Agents |
|||
|
|||
This document is still to be written. When finished it will provide an overview of the training process. The main algorithm implemented currently is PPO, but there are various flavors including multi-agent training, curriculum training and imitation learning to consider. |
|||
|
|||
|
|||
# Training with Proximal Policy Optimization |
|||
|
|||
This document is still to be written. Refer to [Getting Started with the Balance Ball Environment](Getting-Started-with-Balance-Ball.md) for a walk-through of the PPO training process. |
|||
|
|||
## Best Practices when training with PPO |
|||
|
|||
The process of training a Reinforcement Learning model can often involve the need to tune the hyperparameters in order to achieve |
|||
a level of performance that is desirable. This guide contains some best practices for tuning the training process when the default |
|||
parameters don't seem to be giving the level of performance you would like. |
|||
|
|||
### Hyperparameters |
|||
|
|||
#### Batch Size |
|||
|
|||
`batch_size` corresponds to how many experiences are used for each gradient descent update. This should always be a fraction |
|||
of the `buffer_size`. If you are using a continuous action space, this value should be large (in 1000s). If you are using a discrete action space, this value should be smaller (in 10s). |
|||
|
|||
Typical Range (Continuous): `512` - `5120` |
|||
|
|||
Typical Range (Discrete): `32` - `512` |
|||
|
|||
|
|||
#### Beta (Used only in Discrete Control) |
|||
|
|||
`beta` corresponds to the strength of the entropy regularization, which makes the policy "more random." This ensures that discrete action space agents properly explore during training. Increasing this will ensure more random actions are taken. This should be adjusted such that the entropy (measurable from TensorBoard) slowly decreases alongside increases in reward. If entropy drops too quickly, increase `beta`. If entropy drops too slowly, decrease `beta`. |
|||
|
|||
Typical Range: `1e-4` - `1e-2` |
|||
|
|||
#### Buffer Size |
|||
|
|||
`buffer_size` corresponds to how many experiences should be collected before gradient descent is performed on them all. |
|||
This should be a multiple of `batch_size`. Typically larger buffer sizes correspond to more stable training updates. |
|||
|
|||
Typical Range: `2048` - `409600` |
|||
|
|||
#### Epsilon |
|||
|
|||
`epsilon` corresponds to the acceptable threshold of divergence between the old and new policies during gradient descent updating. Setting this value small will result in more stable updates, but will also slow the training process. |
|||
|
|||
Typical Range: `0.1` - `0.3` |
|||
|
|||
#### Hidden Units |
|||
|
|||
`hidden_units` correspond to how many units are in each fully connected layer of the neural network. For simple problems |
|||
where the correct action is a straightforward combination of the state inputs, this should be small. For problems where |
|||
the action is a very complex interaction between the state variables, this should be larger. |
|||
|
|||
Typical Range: `32` - `512` |
|||
|
|||
#### Learning Rate |
|||
|
|||
`learning_rate` corresponds to the strength of each gradient descent update step. This should typically be decreased if |
|||
training is unstable, and the reward does not consistently increase. |
|||
|
|||
Typical Range: `1e-5` - `1e-3` |
|||
|
|||
#### Number of Epochs |
|||
|
|||
`num_epoch` is the number of passes through the experience buffer during gradient descent. The larger the batch size, the |
|||
larger it is acceptable to make this. Decreasing this will ensure more stable updates, at the cost of slower learning. |
|||
|
|||
Typical Range: `3` - `10` |
|||
|
|||
#### Time Horizon |
|||
|
|||
`time_horizon` corresponds to how many steps of experience to collect per-agent before adding it to the experience buffer. |
|||
When this limit is reached before the end of an episode, a value estimate is used to predict the overall expected reward from the agent's current state. |
|||
As such, this parameter trades off between a less biased, but higher variance estimate (long time horizon) and more biased, but less varied estimate (short time horizon). |
|||
In cases where there are frequent rewards within an episode, or episodes are prohibitively large, a smaller number can be more ideal. |
|||
This number should be large enough to capture all the important behavior within a sequence of an agent's actions. |
|||
|
|||
Typical Range: `32` - `2048` |
|||
|
|||
#### Max Steps |
|||
|
|||
`max_steps` corresponds to how many steps of the simulation (multiplied by frame-skip) are run durring the training process. This value should be increased for more complex problems. |
|||
|
|||
Typical Range: `5e5 - 1e7` |
|||
|
|||
#### Normalize |
|||
|
|||
`normalize` corresponds to whether normalization is applied to the state inputs. This normalization is based on the running average and variance of the states. |
|||
Normalization can be helpful in cases with complex continuous control problems, but may be harmful with simpler discrete control problems. |
|||
|
|||
#### Number of Layers |
|||
|
|||
`num_layers` corresponds to how many hidden layers are present after the state input, or after the CNN encoding of the observation. For simple problems, |
|||
fewer layers are likely to train faster and more efficiently. More layers may be necessary for more complex control problems. |
|||
|
|||
Typical range: `1` - `3` |
|||
|
|||
### Training Statistics |
|||
|
|||
To view training statistics, use TensorBoard. For information on launching and using TensorBoard, see [here](./Getting-Started-with-Balance-Ball.md#observing-training-progress). |
|||
|
|||
#### Cumulative Reward |
|||
|
|||
The general trend in reward should consistently increase over time. Small ups and downs are to be expected. Depending on the complexity of the task, a significant increase in reward may not present itself until millions of steps into the training process. |
|||
|
|||
#### Entropy |
|||
|
|||
This corresponds to how random the decisions of a brain are. This should consistently decrease during training. If it decreases too soon or not at all, `beta` should be adjusted (when using discrete action space). |
|||
|
|||
#### Learning Rate |
|||
|
|||
This will decrease over time on a linear schedule. |
|||
|
|||
#### Policy Loss |
|||
|
|||
These values will oscillate with training. |
|||
|
|||
#### Value Estimate |
|||
|
|||
These values should increase with the reward. They corresponds to how much future reward the agent predicts itself receiving at any given point. |
|||
|
|||
#### Value Loss |
|||
|
|||
These values will increase as the reward increases, and should decrease when reward becomes stable. |
|||
|
|||
# Using TensorBoard to Observe Training |
|||
|
|||
This document is still to be written. It will discuss using TensorBoard and interpreting the TensorBoard charts. |
|||
|
|||
 |
|||
1001
docs/dox-ml-agents.conf
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
|
|||
# Doxygen files |
|||
|
|||
To generate the API reference as HTML files, run: |
|||
|
|||
doxygen ml-agents.conf |
|||
1001
docs/doxygen/doxygenbase.css
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
|
|||
<!-- HTML footer for doxygen 1.8.14--> |
|||
<!-- start footer part --> |
|||
<!--BEGIN GENERATE_TREEVIEW--> |
|||
<div id="nav-path" class="navpath"><!-- id is needed for treeview function! --> |
|||
<ul> |
|||
$navpath |
|||
</ul> |
|||
</div> |
|||
<!--END GENERATE_TREEVIEW--> |
|||
<!--BEGIN !GENERATE_TREEVIEW--> |
|||
<hr class="footer"/> |
|||
<!--END !GENERATE_TREEVIEW--> |
|||
</body> |
|||
</html> |
|||
|
|||
<!-- HTML header for doxygen 1.8.14--> |
|||
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> |
|||
<html xmlns="http://www.w3.org/1999/xhtml"> |
|||
<head> |
|||
<meta http-equiv="Content-Type" content="text/xhtml;charset=UTF-8"/> |
|||
<meta http-equiv="X-UA-Compatible" content="IE=9"/> |
|||
<meta name="generator" content="Doxygen $doxygenversion"/> |
|||
<meta name="viewport" content="width=device-width, initial-scale=1"/> |
|||
<!--BEGIN PROJECT_NAME--><title>$projectname: $title</title><!--END PROJECT_NAME--> |
|||
<!--BEGIN !PROJECT_NAME--><title>$title</title><!--END !PROJECT_NAME--> |
|||
<link href="$relpath^tabs.css" rel="stylesheet" type="text/css"/> |
|||
<script type="text/javascript" src="$relpath^jquery.js"></script> |
|||
<script type="text/javascript" src="$relpath^dynsections.js"></script> |
|||
$treeview |
|||
$search |
|||
$mathjax |
|||
<link href="$relpath^$stylesheet" rel="stylesheet" type="text/css" /> |
|||
$extrastylesheet |
|||
</head> |
|||
<body> |
|||
<div id="top"><!-- do not remove this div, it is closed by doxygen! --> |
|||
|
|||
<!--BEGIN TITLEAREA--> |
|||
<div id="titlearea"> |
|||
<table cellspacing="0" cellpadding="0"> |
|||
<tbody> |
|||
<tr style="height: 56px;"> |
|||
<!--BEGIN PROJECT_LOGO--> |
|||
<td id="projectlogo"><img alt="Logo" src="$relpath^$projectlogo"/></td> |
|||
<!--END PROJECT_LOGO--> |
|||
<!--BEGIN PROJECT_NAME--> |
|||
<td id="projectalign" style="padding-left: 0.5em;"> |
|||
<div id="projectname">$projectname |
|||
<!--BEGIN PROJECT_NUMBER--> <span id="projectnumber">$projectnumber</span><!--END PROJECT_NUMBER--> |
|||
</div> |
|||
<!--BEGIN PROJECT_BRIEF--><div id="projectbrief">$projectbrief</div><!--END PROJECT_BRIEF--> |
|||
</td> |
|||
<!--END PROJECT_NAME--> |
|||
<!--BEGIN !PROJECT_NAME--> |
|||
<!--BEGIN PROJECT_BRIEF--> |
|||
<td style="padding-left: 0.5em;"> |
|||
<div id="projectbrief">$projectbrief</div> |
|||
</td> |
|||
<!--END PROJECT_BRIEF--> |
|||
<!--END !PROJECT_NAME--> |
|||
<!--BEGIN DISABLE_INDEX--> |
|||
<!--BEGIN SEARCHENGINE--> |
|||
<td>$searchbox</td> |
|||
<!--END SEARCHENGINE--> |
|||
<!--END DISABLE_INDEX--> |
|||
</tr> |
|||
</tbody> |
|||
</table> |
|||
</div> |
|||
<!--END TITLEAREA--> |
|||
<!-- end header part --> |
|||
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
| 宽度: 280 | 高度: 45 | 大小: 5.2 KiB |
|
|||
#nav-tree .children_ul { |
|||
margin:0; |
|||
padding:4px; |
|||
} |
|||
|
|||
#nav-tree ul { |
|||
list-style:none outside none; |
|||
margin:0px; |
|||
padding:0px; |
|||
} |
|||
|
|||
#nav-tree li { |
|||
white-space:nowrap; |
|||
margin:0px; |
|||
padding:0px; |
|||
} |
|||
|
|||
#nav-tree .plus { |
|||
margin:0px; |
|||
} |
|||
|
|||
#nav-tree .selected { |
|||
background-image: url('tab_a.png'); |
|||
background-repeat:repeat-x; |
|||
color: #fff; |
|||
text-shadow: 0px 1px 1px rgba(0, 0, 0, 1.0); |
|||
} |
|||
|
|||
#nav-tree img { |
|||
margin:0px; |
|||
padding:0px; |
|||
border:0px; |
|||
vertical-align: middle; |
|||
} |
|||
|
|||
#nav-tree a { |
|||
text-decoration:none; |
|||
padding:0px; |
|||
margin:0px; |
|||
outline:none; |
|||
} |
|||
|
|||
#nav-tree .label { |
|||
margin:0px; |
|||
padding:0px; |
|||
font: 12px 'Lucida Grande',Geneva,Helvetica,Arial,sans-serif; |
|||
} |
|||
|
|||
#nav-tree .label a { |
|||
padding:2px; |
|||
} |
|||
|
|||
#nav-tree .selected a { |
|||
text-decoration:none; |
|||
color:#fff; |
|||
} |
|||
|
|||
#nav-tree .children_ul { |
|||
margin:0px; |
|||
padding:0px; |
|||
} |
|||
|
|||
#nav-tree .item { |
|||
margin:0px; |
|||
padding:0px; |
|||
} |
|||
|
|||
#nav-tree { |
|||
padding: 0px 0px; |
|||
background-color: #FAFAFF; |
|||
font-size:14px; |
|||
overflow:auto; |
|||
} |
|||
|
|||
#doc-content { |
|||
overflow:auto; |
|||
display:block; |
|||
padding:0px; |
|||
margin:0px; |
|||
-webkit-overflow-scrolling : touch; /* iOS 5+ */ |
|||
} |
|||
|
|||
#side-nav { |
|||
padding:0 6px 0 0; |
|||
margin: 0px; |
|||
display:block; |
|||
position: absolute; |
|||
left: 0px; |
|||
width: 250px; |
|||
} |
|||
|
|||
.ui-resizable .ui-resizable-handle { |
|||
display:block; |
|||
} |
|||
|
|||
.ui-resizable-e { |
|||
/* background-image:url("splitbar.png"); */ |
|||
background-size:100%; |
|||
background-repeat:no-repeat; |
|||
background-attachment: scroll; |
|||
cursor:ew-resize; |
|||
height:100%; |
|||
right:0; |
|||
top:0; |
|||
width:6px; |
|||
} |
|||
|
|||
.ui-resizable-handle { |
|||
display:none; |
|||
font-size:0.1px; |
|||
position:absolute; |
|||
z-index:1; |
|||
} |
|||
|
|||
#nav-tree-contents { |
|||
margin: 6px 0px 0px 0px; |
|||
} |
|||
|
|||
#nav-tree { |
|||
background-image:url('nav_h.png'); |
|||
background-repeat:repeat-x; |
|||
background-color: #F9FAFC; |
|||
-webkit-overflow-scrolling : touch; /* iOS 5+ */ |
|||
} |
|||
|
|||
#nav-sync { |
|||
position:absolute; |
|||
top:5px; |
|||
right:24px; |
|||
z-index:0; |
|||
} |
|||
|
|||
#nav-sync img { |
|||
opacity:0.3; |
|||
} |
|||
|
|||
#nav-sync img:hover { |
|||
opacity:0.9; |
|||
} |
|||
|
|||
@media print |
|||
{ |
|||
#nav-tree { display: none; } |
|||
div.ui-resizable-handle { display: none; position: relative; } |
|||
} |
|||
|
|||
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 3 | 高度: 1024 | 大小: 2.8 KiB |
|
|||
/* ==================================================== |
|||
* Company: Unity Technologies |
|||
* Author: Rickard Andersson, rickard@unity3d.com |
|||
======================================================= */ |
|||
|
|||
/*************************************** |
|||
==== Doxygen Style overides |
|||
****************************************/ |
|||
|
|||
#titlearea |
|||
