浏览代码
Merge branch 'development-0.3' into dev-api-doc-academy
Merge branch 'development-0.3' into dev-api-doc-academy
# Conflicts: # unity-environment/Assets/ML-Agents/Editor/MLAgentsEditModeTest.cs # unity-environment/Assets/ML-Agents/Examples/Basic/Scripts/BasicAgent.cs # unity-environment/Assets/ML-Agents/Scripts/Academy.cs/develop-generalizationTraining-TrainerController
当前提交
ba6911c3
共有 60 个文件被更改,包括 3204 次插入 和 2451 次删除
-
18docs/ML-Agents-Overview.md
-
1docs/Readme.md
-
2python/unitytrainers/ppo/trainer.py
-
22unity-environment/Assets/ML-Agents/Editor/AgentEditor.cs
-
50unity-environment/Assets/ML-Agents/Editor/BrainEditor.cs
-
2unity-environment/Assets/ML-Agents/Editor/MLAgentsEditModeTest.cs
-
34unity-environment/Assets/ML-Agents/Examples/3DBall/Scripts/Ball3DDecision.cs
-
18unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Area.cs
-
34unity-environment/Assets/ML-Agents/Examples/Area/Scripts/AreaAgent.cs
-
14unity-environment/Assets/ML-Agents/Examples/Area/Scripts/AreaDecision.cs
-
2unity-environment/Assets/ML-Agents/Examples/Area/Scripts/GoalInteract.cs
-
12unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Push/PushAcademy.cs
-
42unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Push/PushAgent.cs
-
24unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Push/PushArea.cs
-
10unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Wall/WallAcademy.cs
-
46unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Wall/WallAgent.cs
-
24unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Wall/WallArea.cs
-
4unity-environment/Assets/ML-Agents/Examples/Banana/Scripts/BananaAgent.cs
-
18unity-environment/Assets/ML-Agents/Examples/Banana/Scripts/BananaLogic.cs
-
12unity-environment/Assets/ML-Agents/Examples/Basic/Scripts/BasicAcademy.cs
-
12unity-environment/Assets/ML-Agents/Examples/Bouncer/Scripts/BouncerAcademy.cs
-
22unity-environment/Assets/ML-Agents/Examples/Bouncer/Scripts/BouncerAgent.cs
-
8unity-environment/Assets/ML-Agents/Examples/Bouncer/Scripts/BouncerBanana.cs
-
22unity-environment/Assets/ML-Agents/Examples/Crawler/Scripts/CameraFollow.cs
-
114unity-environment/Assets/ML-Agents/Examples/GridWorld/GridWorld.unity
-
993unity-environment/Assets/ML-Agents/Examples/GridWorld/TFModels/GridWorld_3x3.bytes
-
6unity-environment/Assets/ML-Agents/Examples/GridWorld/TFModels/GridWorld_3x3.bytes.meta
-
977unity-environment/Assets/ML-Agents/Examples/GridWorld/TFModels/GridWorld_5x5.bytes
-
6unity-environment/Assets/ML-Agents/Examples/GridWorld/TFModels/GridWorld_5x5.bytes.meta
-
14unity-environment/Assets/ML-Agents/Examples/Hallway/Scripts/HallwayAcademy.cs
-
51unity-environment/Assets/ML-Agents/Examples/Hallway/Scripts/HallwayAgent.cs
-
152unity-environment/Assets/ML-Agents/Examples/Reacher/Scene.unity
-
22unity-environment/Assets/ML-Agents/Examples/Reacher/Scripts/FlyCamera.cs
-
12unity-environment/Assets/ML-Agents/Examples/Reacher/Scripts/ReacherAcademy.cs
-
5unity-environment/Assets/ML-Agents/Examples/Reacher/Scripts/ReacherAgent.cs
-
12unity-environment/Assets/ML-Agents/Examples/Reacher/Scripts/ReacherDecision.cs
-
18unity-environment/Assets/ML-Agents/Examples/Reacher/Scripts/ReacherGoal.cs
-
30unity-environment/Assets/ML-Agents/Examples/Tennis/Prefabs/TennisArea.prefab
-
16unity-environment/Assets/ML-Agents/Examples/Tennis/Scripts/TennisArea.cs
-
216unity-environment/Assets/ML-Agents/Examples/Tennis/Scripts/hitWall.cs
-
979unity-environment/Assets/ML-Agents/Examples/Tennis/TFModels/Tennis.bytes
-
6unity-environment/Assets/ML-Agents/Examples/Tennis/TFModels/Tennis.bytes.meta
-
344unity-environment/Assets/ML-Agents/Examples/Tennis/Tennis.unity
-
4unity-environment/Assets/ML-Agents/Scripts/Academy.cs
-
18unity-environment/Assets/ML-Agents/Scripts/Agent.cs
-
14unity-environment/Assets/ML-Agents/Scripts/BCTeacherHelper.cs
-
8unity-environment/Assets/ML-Agents/Scripts/Brain.cs
-
2unity-environment/Assets/ML-Agents/Scripts/Communicator.cs
-
39unity-environment/Assets/ML-Agents/Scripts/CoreBrainHeuristic.cs
-
22unity-environment/Assets/ML-Agents/Scripts/CoreBrainInternal.cs
-
2unity-environment/Assets/ML-Agents/Scripts/CoreBrainPlayer.cs
-
28unity-environment/Assets/ML-Agents/Scripts/Decision.cs
-
2unity-environment/Assets/ML-Agents/Scripts/ExternalCommunicator.cs
-
12unity-environment/Assets/ML-Agents/Template/Scripts/TemplateAcademy.cs
-
20unity-environment/Assets/ML-Agents/Template/Scripts/TemplateAgent.cs
-
2unity-environment/Assets/ML-Agents/Template/Scripts/TemplateDecision.cs
-
37docs/Learning-Environment-On-Demand-Decision.md
-
47docs/Training-LSTM.md
-