{ |
|||
background-color: #222c37; |
|||
} |
|||
|
|||
#projectlogo |
|||
{ |
|||
vertical-align: middle; |
|||
padding: 0px 0px 5px 5px; |
|||
} |
|||
|
|||
#projectname |
|||
{ |
|||
vertical-align: middle; |
|||
color: white; |
|||
} |
|||
|
|||
.sm-dox { |
|||
background-image: none; |
|||
background-color :#e6e6e6; |
|||
color: #999; |
|||
border-style: solid; |
|||
border-width: thin; |
|||
} |
|||
|
|||
.navpath ul{ |
|||
background-image: none; |
|||
background-color :#e6e6e6; |
|||
color: #999; |
|||
border-style: dotted; |
|||
border-width: thin; |
|||
} |
|||
|
|||
.ui-resizable-e { |
|||
background-image:none; |
|||
background-size:100%; |
|||
background-repeat:no-repeat; |
|||
background-attachment: scroll; |
|||
cursor:ew-resize; |
|||
height:100%; |
|||
right:0; |
|||
top:0; |
|||
width:6px; |
|||
} |
|||
|
|||
/**************************************** |
|||
==== RESETS & EXTRAS |
|||
****************************************/ |
|||
|
|||
html,body,div { margin: 0; padding: 0; } |
|||
dl,dt,dd,h1,h2,h3,h4,h5,h6,pre,form,p,blockquote,input,figure { margin: 0 0 0 10px; padding: 0; } |
|||
h1,h2,h3,h4,h5,h6,pre,code,cite,code,th { font-size: 1em; font-weight: normal; font-style: normal; } |
|||
article, aside, details, figcaption, figure, footer, header, hgroup, menu, nav, section, video { display: block; } |
|||
iframe { border: none; } caption,th { text-align: left; } table { border-collapse: collapse; border-spacing: 0; } |
|||
img, img a, img a:hover { border: 0; display: block; max-width: 100%; } |
|||
hr { color: black; border-style: solid; border-width: 1px; } |
|||
hr.section { color: silver; border-style: solid; border-width: 1px; } |
|||
::-moz-selection { background: #999; color: #fff; text-shadow: none; } |
|||
::selection { background: #999; color: #fff; text-shadow: none; } |
|||
.clear:after { visibility: hidden; display: block; font-size: 0; content: " "; clear: both; height: 0; }.clear { display: inline-table; clear: both; } |
|||
/* Hides from IE-mac \*/ * html .clear { height: 1%; } .clear { display: block; } /* End hide from IE-mac */ |
|||
.left { float: left !important; } .right { float: right !important; } |
|||
.hide {display: none !important;} .hidden { visibility: hidden; opacity: 0; } |
|||
.mb0 { margin-bottom: 0 !important; } .mb5 { margin-bottom: 5px !important; } .mb10 { margin-bottom: 10px !important; } .mb20 { margin-bottom: 20px !important; } |
|||
.mt10 { margin-top: 10px; } .mr0 { margin-right: 0 !important; } .mr10 { margin-right: 10px !important; } |
|||
.cl { color: #99a0a7; } .cw { color: #fff !important; } .lh42 { line-height: 42px;} .rel { position: relative; } |
|||
|
|||
.otherversionswrapper{ position:relative;display:inline;margin-left:2%; } |
|||
.otherversionscontent{ position:absolute;top:100%;left:0px;background-color:white;border:1px solid grey;border-radius:12px;width: 150%;max-height:300%;overflow-y:scroll;text-align:center;padding:0.5% 0%; } |
|||
.otherversionsitem{ display:block; } |
|||
|
|||
/**************************************** |
|||
==== FORM |
|||
****************************************/ |
|||
|
|||
input, select, textarea { font-family: 'Open Sans','Nanum Gothic',sans-serif; outline: none; margin: 0 0 20px 0; -webkit-appearance: none; } |
|||
button::-moz-focus-inner, input[type="reset"]::-moz-focus-inner, input[type="button"]::-moz-focus-inner, input[type="submit"]::-moz-focus-inner, input[type="file"] > input[type="button"]::-moz-focus-inner { padding: 0px; } |
|||
input[type="text"], input[type="tel"], input[type="email"], input[type="url"], input[type="password"], select, textarea { width: 100%; font-size: 0.9375em; display: block; outline-width: 0; border: #00cccc 1px solid; line-height: 18px; padding: 10px 13px; color: #455463 !important; resize: none; -webkit-box-sizing: border-box; -moz-box-sizing: border-box; box-sizing: border-box; -webkit-border-radius: 3px; -moz-border-radius: 3px; border-radius: 3px; } |
|||
input[type="text"]:focus, input[type="tel"]:focus, input[type="email"]:focus, input[type="url"]:focus, input[type="password"]:focus, select:focus, textarea:focus { border-color: #455463 !important; } |
|||
textarea { height: 100px; } |
|||
label { display: inline-block; font-size: 0.9375em; margin: 0 0 7px 0; font-weight: bold; cursor: pointer; text-transform: uppercase; } |
|||
label span.r { color: #00cccc; } |
|||
input[type="text"].error, input[type="tel"].error, input[type="email"].error, input[type="password"].error, textarea.error { padding: 10px 45px 10px 13px; background: #fff url(../images/error-red.png) right 15px no-repeat; } |
|||
|
|||
/**************************************** |
|||
==== MESSAGES |
|||
****************************************/ |
|||
|
|||
div.message { padding: 10px 15px; margin: 0 0 15px 0; font-size: 0.875em; } |
|||
div.message-error { background: #ffe2d7; } |
|||
div.message-warning { background: #fff9d7; } |
|||
div.message-ok { background: #ebffce; } |
|||
|
|||
/**************************************** |
|||
==== LOADING |
|||
****************************************/ |
|||
|
|||
div.loading { width: 60px; height: 18px; position: absolute; left: 50%; top: 50%; z-index: 15; margin: -9px 0 0 -30px; } |
|||
div.loading div { width: 18px; height: 18px; display: block; float: left; margin: 0 1px; background-color: #29e5b7; -webkit-border-radius: 100%; -moz-border-radius: 100%; border-radius: 100%; -webkit-box-shadow: 0px 20px 20px rgba(255,255,255,0.2); -moz-box-shadow: 0px 20px 20px rgba(255,255,255,0.2); box-shadow: 0px 20px 20px rgba(255,255,255,0.2); -webkit-animation: bouncedelay 1.4s infinite ease-in-out; -moz-animation: bouncedelay 1.4s infinite ease-in-out; -o-animation: bouncedelay 1.4s infinite ease-in-out; animation: bouncedelay 1.4s infinite ease-in-out; -webkit-animation-fill-mode: both; -moz-animation-fill-mode: both; -o-animation-fill-mode: both; animation-fill-mode: both; } |
|||
div.loading div:nth-child(1){ -webkit-animation-delay: -0.32s; -moz-animation-delay: -0.32s; -o-animation-delay: -0.32s; animation-delay: -0.32s; } |
|||
div.loading div:nth-child(2){ -webkit-animation-delay: -0.16s; -moz-animation-delay: -0.16s; -o-animation-delay: -0.16s; animation-delay: -0.16s; } |
|||
/* Loading animation */ |
|||
@-webkit-keyframes bouncedelay { |
|||
0%, 80%, 100% { -webkit-transform: scale(0.0) } |
|||
40% { -webkit-transform: scale(1.0) } |
|||
} |
|||
@-moz-keyframes bouncedelay { |
|||
0%, 80%, 100% { -moz-transform: scale(0.0) } |
|||
40% { -moz-transform: scale(1.0) } |
|||
} |
|||
@-o-keyframes bouncedelay { |
|||
0%, 80%, 100% { -o-transform: scale(0.0) } |
|||
40% { -o-transform: scale(1.0) } |
|||
} |
|||
@keyframes bouncedelay { |
|||
0%, 80%, 100% { transform: scale(0.0) } |
|||
40% { transform: scale(1.0) } |
|||
} |
|||
|
|||
/**************************************** |
|||
==== TOOLTIP |
|||
****************************************/ |
|||
|
|||
.tt { position: relative; } |
|||
.tt div.tip { height: 20px; line-height: 20px; position: absolute; left: -100000px; z-index: 30; background: #444; color: #fff; border: 0; font-size: 0.6875em; font-weight: normal; padding: 0 5px; white-space: nowrap; border-radius: 2px; -moz-border-radius: 2px; -webkit-border-radius: 2px; text-align: center; } |
|||
.tt div.b:after { content: ""; display: block; position: absolute; top: -8px; left: 50%; font-size: 0px; line-height: 0%; width: 0px; margin: 0 0 0 -3px; border-top: 4px solid transparent; border-left: 4px solid transparent; border-bottom: 4px solid #444; border-right: 4px solid transparent; } |
|||
.tt div.t:after { content: ""; display: block; position: absolute; bottom: -8px; left: 50%; font-size: 0px; line-height: 0%; width: 0px; margin: 0 0 0 -4px; border-top: 4px solid #444; border-left: 4px solid transparent; border-bottom: 4px solid transparent; border-right: 4px solid transparent; } |
|||
|
|||
/**************************************** |
|||
==== TYPO |
|||
****************************************/ |
|||
|
|||
body { font: 16px/135% 'Open Sans', sans-serif; color: #455463; font-style: normal; font-weight: normal; overflow: auto; overflow-y: scroll; -webkit-text-size-adjust: none; -ms-text-size-adjust: none; -webkit-tap-highlight-color: rgba(0,0,0,0); -webkit-font-smoothing: antialiased; } |
|||
h1 { font-size: 2em; line-height: 1em; color: #1b2229; font-weight: 700; margin: 0 0 20px 0; word-wrap: break-word; } |
|||
h1.inherit { margin: 0 15px 5px 0; } |
|||
h1 a { text-decoration: underline; color: #1b2229; } |
|||
h1 a:hover { text-decoration: none; color: #1b2229; } |
|||
h2 { font-size: 1.5em; line-height: 1em; color: #1b2229; font-weight: 700; margin: 20px 0 5px 10px; } |
|||
div.subsection div.subsection h2 { font-size: 1.125em; color: #455463; } |
|||
h3 { font-size: 1.25em; line-height: 1.2em; font-weight: bold; margin: 10px 0 10px 10px; color: #455463; } |
|||
h4 { font-size: 1em; line-height: 1em; font-weight: bold; margin: 10px 0 10px 10px; color: #455463; } |
|||
p { max-width: 1100px; font-size: 0.875em; margin: 0 0 15px 10px; } |
|||
a { color: #b83c82; text-decoration: underline; outline: none; cursor: pointer; } |
|||
a:hover, a:focus, a:active { color: #b83c82; text-decoration: none; outline: none; } |
|||
.cn { color: #455463; } .cn:hover { color: #455463; } .b, strong { font-weight: 700; } |
|||
ul.l { list-style-type: none; } |
|||
ul.l li { padding: 0 0 4px 30px; background: none; position: relative; font-size: 0.875em; } |
|||
ul.l li:before { content: "\2022"; font-size: 1.8em; position: absolute; top: 0; left: 0; color: #455463; } |
|||
ul.l li a { color: #333; } |
|||
|
|||
/**************************************** |
|||
==== BUTTONS |
|||
****************************************/ |
|||
|
|||
.blue-btn, .gray-btn { height: 42px; line-height: 42px; display: block; float: left; padding: 0 20px; color: #fff; font-size: 0.8125em; text-align: center; cursor: pointer; text-decoration: none; border: 0; outline: none; font-family: 'avalonbold','Open Sans',sans-serif; text-transform: uppercase; -webkit-border-radius: 3px; -moz-border-radius: 3px; border-radius: 3px; } |
|||
input.blue-btn, input.gray-btn { padding: 0 20px 4px 20px; } |
|||
.blue-btn { background-color: #00cccc; } |
|||
.blue-btn:hover { color: #fff; background-color: #222c37; } |
|||
.gray-btn { background-color: #222c37; } |
|||
.gray-btn:hover { color: #fff; background-color: #222c37; } |
|||
.bbtn { height: 50px; line-height: 50px; padding: 0 40px !important; font-size: 1.0em; } |
|||
.sbtn { height: 24px; line-height: 24px; padding: 0 10px !important; font-size: 0.75em; } |
|||
.dbtn, .dbtn:hover, .dbtn:active { cursor: default; background-color: #ccc; color: #f0f0f0; background-color: #ccc; } |
|||
.centerbtn { float: none; display: inline-block; margin: 0; } |
|||
|
|||
/**************************************** |
|||
==== HEADER |
|||
****************************************/ |
|||
|
|||
div.header-wrapper { width: 100%; height: 100px; position: fixed; z-index: 30; } |
|||
div.header { width: 100%; height: 60px; background: white; } |
|||
div.header .content { min-width: 860px; margin: 0 auto; padding: 0 20px; position: relative; } |
|||
div.header .content .menu { width: 100%; float: left; margin: 0 -170px 0 0; position: relative; } |
|||
div.header .content .spacer { margin: 0 170px 0 0; } |
|||
div.header .menu .logo { width: 271px; height: 34px; float: left; padding: 13px 0 0 0; } |
|||
div.header .menu .logo a { width: 271px; height: 34px; display: block; background: url(../images/sprites.png) 0 0 no-repeat; } |
|||
div.header .menu ul { float: right; list-style-type: none; margin: 10px 0; padding: 0 30px 0 0; } |
|||
div.header .menu ul li { float: left; margin: 0 1px 0 0; font-size: 1em; font-family: 'avalon', sans-serif; } |
|||
div.header .menu ul li a { height: 40px; line-height: 40px; display: block; float: left; margin: 0 15px; text-decoration: none; cursor: pointer; color: #fff; -webkit-transition: color .15s; -moz-transition: color .15s; -ms-transition: color .15s; -o-transition: color .15s; transition: color .15s; } |
|||
div.header .menu ul li a:hover { color: #00cccc; } |
|||
div.header .menu ul li a.selected { color: #00cccc; position: relative; font-family: 'avalonbold', sans-serif; line-height: 44px; } |
|||
div.header .menu ul li a.selected:after { content: ''; display: block; width: 100%; height: 1px; position: absolute; bottom: 11px; left: 0; background: #00cccc; } |
|||
div.header div.search-form { float: right; position: relative; } |
|||
div.header div.search-form:before { content: ''; width: 18px; height: 60px; display: block; position: absolute; top: 0; left: -17px; background: url(../images/shard-left.png) 0 0 no-repeat; } |
|||
div.header div.search-form input.field { width: 350px; line-height: 18px; padding: 20px 50px 20px 20px; border: 0; margin: 0; -webkit-border-radius: 0; -moz-border-radius: 0; border-radius: 0; } |
|||
div.header div.search-form input.field:focus { background: #fff !important; } |
|||
div.header div.search-form input.submit { width: 30px; height: 30px; border: 0; margin: 0; cursor: pointer; outline-width: 0; text-indent: -9999em; position: absolute; top: 15px; right: 10px; background: url(../images/sprites.png) 5px -54px no-repeat; } |
|||
div.header .more { width: 170px; height: 60px; float: right; position: relative; } |
|||
div.header .more .filler { width: 800%; height: 60px; background: #00cccc; position: absolute; z-index: 14; left: 0px; top: 0; } |
|||
div.header .more .filler:before { content: ''; width: 18px; height: 60px; display: block; position: absolute; top: 0; left: -1px; background: url(../images/shard-right.png) 0 0 no-repeat; } |
|||
div.header .more ul { float: right; position: relative; z-index: 15; list-style: none; margin: 15px 15px 15px 0; } |
|||
div.header .more ul li { float: left; margin: 0 0 0 20px; font-size: 1em; font-family: 'avalon', sans-serif; } |
|||
div.header .more ul li a { height: 30px; line-height: 30px; display: block; float: left; padding: 0 31px 0 0; text-decoration: none; cursor: pointer; color: #fff; background: url(../images/sprites.png) right -112px no-repeat; } |
|||
|
|||
/**************************************** |
|||
==== TOOLBAR |
|||
****************************************/ |
|||
|
|||
div.toolbar { width: 100%; height: 40px; background: #e6e6e6; border-bottom: #222c37 0px solid; } |
|||
div.toolbar div.content { margin: 0 auto; padding: 0 15px; position: relative; } |
|||
div.toolbar div.script-lang { padding: 7px 0; margin: 0 15px 0 0; float: right; position: relative; } |
|||
div.toolbar div.script-lang ul { list-style-type: none; float: left; } |
|||
div.toolbar div.script-lang ul li { width: 46px; height: 26px; line-height: 26px; display: block; float: left; margin: 0 0 0 1px; text-align: center; font-size: 0.75em; cursor: pointer; background: #fff; } |
|||
div.toolbar div.script-lang ul li:hover, div.toolbar div.script-lang ul li.selected { background-color: #222c37; color: #fff; } |
|||
div.toolbar div.script-lang div.dialog { width: 300px; background: #fff; position: absolute; top: 45px; right: 0; z-index: 10; -webkit-box-shadow: 0 1px 20px rgba(34,44,55,0.3); -moz-box-shadow: 0 1px 20px rgba(34,44,55,0.3); box-shadow: 0 1px 20px rgba(34,44,55,0.3); } |
|||
div.toolbar div.script-lang div.dialog:before { content: ''; display: block; position: absolute; top: -16px; right: 60px; border: transparent 8px solid; border-bottom-color: #19e3b1; } |
|||
div.toolbar div.script-lang div.dialog-content { border-top: #19e3b1 5px solid; padding: 15px; } |
|||
div.toolbar div.script-lang div.dialog-content h2 { float: left; margin: 0 0 10px 0; font-size: 1.125em; font-family: 'avalonbold', sans-serif; text-transform: uppercase; } |
|||
div.toolbar div.script-lang div.dialog-content p { padding: 10px 0 0 0; margin: 0; border-top: #e6e6e6 1px solid; font-size: 0.8125em; line-height: 1.3em; } |
|||
div.toolbar div.script-lang div.dialog div.close { width: 18px; height: 18px; float: right; cursor: pointer; background: url(../images/sprites.png) 0 -106px no-repeat; } |
|||
div.lang-switcher { padding: 7px 0; float: right; position: relative; } |
|||
div.lang-switcher div.current { float: left; } |
|||
div.lang-switcher div.lbl { float: left; line-height: 26px; padding: 0 3px 0 0; font-size: 0.8125em; cursor: pointer; } |
|||
div.lang-switcher div.current div.arrow { width: 7px; height: 26px; float: left; background: url(../images/sprites.png) -484px -24px no-repeat; cursor: pointer; } |
|||
div.lang-switcher div.lang-list { width: 150px; position: absolute; top: 36px; right: 0; z-index: 9999; background: #fff; border-top: #19e3b1 4px solid; -webkit-box-shadow: 0 1px 5px rgba(0,0,0,0.3); -moz-box-shadow: 0 1px 5px rgba(0,0,0,0.3); box-shadow: 0 1px 5px rgba(0,0,0,0.3); display: none; } |
|||
div.lang-switcher div.lang-list:before { content: ""; display: block; position: absolute; top: -20px; left: 50%; font-size: 0px; line-height: 0%; width: 0px; margin: 0 0 0 -5px; border: transparent 8px solid; border-bottom-color: #19e3b1; } |
|||
div.lang-switcher div.lang-list ul { list-style-type: none; } |
|||
div.lang-switcher div.lang-list li { font-size: 0.8125em; border-bottom: #e6e6e6 1px solid; } |
|||
div.lang-switcher div.lang-list li:last-child { border: 0; } |
|||
div.lang-switcher div.lang-list a { display: block; padding: 7px 10px; color: #455463; text-decoration: none; } |
|||
div.lang-switcher div.lang-list a:hover { background: #f0f0f0; } |
|||
div.version-number { padding: 9px 7px; float: left; position: relative; } |
|||
|
|||
/**************************************** |
|||
==== LAYOUT |
|||
****************************************/ |
|||
|
|||
div.master-wrapper { min-width: 860px; margin: 0 auto 40px auto; padding: 100px 0 20px 0; } |
|||
div.content-wrap { width: 100%; float: right; margin: 0 0 0 -380px; position: relative; } |
|||
div.content-block { margin: 0 0 0 380px; } |
|||
div.content-wrap div.content { min-width: 460px; padding: 40px 40px 0 0; } |
|||
div.content-wrap div.content div.section { padding: 0 10px; margin: 0 0 50px 0; min-height: 200px; } |
|||
|
|||
/**************************************** |
|||
==== FOOTER |
|||
****************************************/ |
|||
|
|||
div.footer-wrapper { width: 100%; height: 40px; margin: 0 auto; } |
|||
div.footer { height: 40px; line-height: 40px; margin: 0 10px; font-size: 0.8125em; border-top: #e6e6e6 1px solid; } |
|||
div.footer div.copy { float: left; } |
|||
div.footer div.copy a { color: #455463; font-size: 130%; font-weight: bold; } |
|||
div.footer div.menu { float: right; } |
|||
div.footer div.menu a { color: #455463; margin: 0 0 0 15px; } |
|||
|
|||
/**************************************** |
|||
==== SIDEBAR |
|||
****************************************/ |
|||
|
|||
div.sidebar { width: 340px; margin: 0 40px 0 0; float: left; position: relative; z-index: 2; } |
|||
div.sidebar-wrap { width: 339px; position: fixed; border-right: #e6e6e6 1px solid; } |
|||
div.sidebar p { padding: 10px 20px; background: #222c37; margin: 0; } |
|||
div.sidebar-menu h2 { margin: 20px 0; padding: 0 0 10px 0; border-bottom: #e6e6e6 1px solid; } |
|||
div.sidebar-menu ul { list-style-type: none; margin: 0 0 20px 0; position: relative; } |
|||
div.sidebar-menu ul li { font-size: 0.875em; word-wrap: break-word; margin: 0 0 8px 0; line-height: 1.3em; padding: 0 0 0 22px; position: relative; } |
|||
div.sidebar-menu ul li.nl span { cursor: pointer; } |
|||
div.sidebar-menu ul li div.arrow { width: 12px; height: 12px; cursor: pointer; border: #19e3b1 1px solid; position: absolute; top: 2px; left: 0; background: #19e3b1 url(../images/sprites.png) 0 0 no-repeat; } |
|||
div.sidebar-menu ul li div.collapsed { background-position: -51px -61px; } |
|||
div.sidebar-menu ul li div.expanded { background-position: -51px -95px; } |
|||
div.sidebar-menu ul li a { display: block; color: #455463; word-wrap: break-word; text-decoration: none; } |
|||
div.sidebar-menu ul li a:hover { text-decoration: underline; } |
|||
div.sidebar-menu ul li a.current { background: #222c37; color: #fff; padding: 5px 8px; text-decoration: none; } |
|||
div.sidebar-menu ul li ul { margin: 8px 0 8px 0; } |
|||
div.sidebar-menu ul li ul li ul:before { left: -15px; } |
|||
div.sidebar-menu ul li ul li div.arrow { left: 0; } |
|||
div.sidebar-menu ul li ul li { font-size: 1em; padding: 0 0 0 22px; } |
|||
div.sidebar-menu ul li ul li ul li { font-size: 1em; } |
|||
|
|||
/**************************************** |
|||
==== SIDEBAR CUSTOM SCROLLER |
|||
****************************************/ |
|||
|
|||
.mCSB_container { width: auto; margin: 0 30px 0 20px; overflow: hidden; } |
|||
.mCSB_container.mCS_no_scrollbar { margin: 0 20px; } |
|||
.mCS_disabled>.mCustomScrollBox>.mCSB_container.mCS_no_scrollbar, .mCS_destroyed>.mCustomScrollBox>.mCSB_container.mCS_no_scrollbar { margin-right: 30px; } |
|||
.mCustomScrollBox>.mCSB_scrollTools { width: 16px; height: 100%; top: 0; right: 0; z-index: 14; opacity: 0.5; filter: "alpha(opacity=50)"; -ms-filter:"alpha(opacity=50)"; } |
|||
.mCustomScrollBox:hover>.mCSB_scrollTools { opacity: 1; filter: "alpha(opacity=100)"; -ms-filter: "alpha(opacity=100)"; } |
|||
.mCSB_scrollTools .mCSB_draggerContainer { width: 8px; position: absolute; top: 0; bottom: 0; right: 0; z-index: 14; height: auto; } |
|||
.mCSB_scrollTools a+.mCSB_draggerContainer { margin: 20px 0; } |
|||
.mCSB_scrollTools .mCSB_draggerRail { width: 8px; height: 100%; margin: 0 auto; background: #ccf5f5; } |
|||
.mCSB_scrollTools .mCSB_dragger { width: 100%; height: 30px; cursor: pointer; } |
|||
.mCSB_scrollTools .mCSB_dragger .mCSB_dragger_bar { width: 8px; height: 100%; margin: 0 auto; text-align: center; background: #00cccc; } |
|||
.mCSB_scrollTools .mCSB_dragger:hover .mCSB_dragger_bar { background: #00cccc; } |
|||
.mCSB_scrollTools .mCSB_dragger:active .mCSB_dragger_bar, .mCSB_scrollTools .mCSB_dragger.mCSB_dragger_onDrag .mCSB_dragger_bar { background: #00cccc; } |
|||
.mCustomScrollBox { -ms-touch-action: none; } |
|||
|
|||
/**************************************** |
|||
==== HISTORY TABLE |
|||
****************************************/ |
|||
|
|||
.history-table { width: 100%; } |
|||
.history-table .link { width: 70%; } |
|||
.history-table .type { width: 15%; } |
|||
.history-table .namespace { width: 15%; } |
|||
.history-table th { padding: 5px 10px; font-size: 0.875em; font-weight: bold; background: #f0f0f0; } |
|||
.history-table td { padding: 7px 10px; font-size: 0.875em; border-bottom: #e6e6e6 1px solid; } |
|||
|
|||
/**************************************** |
|||
==== CONTENT |
|||
****************************************/ |
|||
|
|||
div.signature { margin: 0 0 40px 0; font-size: 0.875em; } |
|||
div.signature div.sig-block { margin: 0 0 3px 0; } |
|||
div.signature .sig-kw { font-weight: bold; } |
|||
.switch-link { margin: 10px 0 0 0; } |
|||
.suggest { float: left; margin: 10px 5px 0 0; position: relative; } |
|||
|
|||
table.list { width: 100%; margin: 0px 0 30px 0; font-size: 0.875em; } |
|||
table.list tbody { border-top: #e6e6e6 0px solid; } |
|||
table.list tr { -webkit-transition: background .15s; -moz-transition: background .15s; -ms-transition: background .15s; -o-transition: background .15s; transition: background .15s; } |
|||
table.list tr:nth-child(odd) { background: #f8f8f8; } |
|||
table.list tr:hover { outline: #00cccc 1px solid; } |
|||
table.list td { vertical-align: top; padding: 7px 10px; } |
|||
table.list td.lbl { width: 18%; } |
|||
table.list td.desc { width: 82%; } |
|||
table.list td.name { font-weight: 700; } |
|||
.content .section ul { list-style-type: none; margin: 0 0 20px 0; } |
|||
.content .section ul li, .content .section ol li ul li { padding: 0 0 3px 20px; background: none; position: relative; font-size: 0.875em; } |
|||
.content .section ul li:before { content: "\2022"; font-size: 1.8em; position: absolute; top: 0; left: 0; color: #455463; } |
|||
.content .section ul li ul, .content .section ul li ul li ul { margin: 0 0 5px 0; } |
|||
.content .section ul li ul li, .content .section ul li ul li ul li, .content .section ol li ul li { font-size: 1em; } |
|||
.content .section ol { margin: 0 0 20px 0; padding: 0 0 0 20px; } |
|||
.content .section ol li { padding: 0 0 5px 0; font-size: 0.875em; } |
|||
.content .section ul li ol { margin: 0 0 5px 0; } |
|||
.content .section ul li ol li:before { display: none; } |
|||
.content figure { margin: 0 0 30px 0; } |
|||
.content figure img { margin: 0 0 10px 0; } |
|||
.content figure figcaption { margin: 0 0 10px 0; font-size: 0.875em; color: #99a0a7; } |
|||
|
|||
/**************************************** |
|||
==== SUGGESTION FORM |
|||
****************************************/ |
|||
|
|||
.suggest .suggest-wrap { width: 400px; position: absolute; top: 36px; left: 50%; z-index: 15; margin: 0 0 0 -200px; background: #fff; -webkit-box-shadow: 0 1px 20px rgba(34,44,55,0.3); -moz-box-shadow: 0 1px 20px rgba(34,44,55,0.3); box-shadow: 0 1px 20px rgba(34,44,55,0.3); } |
|||
.suggest .suggest-wrap:before { content: ''; display: block; position: absolute; top: -16px; left: 50%; margin: 0 0 0 -8px; border: transparent 8px solid; border-bottom-color: #222c37; } |
|||
.suggest .suggest-wrap .suggest-form { padding: 20px; border-top: #222c37 5px solid; } |
|||
.suggest .suggest-wrap label { font-size: 0.875em; } |
|||
.suggest-failed, .suggest-success { width: 100%; position: absolute; top: 0; left: 0; padding: 20px; border-top: #222c37 5px solid; -webkit-box-sizing: border-box; -moz-box-sizing: border-box; box-sizing: border-box; } |
|||
|
|||
/**************************************** |
|||
==== SEARCH RESULTS |
|||
****************************************/ |
|||
|
|||
div.search-results h2 { padding: 0 0 15px 0 !important; border-bottom: #e6e6e6 1px solid; font-weight: 400; } |
|||
div.search-results h2 span.q { font-weight: bold; } |
|||
div.search-results b { word-wrap: break-word; } |
|||
div.search-results div.result { width: 90%; margin: 0 0 20px 0; } |
|||
div.search-results div.result a.title { color: #ff0066; font-size: 1em; } |
|||
div.search-results div.result p strong { font-weight: 400 !important; } |
|||
|
|||
/**************************************** |
|||
==== CODE SNIPPETS |
|||
****************************************/ |
|||
|
|||
pre { font-family: Consolas,Monaco,'Andale Mono',monospace; padding: 20px; margin: 0 0 30px 0; border: #ddd 1px solid; background: #fff; font-size: 0.9375em; color: #455463; overflow: auto; } |
|||
.code, .codelisting { white-space: pre; } |
|||
pre .comment { color: #19e3b1; } |
|||
pre .hl-comment { color: #19e3b1; } |
|||
|
|||
.doc-prop, .doc-menu, .doc-inspector, .doc-keyword { |
|||
font-family: Consolas, Monaco, 'Andale Mono', monospace; |
|||
} |
|||
|
|||
/**************************************** |
|||
==== MEDIA QUERIES |
|||
****************************************/ |
|||
|
|||
@media only screen and (max-width: 1260px) { |
|||
|
|||
div.header .content { padding: 0 0 0 20px; } |
|||
div.header .content .menu { width: 100%; margin: 0; } |
|||
div.header .content .spacer { margin: 0; } |
|||
div.header .more { display: none; } |
|||
div.header div.search-form input.field { width: 300px; } |
|||
div.content-wrap { margin: 0 0 0 -360px; } |
|||
div.content-block { margin: 0 0 0 360px; } |
|||
div.content-wrap div.content { padding: 20px 20px 0 0; } |
|||
div.sidebar { margin: 0 20px 0 0; } |
|||
div.footer-wrapper { height: auto; } |
|||
div.footer { height: auto; line-height: 21px; padding: 10px 0 0 0; } |
|||
div.footer div.copy, div.footer div.menu { float: none; } |
|||
div.footer div.menu a { margin: 0 15px 0 0; } |
|||
|
|||
} |
|||
|
|||
@media only screen and (max-width: 900px) { |
|||
|
|||
div.master-wrapper { padding: 0 0 20px 0; } |
|||
div.header-wrapper { width: auto; position: relative; float: left; } |
|||
div.sidebar-wrap { position: static; } |
|||
div.content-wrap { width: 480px; float: left; margin: 0; } |
|||
div.content-block { margin: 0; } |
|||
|
|||
} |
|||
@media only screen and (-moz-min-device-pixel-ratio: 2), only screen and (-o-min-device-pixel-ratio: 2/1), only screen and (-webkit-min-device-pixel-ratio: 2), only screen and (min-device-pixel-ratio: 2) { |
|||
|
|||
div.header .menu .logo a, div.header .more ul li a, div.toolbar div.script-lang div.dialog div.close, div.lang-switcher div.current div.arrow, div.sidebar-menu ul li div.arrow { background-image: url(../images/sprites@2x.png); -webkit-background-size: 500px 250px; -moz-background-size: 500px 250px; -o-background-size: 500px 250px; background-size: 500px 250px; } |
|||
input[type="text"].error, input[type="tel"].error, input[type="email"].error, input[type="password"].error, textarea.error { background-image: url(../images/error-red.png); -webkit-background-size: 24px 12px; -moz-background-size: 24px 12px; background-size: 24px 12px; } |
|||
div.header div.search-form:before { background-image: url(../images/shard-left@2x.png); -webkit-background-size: 18px 60px; -moz-background-size: 18px 60px; background-size: 18px 60px; } |
|||
div.header .more .filler:before { background-image: url(../images/shard-right@2x.png); -webkit-background-size: 18px 60px; -moz-background-size: 18px 60px; background-size: 18px 60px; } |
|||
|
|||
} |
|||
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 487 | 高度: 347 | 大小: 56 KiB |
58
docs/images/basic.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|
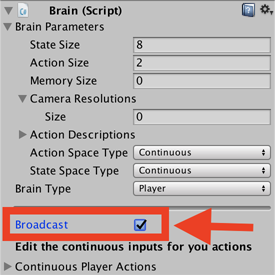
|
|
| 宽度: 275 | 高度: 275 | 大小: 37 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
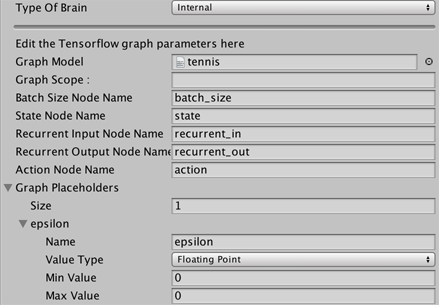
|
|
| 宽度: 439 | 高度: 305 | 大小: 38 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 2132 | 高度: 880 | 大小: 146 KiB |
469
docs/images/learning_environment_example.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
1001
docs/images/mlagents-3DBall.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|
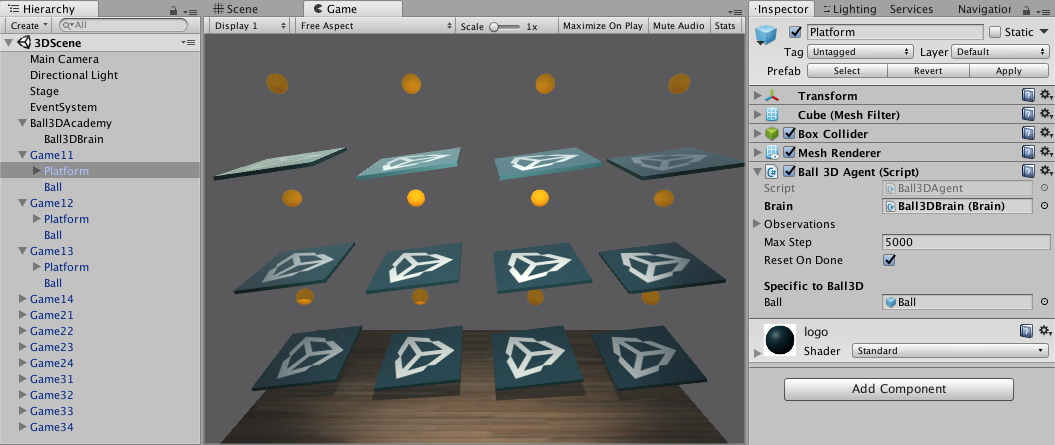
|
|
| 宽度: 1055 | 高度: 445 | 大小: 169 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 536 | 高度: 295 | 大小: 27 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 442 | 高度: 342 | 大小: 48 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
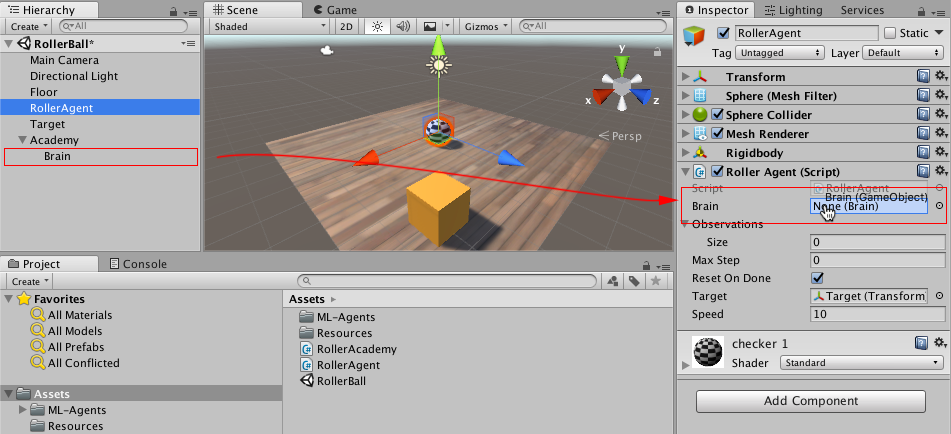
|
|
| 宽度: 951 | 高度: 434 | 大小: 200 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
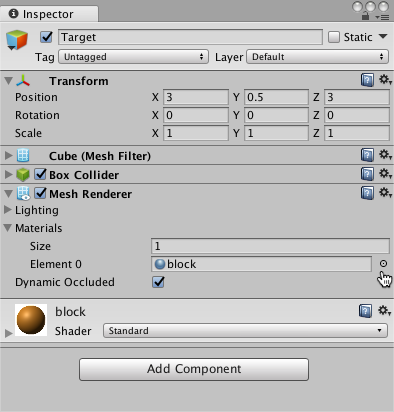
|
|
| 宽度: 394 | 高度: 412 | 大小: 37 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 442 | 高度: 344 | 大小: 48 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 394 | 高度: 412 | 大小: 36 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 397 | 高度: 222 | 大小: 12 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 394 | 高度: 418 | 大小: 40 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 751 | 高度: 262 | 大小: 167 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 1100 | 高度: 614 | 大小: 179 KiB |
1001
docs/images/mlagents-Scene.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|
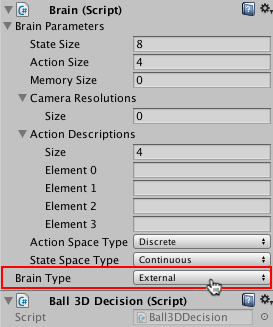
|
|
| 宽度: 273 | 高度: 327 | 大小: 23 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
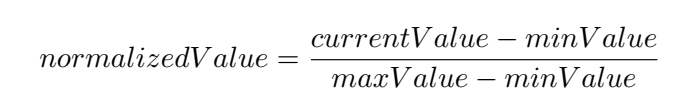
|
|
| 宽度: 697 | 高度: 104 | 大小: 14 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
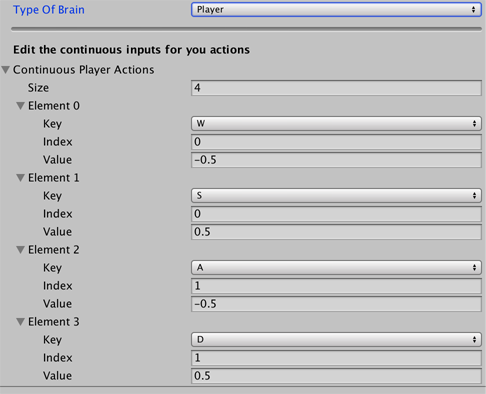
|
|
| 宽度: 486 | 高度: 394 | 大小: 44 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
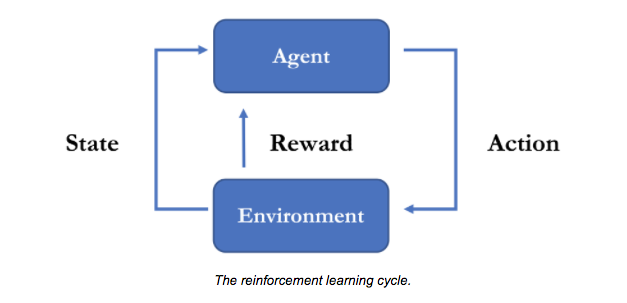
|
|
| 宽度: 627 | 高度: 303 | 大小: 32 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 254 | 高度: 270 | 大小: 21 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 3 | 高度: 1024 | 大小: 2.8 KiB |
|
|||
# ML Agents Editor Interface |
|||
|
|||
This page contains an explanation of the use of each of the inspector panels relating to the `Academy`, `Brain`, and `Agent` objects. |
|||
|
|||
## Academy |
|||
|
|||
 |
|||
|
|||
* `Max Steps` - Total number of steps per-episode. `0` corresponds to episodes without a maximum number |
|||
of steps. Once the step counter reaches maximum, the environment will reset. |
|||
* `Frames To Skip` - How many steps of the environment to skip before asking Brains for decisions. |
|||
* `Wait Time` - How many seconds to wait between steps when running in `Inference`. |
|||
* `Configuration` - The engine-level settings which correspond to rendering quality and engine speed. |
|||
* `Width` - Width of the environment window in pixels. |
|||
* `Height` - Width of the environment window in pixels. |
|||
* `Quality Level` - Rendering quality of environment. (Higher is better) |
|||
* `Time Scale` - Speed at which environment is run. (Higher is faster) |
|||
* `Target Frame Rate` - FPS engine attempts to maintain. |
|||
* `Default Reset Parameters` - List of custom parameters that can be changed in the environment on reset. |
|||
|
|||
## Brain |
|||
|
|||
 |
|||
|
|||
* `Brain Parameters` - Define state, observation, and action spaces for the Brain. |
|||
* `State Size` - Length of state vector for brain (In _Continuous_ state space). Or number of possible |
|||
values (in _Discrete_ state space). |
|||
* `Action Size` - Length of action vector for brain (In _Continuous_ state space). Or number of possible |
|||
values (in _Discrete_ action space). |
|||
* `Memory Size` - Length of memory vector for brain. Used with Recurrent networks and frame-stacking CNNs. |
|||
* `Camera Resolution` - Describes height, width, and whether to greyscale visual observations for the Brain. |
|||
* `Action Descriptions` - A list of strings used to name the available actions for the Brain. |
|||
* `State Space Type` - Corresponds to whether state vector contains a single integer (Discrete) or a series of real-valued floats (Continuous). |
|||
* `Action Space Type` - Corresponds to whether action vector contains a single integer (Discrete) or a series of real-valued floats (Continuous). |
|||
* `Type of Brain` - Describes how Brain will decide actions. |
|||
* `External` - Actions are decided using Python API. |
|||
* `Internal` - Actions are decided using internal TensorflowSharp model. |
|||
* `Player` - Actions are decided using Player input mappings. |
|||
* `Heuristic` - Actions are decided using custom `Decision` script, which should be attached to the Brain game object. |
|||
|
|||
### Internal Brain |
|||
|
|||
 |
|||
|
|||
* `Graph Model` : This must be the `bytes` file corresponding to the pretrained Tensorflow graph. (You must first drag this file into your Resources folder and then from the Resources folder into the inspector) |
|||
* `Graph Scope` : If you set a scope while training your tensorflow model, all your placeholder name will have a prefix. You must specify that prefix here. |
|||
* `Batch Size Node Name` : If the batch size is one of the inputs of your graph, you must specify the name if the placeholder here. The brain will make the batch size equal to the number of agents connected to the brain automatically. |
|||
* `State Node Name` : If your graph uses the state as an input, you must specify the name if the placeholder here. |
|||
* `Recurrent Input Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the input placeholder here. |
|||
* `Recurrent Output Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the output placeholder here. |
|||
* `Observation Placeholder Name` : If your graph uses observations as input, you must specify it here. Note that the number of observations is equal to the length of `Camera Resolutions` in the brain parameters. |
|||
* `Action Node Name` : Specify the name of the placeholder corresponding to the actions of the brain in your graph. If the action space type is continuous, the output must be a one dimensional tensor of float of length `Action Space Size`, if the action space type is discrete, the output must be a one dimensional tensor of int of length 1. |
|||
* `Graph Placeholder` : If your graph takes additional inputs that are fixed (example: noise level) you can specify them here. Note that in your graph, these must correspond to one dimensional tensors of int or float of size 1. |
|||
* `Name` : Corresponds to the name of the placeholdder. |
|||
* `Value Type` : Either Integer or Floating Point. |
|||
* `Min Value` and `Max Value` : Specify the range of the value here. The value will be sampled from the uniform distribution ranging from `Min Value` to `Max Value` inclusive. |
|||
|
|||
|
|||
### Player Brain |
|||
|
|||
 |
|||
|
|||
If the action space is discrete, you must map input keys to their corresponding integer values. If the action space is continuous, you must map input keys to their corresponding indices and float values. |
|||
|
|||
## Agent |
|||
|
|||
 |
|||
|
|||
* `Brain` - The brain to register this agent to. Can be dragged into the inspector using the Editor. |
|||
* `Observations` - A list of `Cameras` which will be used to generate observations. |
|||
* `Max Step` - The per-agent maximum number of steps. Once this number is reached, the agent will be reset if `Reset On Done` is checked. |
|||
|
|||
# Making a new Learning Environment |
|||
|
|||
This tutorial walks through the process of creating a Unity Environment. A Unity Environment is an application built using the Unity Engine which can be used to train Reinforcement Learning agents. |
|||
|
|||
## Setting up the Unity Project |
|||
|
|||
1. Open an existing Unity project, or create a new one and import the RL interface package: |
|||
* [ML-Agents package without TensorflowSharp](https://s3.amazonaws.com/unity-agents/0.2/ML-AgentsNoPlugin.unitypackage) |
|||
* [ML-Agents package with TensorflowSharp](https://s3.amazonaws.com/unity-agents/0.2/ML-AgentsWithPlugin.unitypackage) |
|||
|
|||
2. Rename `TemplateAcademy.cs` (and the contained class name) to the desired name of your new academy class. All Template files are in the folder `Assets -> Template -> Scripts`. Typical naming convention is `YourNameAcademy`. |
|||
|
|||
3. Attach `YourNameAcademy.cs` to a new empty game object in the currently opened scene (`Unity` -> `GameObject` -> `Create Empty`) and rename this game object to `YourNameAcademy`. Since `YourNameAcademy` will be used to control all the environment logic, ensure the attached-to object is one which will remain in the scene regardless of the environment resetting, or other within-environment behavior. |
|||
|
|||
4. Attach `Brain.cs` to a new empty game object and rename this game object to `YourNameBrain1`. Set this game object as a child of `YourNameAcademy` (Drag `YourNameBrain1` into `YourNameAcademy`). Note that you can have multiple brains in the Academy but they all must have different names. |
|||
|
|||
5. Disable Window Resolution dialogue box and Splash Screen. |
|||
1. Go to `Edit` -> `Project Settings` -> `Player` -> `Resolution and Presentation`. |
|||
2. Set `Display Resolution Dialogue` to `Disabled`. |
|||
3.Check `Run In Background`. |
|||
4. Click `Splash Image`. |
|||
5. Uncheck `Show Splash Screen` _(Unity Pro only)_. |
|||
|
|||
6. If you will be using Tensorflow Sharp in Unity, you must: |
|||
1. Make sure you are using Unity 2017.1 or newer. |
|||
2. Make sure the TensorflowSharp [plugin](https://s3.amazonaws.com/unity-agents/0.2/TFSharpPlugin.unitypackage) is in your Asset folder. |
|||
3. Go to `Edit` -> `Project Settings` -> `Player` |
|||
4. For each of the platforms you target (**`PC, Mac and Linux Standalone`**, **`iOS`** or **`Android`**): |
|||
1. Go into `Other Settings`. |
|||
2. Select `Scripting Runtime Version` to `Experimental (.NET 4.6 Equivalent)` |
|||
3. In `Scripting Defined Symbols`, add the flag `ENABLE_TENSORFLOW` |
|||
5. Note that some of these changes will require a Unity Restart |
|||
|
|||
# Implementing `YourNameAcademy` |
|||
|
|||
1. Click on the game object **`YourNameAcademy`**. |
|||
|
|||
2. In the inspector tab, you can modify the characteristics of the academy: |
|||
* **`Max Steps`** Maximum length of each episode (set to 0 if you want do not want the environment to reset after a certain time). |
|||
* **`Wait Time`** Real-time between steps when running environment in test-mode. |
|||
* **`Frames To Skip`** Number of frames (or physics updates) to skip between steps. The agents will act at every frame but get new actions only at every step. |
|||
* **`Training Configuration`** and **`Inference Configuration`** The first defines the configuration of the Engine at training time and the second at test / inference time. The training mode corresponds only to external training when the reset parameter `train_model` was set to True. The adjustable parameters are as follows: |
|||
* `Width` and `Height` Correspond to the width and height in pixels of the window (must be both greater than 0). Typically set it to a small size during training, and a larger size for visualization during inference. |
|||
* `Quality Level` Determines how mesh rendering is performed. Typically set to small value during training and higher value for visualization during inference. |
|||
* `Time Scale` Physics speed. If environment utilized physics calculations, increase this during training, and set to `1.0f` during inference. Otherwise, set it to `1.0f`. |
|||
* `Target Frame Rate` Frequency of frame rendering. If environment utilizes observations, increase this during training, and set to `60` during inference. If no observations are used, this can be set to `1` during training. |
|||
* **`Default Reset Parameters`** You can set the default configuration to be passed at reset. This will be a mapping from strings to float values that you can call in the academy with `resetParameters["YourDefaultParameter"]` |
|||
|
|||
3. Within **`InitializeAcademy()`**, you can define the initialization of the Academy. Note that this command is ran only once at the beginning of the training session. Do **not** use `Awake()`, `Start()` or `OnEnable()` |
|||
|
|||
3. Within **`AcademyStep()`**, you can define the environment logic each step. Use this function to modify the environment for the agents that will live in it. |
|||
|
|||
4. Within **`AcademyReset()`**, you can reset the environment for a new episode. It should contain environment-specific code for setting up the environment. Note that `AcademyReset()` is called at the beginning of the training session to ensure the first episode is similar to the others. |
|||
|
|||
## Implementing `YourNameBrain` |
|||
For each Brain game object in your academy : |
|||
|
|||
1. Click on the game object `YourNameBrain` |
|||
|
|||
2. In the inspector tab, you can modify the characteristics of the brain in **`Brain Parameters`** |
|||
* `State Size` Number of variables within the state provided to the agent(s). |
|||
* `Action Size` The number of possible actions for each individual agent to take. |
|||
* `Memory Size` The number of floats the agents will remember each step. |
|||
* `Camera Resolutions` A list of flexible length that contains resolution parameters : `height` and `width` define the number dimensions of the camera outputs in pixels. Check `Black And White` if you want the camera outputs to be black and white. |
|||
* `Action Descriptions` A list describing in human-readable language the meaning of each available action. |
|||
* `State Space Type` and `Action Space Type`. Either `discrete` or `continuous`. |
|||
* `discrete` corresponds to describing the action space with an `int`. |
|||
* `continuous` corresponds to describing the action space with an array of `float`. |
|||
|
|||
3. You can choose what kind of brain you want `YourNameBrain` to be. There are four possibilities: |
|||
* `External` : You need at least one of your brains to be external if you wish to interact with your environment from python. |
|||
* `Player` : To control your agents manually. If the action space is discrete, you must map input keys to their corresponding integer values. If the action space is continuous, you must map input keys to their corresponding indices and float values. |
|||
* `Heuristic` : You can have your brain automatically react to the observations and states in a customizable way. You will need to drag a `Decision` script into `YourNameBrain`. To create a custom reaction, you must : |
|||
* Rename `TemplateDecision.cs` (and the contained class name) to the desired name of your new reaction. Typical naming convention is `YourNameDecision`. |
|||
* Implement `Decide`: Given the state, observation and memory of an agent, this function must return an array of floats corresponding to the actions taken by the agent. If the action space type is discrete, the array must be of size 1. |
|||
* Optionally, implement `MakeMemory`: Given the state, observation and memory of an agent, this function must return an array of floats corresponding to the new memories of the agent. |
|||
* `Internal` : Note that you must have Tensorflow Sharp setup (see top of this page). Here are the fields that must be completed: |
|||
* `Graph Model` : This must be the `bytes` file corresponding to the pretrained Tensorflow graph. (You must first drag this file into your Resources folder and then from the Resources folder into the inspector) |
|||
* `Graph Scope` : If you set a scope while training your tensorflow model, all your placeholder name will have a prefix. You must specify that prefix here. |
|||
* `Batch Size Node Name` : If the batch size is one of the inputs of your graph, you must specify the name if the placeholder here. The brain will make the batch size equal to the number of agents connected to the brain automatically. |
|||
* `State Node Name` : If your graph uses the state as an input, you must specify the name if the placeholder here. |
|||
* `Recurrent Input Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the input placeholder here. |
|||
* `Recurrent Output Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the output placeholder here. |
|||
* `Observation Placeholder Name` : If your graph uses observations as input, you must specify it here. Note that the number of observations is equal to the length of `Camera Resolutions` in the brain parameters. |
|||
* `Action Node Name` : Specify the name of the placeholder corresponding to the actions of the brain in your graph. If the action space type is continuous, the output must be a one dimensional tensor of float of length `Action Space Size`, if the action space type is discrete, the output must be a one dimensional tensor of int of length 1. |
|||
* `Graph Placeholder` : If your graph takes additional inputs that are fixed (example: noise level) you can specify them here. Note that in your graph, these must correspond to one dimensional tensors of int or float of size 1. |
|||
* `Name` : Corresponds to the name of the placeholder. |
|||
* `Value Type` : Either Integer or Floating Point. |
|||
* `Min Value` and 'Max Value' : Specify the minimum and maximum values (included) the placeholder can take. The value will be sampled from the uniform distribution at each step. If you want this value to be fixed, set both `Min Value` and `Max Value` to the same number. |
|||
|
|||
## Implementing `YourNameAgent` |
|||
|
|||
1. Rename `TemplateAgent.cs` (and the contained class name) to the desired name of your new agent. Typical naming convention is `YourNameAgent`. |
|||
|
|||
2. Attach `YourNameAgent.cs` to the game object that represents your agent. (Example: if you want to make a self-driving car, attach `YourNameAgent.cs` to a car looking game object) |
|||
|
|||
3. In the inspector menu of your agent, drag the brain game object you want to use with this agent into the corresponding `Brain` box. Please note that you can have multiple agents with the same brain. If you want to give an agent a brain or change his brain via script, please use the method `ChangeBrain()`. |
|||
|
|||
4. In the inspector menu of your agent, you can specify what cameras, your agent will use as its observations. To do so, drag the desired number of cameras into the `Observations` field. Note that if you want a camera to move along your agent, you can set this camera as a child of your agent |
|||
|
|||
5. If `Reset On Done` is checked, `Reset()` will be called when the agent is done. Else, `AgentOnDone()` will be called. Note that if `Reset On Done` is unchecked, the agent will remain "done" until the Academy resets. This means that it will not take actions in the environment. |
|||
|
|||
6. Implement the following functions in `YourNameAgent.cs` : |
|||
* `InitializeAgent()` : Use this method to initialize your agent. This method is called when the agent is created. Do **not** use `Awake()`, `Start()` or `OnEnable()`. |
|||
* `CollectState()` : Must return a list of floats corresponding to the state the agent is in. If the state space type is discrete, return a list of length 1 containing the float equivalent of your state. |
|||
* `AgentStep()` : This function will be called every frame, you must define what your agent will do given the input actions. You must also specify the rewards and whether or not the agent is done. To do so, modify the public fields of the agent `reward` and `done`. |
|||
* `AgentReset()` : This function is called at start, when the Academy resets and when the agent is done (if `Reset On Done` is checked). |
|||
* `AgentOnDone()` : If `Reset On Done` is not checked, this function will be called when the agent is done. `Reset()` will only be called when the Academy resets. |
|||
|
|||
If you create Agents via script, we recommend you save them as prefabs and instantiate them either during steps or resets. If you do, you can use `GiveBrain(brain)` to have the agent subscribe to a specific brain. You can also use `RemoveBrain()` to unsubscribe from a brain. |
|||
|
|||
# Defining the reward function |
|||
The reward function is the set of circumstances and event which we want to reward or punish the agent for making happen. Here are some examples of positive and negative rewards: |
|||
* Positive |
|||
* Reaching a goal |
|||
* Staying alive |
|||
* Defeating an enemy |
|||
* Gaining health |
|||
* Finishing a level |
|||
* Negative |
|||
* Taking damage |
|||
* Failing a level |
|||
* The agent’s death |
|||
|
|||
Small negative rewards are also typically used each step in scenarios where the optimal agent behavior is to complete an episode as quickly as possible. |
|||
|
|||
Note that the reward is reset to 0 at every step, you must add to the reward (`reward += rewardIncrement`). If you use `skipFrame` in the Academy and set your rewards instead of incrementing them, you might lose information since the reward is sent at every step, not at every frame. |
|||
|
|||
# Organizing the Scene Layout |
|||
|
|||
This tutorial will help you understand how to organize your scene when using Agents in your Unity environment. |
|||
|
|||
## ML-Agents Game Objects |
|||
|
|||
There are three kinds of game objects you need to include in your scene in order to use Unity ML-Agents: |
|||
* Academy |
|||
* Brain |
|||
* Agents |
|||
|
|||
#### Keep in mind : |
|||
* There can only be one Academy game object in a scene. |
|||
* You can have multiple Brain game objects but they must be child of the Academy game object. |
|||
|
|||
#### Here is an example of what your scene hierarchy should look like : |
|||
|
|||
 |
|||
|
|||
### Functionality |
|||
|
|||
#### The Academy |
|||
The Academy is responsible for: |
|||
* Synchronizing the environment and keeping all agent's steps in pace. As such, there can only be one per scene. |
|||
* Determining the speed of the engine, its quality, and the display's resolution. |
|||
* Modifying the environment at every step and every reset according to the logic defined in `AcademyStep()` and `AcademyReset()`. |
|||
* Coordinating the Brains which must be set as children of the Academy. |
|||
|
|||
#### Brains |
|||
Each brain corresponds to a specific Decision-making method. This often aligns with a specific neural network model. A Brains is responsible for deciding the action of all the Agents which are linked to it. There can be multiple brains in the same scene and multiple agents can subscribe to the same brain. |
|||
|
|||
#### Agents |
|||
Each agent within a scene takes actions according to the decisions provided by it's linked Brain. There can be as many Agents of as many types as you like in the scene. The state size and action size of each agent must match the brain's parameters in order for the Brain to decide actions for it. |
|||
|
|||
# Learning Environments Overview |
|||
|
|||
 |
|||
|
|||
A visual depiction of how an Learning Environment might be configured within ML-Agents. |
|||
|
|||
The three main kinds of objects within any Agents Learning Environment are: |
|||
|
|||
* Agent - Each Agent can have a unique set of states and observations, take unique actions within the environment, and can receive unique rewards for events within the environment. An agent's actions are decided by the brain it is linked to. |
|||
* Brain - Each Brain defines a specific state and action space, and is responsible for deciding which actions each of its linked agents will take. Brains can be set to one of four modes: |
|||
* External - Action decisions are made using TensorFlow (or your ML library of choice) through communication over an open socket with our Python API. |
|||
* Internal (Experimental) - Actions decisions are made using a trained model embedded into the project via TensorFlowSharp. |
|||
* Player - Action decisions are made using player input. |
|||
* Heuristic - Action decisions are made using hand-coded behavior. |
|||
* Academy - The Academy object within a scene also contains as children all Brains within the environment. Each environment contains a single Academy which defines the scope of the environment, in terms of: |
|||
* Engine Configuration - The speed and rendering quality of the game engine in both training and inference modes. |
|||
* Frameskip - How many engine steps to skip between each agent making a new decision. |
|||
* Global episode length - How long the the episode will last. When reached, all agents are set to done. |
|||
|
|||
The states and observations of all agents with brains set to External are collected by the External Communicator, and communicated via the Python API. By setting multiple agents to a single brain, actions can be decided in a batch fashion, taking advantage of the inherently parallel computations of neural networks. For more information on how these objects work together within a scene, see our wiki page. |
|||
|
|||
## Flexible Training Scenarios |
|||
|
|||
With the Unity ML-Agents, a variety of different kinds of training scenarios are possible, depending on how agents, brains, and rewards are connected. We are excited to see what kinds of novel and fun environments the community creates. For those new to training intelligent agents, below are a few examples that can serve as inspiration. Each is a prototypical environment configurations with a description of how it can be created using the ML-Agents SDK. |
|||
|
|||
* **Single-Agent** - A single agent linked to a single brain. The traditional way of training an agent. An example is any single-player game, such as Chicken. [Video Link](https://www.youtube.com/watch?v=fiQsmdwEGT8&feature=youtu.be). |
|||
* **Simultaneous Single-Agent** - Multiple independent agents with independent reward functions linked to a single brain. A parallelized version of the traditional training scenario, which can speed-up and stabilize the training process. An example might be training a dozen robot-arms to each open a door simultaneously. [Video Link](https://www.youtube.com/watch?v=fq0JBaiCYNA). |
|||
* **Adversarial Self-Play** - Two interacting agents with inverse reward functions linked to a single brain. In two-player games, adversarial self-play can allow an agent to become increasingly more skilled, while always having the perfectly matched opponent: itself. This was the strategy employed when training AlphaGo, and more recently used by OpenAI to train a human-beating 1v1 Dota 2 agent. |
|||
* **Cooperative Multi-Agent** - Multiple interacting agents with a shared reward function linked to either a single or multiple different brains. In this scenario, all agents must work together to accomplish a task than couldn’t be done alone. Examples include environments where each agent only has access to partial information, which needs to be shared in order to accomplish the task or collaboratively solve a puzzle. (Demo project coming soon) |
|||
* **Competitive Multi-Agent** - Multiple interacting agents with inverse reward function linked to either a single or multiple different brains. In this scenario, agents must compete with one another to either win a competition, or obtain some limited set of resources. All team sports would fall into this scenario. (Demo project coming soon) |
|||
* **Ecosystem** - Multiple interacting agents with independent reward function linked to either a single or multiple different brains. This scenario can be thought of as creating a small world in which animals with different goals all interact, such a savanna in which there might be zebras, elephants, and giraffes, or an autonomous driving simulation within an urban environment. (Demo project coming soon) |
|||
|
|||
## Additional Features |
|||
|
|||
Beyond the flexible training scenarios made possible by the Academy/Brain/Agent system, ML-Agents also includes other features which improve the flexibility and interpretability of the training process. |
|||
|
|||
* **Monitoring Agent’s Decision Making** - Since communication in ML-Agents is a two-way street, we provide an Agent Monitor class in Unity which can display aspects of the trained agent, such as policy and value output within the Unity environment itself. By providing these outputs in real-time, researchers and developers can more easily debug an agent’s behavior. |
|||
|
|||
* **Curriculum Learning** - It is often difficult for agents to learn a complex task at the beginning of the training process. Curriculum learning is the process of gradually increasing the difficulty of a task to allow more efficient learning. ML-Agents supports setting custom environment parameters every time the environment is reset. This allows elements of the environment related to difficulty or complexity to be dynamically adjusted based on training progress. |
|||
|
|||
* **Complex Visual Observations** - Unlike other platforms, where the agent’s observation might be limited to a single vector or image, ML-Agents allows multiple cameras to be used for observations per agent. This enables agents to learn to integrate information from multiple visual streams, as would be the case when training a self-driving car which required multiple cameras with different viewpoints, a navigational agent which might need to integrate aerial and first-person visuals, or an agent which takes both a raw visual input, as well as a depth-map or object-segmented image. |
|||
|
|||
* **Imitation Learning (Coming Soon)** - It is often more intuitive to simply demonstrate the behavior we want an agent to perform, rather than attempting to have it learn via trial-and-error methods. In a future release, ML-Agents will provide the ability to record all state/action/reward information for use in supervised learning scenarios, such as imitation learning. By utilizing imitation learning, a player can provide demonstrations of how an agent should behave in an environment, and then utilize those demonstrations to train an agent in either a standalone fashion, or as a first-step in a reinforcement learning process. |
|||
|
|||
# Environment Design Best Practices |
|||
|
|||
## General |
|||
* It is often helpful to being with the simplest version of the problem, to ensure the agent can learn it. From there increase |
|||
complexity over time. This can either be done manually, or via Curriculum Learning, where a set of lessons which progressively increase in difficulty are presented to the agent ([learn more here](../docs/curriculum.md)). |
|||
* When possible, It is often helpful to ensure that you can complete the task by using a Player Brain to control the agent. |
|||
|
|||
## Rewards |
|||
* The magnitude of any given reward should typically not be greater than 1.0 in order to ensure a more stable learning process. |
|||
* Positive rewards are often more helpful to shaping the desired behavior of an agent than negative rewards. |
|||
* For locomotion tasks, a small positive reward (+0.1) for forward velocity is typically used. |
|||
* If you want the agent the finish a task quickly, it is often helpful to provide a small penalty every step (-0.05) that the agent does not complete the task. In this case completion of the task should also coincide with the end of the episode. |
|||
* Overly-large negative rewards can cause undesirable behavior where an agent learns to avoid any behavior which might produce the negative reward, even if it is also behavior which can eventually lead to a positive reward. |
|||
|
|||
## States |
|||
* States should include all variables relevant to allowing the agent to take the optimally informed decision. |
|||
* Categorical state variables such as type of object (Sword, Shield, Bow) should be encoded in one-hot fashion (ie `3` -> `0, 0, 1`). |
|||
* Rotation information on GameObjects should be recorded as `state.Add(transform.rotation.eulerAngles.y/180.0f-1.0f);` rather than `state.Add(transform.rotation.y);`. |
|||
* Positional information of relevant GameObjects should be encoded in relative coordinates wherever possible. This is often relative to the agent position. |
|||
|
|||
## Actions |
|||
* When using continuous control, action values should be clipped to an appropriate range. |
|||
* Be sure to set the action-space-size to the number of used actions, and not greater, as doing the latter can interfere with the efficency of the training process. |
|||
|
|||
# Installation & Set-up |
|||
|
|||
## Install **Unity 2017.1** or later (required) |
|||
|
|||
Download link available [here](https://store.unity.com/download?ref=update). |
|||
|
|||
## Clone the repository |
|||
Once installed, you will want to clone the Agents GitHub repository. References will be made |
|||
throughout to `unity-environment` and `python` directories. Both are located at the root of the repository. |
|||
|
|||
## Installing Python API |
|||
In order to train an agent within the framework, you will need to install Python 2 or 3, and the dependencies described below. |
|||
|
|||
### Windows Users |
|||
|
|||
If you are a Windows user who is new to Python/TensorFlow, follow [this guide](https://unity3d.college/2017/10/25/machine-learning-in-unity3d-setting-up-the-environment-tensorflow-for-agentml-on-windows-10/) to set up your Python environment. |
|||
|
|||
### Requirements |
|||
* Jupyter |
|||
* Matplotlib |
|||
* numpy |
|||
* Pillow |
|||
* Python (2 or 3; 64bit required) |
|||
* docopt (Training) |
|||
* TensorFlow (1.0+) (Training) |
|||
|
|||
## Docker-based Installation (experimental) |
|||
|
|||
If you’d like to use Docker for ML Agents, please follow [this guide](Using-Docker.md). |
|||
|
|||
### Installing Dependencies |
|||
To install dependencies, go into the `python` sub-directory of the repositroy, and run (depending on your python version) from the command line: |
|||
|
|||
`pip install .` |
|||
|
|||
or |
|||
|
|||
`pip3 install .` |
|||
|
|||
If your Python environment doesn't include `pip`, see these [instructions](https://packaging.python.org/guides/installing-using-linux-tools/#installing-pip-setuptools-wheel-with-linux-package-managers) on installing it. |
|||
|
|||
Once the requirements are successfully installed, the next step is to check out the [Getting Started guide](Getting-Started-with-Balance-Ball.md). |
|||
|
|||
## Installation Help |
|||
|
|||
### Using Jupyter Notebook |
|||
|
|||
For a walkthrough of how to use Jupyter notebook, see [here](http://jupyter-notebook-beginner-guide.readthedocs.io/en/latest/execute.html). |
|||
|
|||
### General Issues |
|||
|
|||
If you run into issues while attempting to install and run Unity ML Agents, see [here](https://github.com/Unity-Technologies/ml-agents/blob/master/docs/Limitations-&-Common-Issues.md) for a list of common issues and solutions. |
|||
|
|||
If you have an issue that isn't covered here, feel free to contact us at ml-agents@unity3d.com. Alternatively, feel free to create an issue on the repository. |
|||
Be sure to include relevant information on OS, Python version, and exact error message if possible. |
|||
|
|||
# Best Practices when training with PPO |
|||
|
|||
The process of training a Reinforcement Learning model can often involve the need to tune the hyperparameters in order to achieve |
|||
a level of performance that is desirable. This guide contains some best practices for tuning the training process when the default |
|||
parameters don't seem to be giving the level of performance you would like. |
|||
|
|||
## Hyperparameters |
|||
|
|||
### Batch Size |
|||
|
|||
`batch_size` corresponds to how many experiences are used for each gradient descent update. This should always be a fraction |
|||
of the `buffer_size`. If you are using a continuous action space, this value should be large (in 1000s). If you are using a discrete action space, this value should be smaller (in 10s). |
|||
|
|||
Typical Range (Continuous): `512` - `5120` |
|||
|
|||
Typical Range (Discrete): `32` - `512` |
|||
|
|||
|
|||
### Beta (Used only in Discrete Control) |
|||
|
|||
`beta` corresponds to the strength of the entropy regularization, which makes the policy "more random." This ensures that discrete action space agents properly explore during training. Increasing this will ensure more random actions are taken. This should be adjusted such that the entropy (measurable from TensorBoard) slowly decreases alongside increases in reward. If entropy drops too quickly, increase `beta`. If entropy drops too slowly, decrease `beta`. |
|||
|
|||
Typical Range: `1e-4` - `1e-2` |
|||
|
|||
### Buffer Size |
|||
|
|||
`buffer_size` corresponds to how many experiences should be collected before gradient descent is performed on them all. |
|||
This should be a multiple of `batch_size`. Typically larger buffer sizes correspond to more stable training updates. |
|||
|
|||
Typical Range: `2048` - `409600` |
|||
|
|||
### Epsilon |
|||
|
|||
`epsilon` corresponds to the acceptable threshold of divergence between the old and new policies during gradient descent updating. Setting this value small will result in more stable updates, but will also slow the training process. |
|||
|
|||
Typical Range: `0.1` - `0.3` |
|||
|
|||
### Hidden Units |
|||
|
|||
`hidden_units` correspond to how many units are in each fully connected layer of the neural network. For simple problems |
|||
where the correct action is a straightforward combination of the state inputs, this should be small. For problems where |
|||
the action is a very complex interaction between the state variables, this should be larger. |
|||
|
|||
Typical Range: `32` - `512` |
|||
|
|||
### Learning Rate |
|||
|
|||
`learning_rate` corresponds to the strength of each gradient descent update step. This should typically be decreased if |
|||
training is unstable, and the reward does not consistently increase. |
|||
|
|||
Typical Range: `1e-5` - `1e-3` |
|||
|
|||
### Number of Epochs |
|||
|
|||
`num_epoch` is the number of passes through the experience buffer during gradient descent. The larger the batch size, the |
|||
larger it is acceptable to make this. Decreasing this will ensure more stable updates, at the cost of slower learning. |
|||
|
|||
Typical Range: `3` - `10` |
|||
|
|||
### Time Horizon |
|||
|
|||
`time_horizon` corresponds to how many steps of experience to collect per-agent before adding it to the experience buffer. |
|||
When this limit is reached before the end of an episode, a value estimate is used to predict the overall expected reward from the agent's current state. |
|||
As such, this parameter trades off between a less biased, but higher variance estimate (long time horizon) and more biased, but less varied estimate (short time horizon). |
|||
In cases where there are frequent rewards within an episode, or episodes are prohibitively large, a smaller number can be more ideal. |
|||
This number should be large enough to capture all the important behavior within a sequence of an agent's actions. |
|||
|
|||
Typical Range: `32` - `2048` |
|||
|
|||
### Max Steps |
|||
|
|||
`max_steps` corresponds to how many steps of the simulation (multiplied by frame-skip) are run durring the training process. This value should be increased for more complex problems. |
|||
|
|||
Typical Range: `5e5 - 1e7` |
|||
|
|||
### Normalize |
|||
|
|||
`normalize` corresponds to whether normalization is applied to the state inputs. This normalization is based on the running average and variance of the states. |
|||
Normalization can be helpful in cases with complex continuous control problems, but may be harmful with simpler discrete control problems. |
|||
|
|||
### Number of Layers |
|||
|
|||
`num_layers` corresponds to how many hidden layers are present after the state input, or after the CNN encoding of the observation. For simple problems, |
|||
fewer layers are likely to train faster and more efficiently. More layers may be necessary for more complex control problems. |
|||
|
|||
Typical range: `1` - `3` |
|||
|
|||
## Training Statistics |
|||
|
|||
To view training statistics, use Tensorboard. For information on launching and using Tensorboard, see [here](./Getting-Started-with-Balance-Ball.md#observing-training-progress). |
|||
|
|||
### Cumulative Reward |
|||
|
|||
The general trend in reward should consistently increase over time. Small ups and downs are to be expected. Depending on the complexity of the task, a significant increase in reward may not present itself until millions of steps into the training process. |
|||
|
|||
### Entropy |
|||
|
|||
This corresponds to how random the decisions of a brain are. This should consistently decrease during training. If it decreases too soon or not at all, `beta` should be adjusted (when using discrete action space). |
|||
|
|||
### Learning Rate |
|||
|
|||
This will decrease over time on a linear schedule. |
|||
|
|||
### Policy Loss |
|||
|
|||
These values will oscillate with training. |
|||
|
|||
### Value Estimate |
|||
|
|||
These values should increase with the reward. They corresponds to how much future reward the agent predicts itself receiving at any given point. |
|||
|
|||
### Value Loss |
|||
|
|||
These values will increase as the reward increases, and should decrease when reward becomes stable. |
|||
|
|||
# Training with Curriculum Learning |
|||
|
|||
## Background |
|||
|
|||
Curriculum learning is a way of training a machine learning model where more difficult |
|||
aspects of a problem are gradually introduced in such a way that the model is always |
|||
optimally challenged. Here is a link to the original paper which introduces the ideal |
|||
formally. More generally, this idea has been around much longer, for it is how we humans |
|||
typically learn. If you imagine any childhood primary school education, there is an |
|||
ordering of classes and topics. Arithmetic is taught before algebra, for example. |
|||
Likewise, algebra is taught before calculus. The skills and knowledge learned in the |
|||
earlier subjects provide a scaffolding for later lessons. The same principle can be |
|||
applied to machine learning, where training on easier tasks can provide a scaffolding |
|||
for harder tasks in the future. |
|||
|
|||
 |
|||
|
|||
_Example of a mathematics curriculum. Lessons progress from simpler topics to more |
|||
complex ones, with each building on the last._ |
|||
|
|||
When we think about how Reinforcement Learning actually works, the primary learning |
|||
signal is a scalar reward received occasionally throughout training. In more complex |
|||
or difficult tasks, this reward can often be sparse, and rarely achieved. For example, |
|||
imagine a task in which an agent needs to scale a wall to arrive at a goal. The starting |
|||
point when training an agent to accomplish this task will be a random policy. That |
|||
starting policy will have the agent running in circles, and will likely never, or very |
|||
rarely scale the wall properly to the achieve the reward. If we start with a simpler |
|||
task, such as moving toward an unobstructed goal, then the agent can easily learn to |
|||
accomplish the task. From there, we can slowly add to the difficulty of the task by |
|||
increasing the size of the wall, until the agent can complete the initially |
|||
near-impossible task of scaling the wall. We are including just such an environment with |
|||
ML-Agents 0.2, called Wall Area. |
|||
|
|||
 |
|||
|
|||
_Demonstration of a curriculum training scenario in which a progressively taller wall |
|||
obstructs the path to the goal._ |
|||
|
|||
To see this in action, observe the two learning curves below. Each displays the reward |
|||
over time for an agent trained using PPO with the same set of training hyperparameters. |
|||
The difference is that the agent on the left was trained using the full-height wall |
|||
version of the task, and the right agent was trained using the curriculum version of |
|||
the task. As you can see, without using curriculum learning the agent has a lot of |
|||
difficulty. We think that by using well-crafted curricula, agents trained using |
|||
reinforcement learning will be able to accomplish tasks otherwise much more difficult. |
|||
|
|||
 |
|||
|
|||
## How-To |
|||
|
|||
So how does it work? In order to define a curriculum, the first step is to decide which |
|||
parameters of the environment will vary. In the case of the Wall Area environment, what |
|||
varies is the height of the wall. We can define this as a reset parameter in the Academy |
|||
object of our scene, and by doing so it becomes adjustable via the Python API. Rather |
|||
than adjusting it by hand, we then create a simple JSON file which describes the |
|||
structure of the curriculum. Within it we can set at what points in the training process |
|||
our wall height will change, either based on the percentage of training steps which have |
|||
taken place, or what the average reward the agent has received in the recent past is. |
|||
Once these are in place, we simply launch ppo.py using the `–curriculum-file` flag to |
|||
point to the JSON file, and PPO we will train using Curriculum Learning. Of course we can |
|||
then keep track of the current lesson and progress via TensorBoard. |
|||
|
|||
|
|||
```json |
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5], |
|||
"min_lesson_length" : 2, |
|||
"signal_smoothing" : true, |
|||
"parameters" : |
|||
{ |
|||
"min_wall_height" : [0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5], |
|||
"max_wall_height" : [1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0] |
|||
} |
|||
} |
|||
``` |
|||
|
|||
* `measure` - What to measure learning progress, and advancement in lessons by. |
|||
* `reward` - Uses a measure received reward. |
|||
* `progress` - Uses ratio of steps/max_steps. |
|||
* `thresholds` (float array) - Points in value of `measure` where lesson should be increased. |
|||
* `min_lesson_length` (int) - How many times the progress measure should be reported before |
|||
incrementing the lesson. |
|||
* `signal_smoothing` (true/false) - Whether to weight the current progress measure by previous values. |
|||
* If `true`, weighting will be 0.75 (new) 0.25 (old). |
|||
* `parameters` (dictionary of key:string, value:float array) - Corresponds to academy reset parameters to control. Length of each array |
|||
should be one greater than number of thresholds. |
|||
|
|||
# How to Instantiate and Destroy Agents |
|||
|
|||
In Unity, you can instantiate and destroy game objects but it can be tricky if this game object has an Agent component attached. |
|||
|
|||
_Notice: This feature is still experimental._ |
|||
|
|||
## Instantiating an Agent |
|||
You will need another game object or agent to instantiate your agent. First you will need a prefab of the agent to instantiate it. You can use `Resource.Load()` or use a `public GameObject` field and drag your prefab into it. You must be careful to give a brain to the agent prefab. A lot of methods require the agent to have a brain, not having one can cause issues very rapidly. Fortunately, you can use the method `GiveBrain()` of the Agent to give it a brain. You should also call `AgentReset()` on this newly born agent so it will get the same start in life as his friends. |
|||
|
|||
```csharp |
|||
agentPrefab.GetComponentInChildren<Agent>().GiveBrain(brain); |
|||
GameObject newAgent = Instantiate(agentPrefab); |
|||
agentPrefab.GetComponentInChildren<Agent>().RemoveBrain(); |
|||
newAgent.GetComponentInChildren<Agent>().AgentReset(); |
|||
``` |
|||
|
|||
Note that it is possible to generate an agent inside the `AgentStep()` method of an agent. Be careful, since the new agent could also create a new agent leading to an infinite loop. |
|||
|
|||
## Destroying an Agent |
|||
Try not to destroy an agent by simply using `Destroy()`. This will confuse the learning process as the Brain will not know that the agent was terminated. The proper way to kill an agent is to set his done flag to `true` and make use of the `AgentOnDone()` method. |
|||
In the default case, the agent resets when done but you can change this behavior. If you **uncheck** the `Reset On Done` checkbox of the agent, the agent will not reset and call instead `AgentOnDone()`. You must now implement the method `AgentOnDone()` as follows : |
|||
|
|||
```csharp |
|||
public override void AgentOnDone() |
|||
{ |
|||
Destroy(gameObject); |
|||
} |
|||
``` |
|||
This is the simplest case where you want the agent to be destroyed, but you can also do plenty of other things such as making and explosion, warn nearby agents, instantiate a zombie agent etc. |
|||
|
|||
# Example Learning Environments |
|||
|
|||
### About Example Environments |
|||
Unity ML Agents contains a set of example environments which demonstrate various features of the platform. In the coming months more will be added. We are also actively open to adding community contributed environments as examples, as long as they are small, simple, demonstrate a unique feature of the platform, and provide a unique non-trivial challenge to modern RL algorithms. Feel free to submit these environments with a Pull-Request explaining the nature of the environment and task. |
|||
|
|||
Environments are located in `unity-environment/ML-Agents/Examples`. |
|||
|
|||
## Basic |
|||
|
|||
* Set-up: A linear movement task where the agent must move left or right to rewarding states. |
|||
* Goal: Move to the most reward state. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* +0.1 for arriving at suboptimal state. |
|||
* +1.0 for arriving at optimal state. |
|||
* Brains: One brain with the following observation/action space. |
|||
* State space: (Discrete) One variable corresponding to current state. |
|||
* Action space: (Discrete) Two possible actions (Move left, move right). |
|||
* Visual Observations: 0 |
|||
* Reset Parameters: None |
|||
|
|||
## 3DBall |
|||
|
|||
 |
|||
|
|||
* Set-up: A balance-ball task, where the agent controls the platform. |
|||
* Goal: The agent must balance the platform in order to keep the ball on it for as long as possible. |
|||
* Agents: The environment contains 12 agents of the same kind, all linked to a single brain. |
|||
* Agent Reward Function: |
|||
* +0.1 for every step the ball remains on the platform. |
|||
* -1.0 if the ball falls from the platform. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: (Continuous) 8 variables corresponding to rotation of platform, and position, rotation, and velocity of ball. |
|||
* Observation space (Hard Version): (Continuous) 5 variables corresponding to rotation of platform and position and rotation of ball. |
|||
* Action space: (Continuous) Size of 2, with one value corresponding to X-rotation, and the other to Z-rotation. |
|||
* Visual Observations: 0 |
|||
* Reset Parameters: None |
|||
|
|||
## GridWorld |
|||
|
|||
 |
|||
|
|||
* Set-up: A version of the classic grid-world task. Scene contains agent, goal, and obstacles. |
|||
* Goal: The agent must navigate the grid to the goal while avoiding the obstacles. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* -0.01 for every step. |
|||
* +1.0 if the agent navigates to the goal position of the grid (episode ends). |
|||
* -1.0 if the agent navigates to an obstacle (episode ends). |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: None |
|||
* Action space: (Discrete) Size of 4, corresponding to movement in cardinal directions. |
|||
* Visual Observations: One corresponding to top-down view of GridWorld. |
|||
* Reset Parameters: Three, corresponding to grid size, number of obstacles, and number of goals. |
|||
|
|||
|
|||
## Tennis |
|||
|
|||
 |
|||
|
|||
* Set-up: Two-player game where agents control rackets to bounce ball over a net. |
|||
* Goal: The agents must bounce ball between one another while not dropping or sending ball out of bounds. |
|||
* Agents: The environment contains two agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +0.1 To agent when hitting ball over net. |
|||
* -0.1 To agent who let ball hit their ground, or hit ball out of bounds. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: (Continuous) 8 variables corresponding to position and velocity of ball and racket. |
|||
* Action space: (Continuous) Size of 2, corresponding to movement toward net or away from net, and jumping. |
|||
* Visual Observations: None |
|||
* Reset Parameters: One, corresponding to size of ball. |
|||
|
|||
## Area |
|||
|
|||
### Push Area |
|||
|
|||
 |
|||
|
|||
* Set-up: A platforming environment where the agent can push a block around. |
|||
* Goal: The agent must push the block to the goal. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* -0.01 for every step. |
|||
* +1.0 if the block touches the goal. |
|||
* -1.0 if the agent falls off the platform. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: (Continuous) 15 variables corresponding to position and velocities of agent, block, and goal. |
|||
* Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement. |
|||
* Visual Observations: None. |
|||
* Reset Parameters: One, corresponding to number of steps in training. Used to adjust size of elements for Curriculum Learning. |
|||
|
|||
### Wall Area |
|||
|
|||
 |
|||
|
|||
* Set-up: A platforming environment where the agent can jump over a wall. |
|||
* Goal: The agent must use the block to scale the wall and reach the goal. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function: |
|||
* -0.01 for every step. |
|||
* +1.0 if the agent touches the goal. |
|||
* -1.0 if the agent falls off the platform. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: (Continuous) 16 variables corresponding to position and velocities of agent, block, and goal, plus the height of the wall. |
|||
* Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement. |
|||
* Visual Observations: None. |
|||
* Reset Parameters: One, corresponding to number of steps in training. Used to adjust size of the wall for Curriculum Learning. |
|||
|
|||
## Reacher |
|||
|
|||
 |
|||
|
|||
* Set-up: Double-jointed arm which can move to target locations. |
|||
* Goal: The agents must move it's hand to the goal location, and keep it there. |
|||
* Agents: The environment contains 32 agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +0.1 Each step agent's hand is in goal location. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: (Continuous) 26 variables corresponding to position, rotation, velocity, and angular velocities of the two arm rigidbodies. |
|||
* Action space: (Continuous) Size of 4, corresponding to torque applicable to two joints. |
|||
* Visual Observations: None |
|||
* Reset Parameters: Two, corresponding to goal size, and goal movement speed. |
|||
|
|||
## Crawler |
|||
|
|||
 |
|||
|
|||
* Set-up: A creature with 4 arms and 4 forearms. |
|||
* Goal: The agents must move its body along the x axis without falling. |
|||
* Agents: The environment contains 3 agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +1 times velocity in the x direction |
|||
* -1 for falling. |
|||
* -0.01 times the action squared |
|||
* -0.05 times y position change |
|||
* -0.05 times velocity in the z direction |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: (Continuous) 117 variables corresponding to position, rotation, velocity, and angular velocities of each limb plus the acceleration and angular acceleration of the body. |
|||
* Action space: (Continuous) Size of 12, corresponding to torque applicable to 12 joints. |
|||
* Visual Observations: None |
|||
* Reset Parameters: None |
|||
|
|||
## Banana Collector |
|||
|
|||
 |
|||
|
|||
* Set-up: A multi-agent environment where agents compete to collect bananas. |
|||
* Goal: The agents must learn to move to as many yellow bananas as possible while avoiding red bananas. |
|||
* Agents: The environment contains 10 agents linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +1 for interaction with yellow banana |
|||
* -1 for interaction with red banana. |
|||
* Brains: One brain with the following observation/action space. |
|||
* Observation space: (Continuous) 51 corresponding to velocity of agent, plus ray-based perception of objects around agent's forward direction. |
|||
* Action space: (Continuous) Size of 3, corresponding to forward movement, y-axis rotation, and whether to use laser to disable other agents. |
|||
* Visual Observations (Optional): First-person view for each agent. |
|||
* Reset Parameters: None |
|||
|
|||
## Hallway |
|||
|
|||
 |
|||
|
|||
* Set-up: Environment where the agent needs to find information in a room, remeber it, and use it to move to the correct goal. |
|||
* Goal: Move to the goal which corresponds to the color of the block in the room. |
|||
* Agents: The environment contains one agent linked to a single brain. |
|||
* Agent Reward Function (independent): |
|||
* +1 For moving to correct goal. |
|||
* -0.1 For moving to incorrect goal. |
|||
* -0.0003 Existential penalty. |
|||
* Brains: One brain with the following observation/action space: |
|||
* Observation space: (Continuous) 30 corresponding to local ray-casts detecting objects, goals, and walls. |
|||
* Action space: (Continuous) 4 corresponding to agent rotation and forward/backward movement. |
|||
* Visual Observations (Optional): First-person view for the agent. |
|||
* Reset Parameters: None |
|||
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
|||
 |
|||
|
|||
# Unity ML - Agents (Python API) |
|||
|
|||
## Python Setup |
|||
|
|||
### Requirements |
|||
* Jupyter |
|||
* docopt |
|||
* Matplotlib |
|||
* numpy |
|||
* Pillow |
|||
* Python (2 or 3) |
|||
* Tensorflow (1.0+) |
|||
|
|||
### Installing Dependencies |
|||
To install dependencies, run: |
|||
|
|||
`pip install .` |
|||
|
|||
or |
|||
|
|||
`pip3 install .` |
|||
|
|||
If your Python environment doesn't include `pip`, see these [instructions](https://packaging.python.org/guides/installing-using-linux-tools/#installing-pip-setuptools-wheel-with-linux-package-managers) on installing it. |
|||
|
|||
## Provided Jupyter Notebooks |
|||
|
|||
* **Basic** - Demonstrates usage of `UnityEnvironment` class for launching and interfacing with Unity Environments. |
|||
* **PPO** - Used for training agents. Contains an implementation of Proximal Policy Optimization Reinforcement Learning algorithm. |
|||
|
|||
### Running each notebook |
|||
|
|||
To launch jupyter, run: |
|||
|
|||
`jupyter notebook` |
|||
|
|||
Then navigate to `localhost:8888` to access each training notebook. |
|||
|
|||
To monitor training progress, run the following from the root directory of this repo: |
|||
|
|||
`tensorboard --logdir=summaries` |
|||
|
|||
Then navigate to `localhost:6006` to monitor progress with Tensorboard. |
|||
|
|||
## Training PPO directly |
|||
|
|||
To train using PPO without the notebook, run: `python3 ppo.py <env_name> --train` |
|||
|
|||
Where `<env_name>` corresponds to the name of the built Unity environment. |
|||
|
|||
For a list of additional hyperparameters, run: `python3 ppo.py --help` |
|||
|
|||
## Using Python API |
|||
See this [documentation](../docs/Unity-Agents---Python-API.md) for a detailed description of the functions and uses of the Python API. |
|||
|
|||
## Training on AWS |
|||
See this related [blog post](https://medium.com/towards-data-science/how-to-run-unity-on-amazon-cloud-or-without-monitor-3c10ce022639) for a description of how to run Unity Environments on AWS EC2 instances with the GPU. |
|||
|
|||
# Unity ML - Agents (Editor SDK) |
|||
|
|||
 |
|||
|
|||
## Unity Setup |
|||
Make sure you have Unity 2017.1 or later installed. Download link available [here](https://store.unity.com/download?ref=update). |
|||
|
|||
### Building a Unity Environment |
|||
- (1) Open the project in the Unity editor *(If this is not first time running Unity, you'll be able to skip most of these immediate steps, choose directly from the list of recently opened projects and jump directly to )* |
|||
- On the initial dialog, choose `Open` on the top options |
|||
- On the file dialog, choose `ProjectName` and click `Open` *(It is safe to ignore any warning message about non-matching editor installation")* |
|||
- Once the project is open, on the `Project` panel (bottom of the tool), click the top folder for `Assets` |
|||
- Double-click the scene icon (Unity logo) to load all game assets |
|||
- (2) *File -> Build Settings* |
|||
- (3) Choose your target platform: |
|||
- (opt) Select “Developer Build” to log debug messages. |
|||
- (4) Set architecture: `X86_64` |
|||
- (5) Click *Build*: |
|||
- Save environment binary to a sub-directory containing the model to use for training *(you may need to click on the down arrow on the file chooser to be able to select that folder)* |
|||
|
|||
## Example Projects |
|||
The `Examples` subfolder contains a set of example environments to use either as starting points or templates for designing your own environments. |
|||
* **3DBalanceBall** - Physics-based game where the agent must rotate a 3D-platform to keep a ball in the air. Supports both discrete and continuous control. |
|||
* **GridWorld** - A simple gridworld containing regions which provide positive and negative reward. The agent must learn to move to the rewarding regions (green) and avoid the negatively rewarding ones (red). Supports discrete control. |
|||
* **Tennis** - An adversarial game where two agents control rackets, which must be used to bounce a ball back and forth between them. Supports continuous control. |
|||
|
|||
For more informoation on each of these environments, see this [documentation page](../docs/Example-Environments.md). |
|||
|
|||
Within `ML-Agents/Template` there also exists: |
|||
* **Template** - An empty Unity scene with a single _Academy_, _Brain_, and _Agent_. Designed to be used as a template for new environments. |
|||
|
|||
## Agents SDK |
|||
A link to Unity package containing the Agents SDK for Unity 2017.1 can be downloaded here : |
|||
* [ML-Agents package without TensorflowSharp](https://s3.amazonaws.com/unity-agents/0.2/ML-AgentsNoPlugin.unitypackage) |
|||
* [ML-Agents package with TensorflowSharp](https://s3.amazonaws.com/unity-agents/0.2/ML-AgentsWithPlugin.unitypackage) |
|||
|
|||
For information on the use of each script, see the comments and documentation within the files themselves, or read the [documentation](../../../wiki). |
|||
|
|||
## Creating your own Unity Environment |
|||
For information on how to create a new Unity Environment, see the walkthrough [here](../docs/Making-a-new-Unity-Environment.md). If you have questions or run into issues, please feel free to create issues through the repo, and we will do our best to address them. |
|||
|
|||
## Embedding Models with TensorflowSharp _[Experimental]_ |
|||
If you will be using Tensorflow Sharp in Unity, you must: |
|||
|
|||
1. Make sure you are using Unity 2017.1 or newer. |
|||
2. Make sure the TensorflowSharp [plugin](https://s3.amazonaws.com/unity-agents/0.2/TFSharpPlugin.unitypackage) is in your Asset folder. |
|||
3. Go to `Edit` -> `Project Settings` -> `Player` |
|||
4. For each of the platforms you target (**`PC, Mac and Linux Standalone`**, **`iOS`** or **`Android`**): |
|||
1. Go into `Other Settings`. |
|||
2. Select `Scripting Runtime Version` to `Experimental (.NET 4.6 Equivalent)` |
|||
3. In `Scripting Defined Symbols`, add the flag `ENABLE_TENSORFLOW` |
|||
5. Restart the Unity Editor. |
|||
部分文件因为文件数量过多而无法显示
撰写
预览
正在加载...
取消
保存
Reference in new issue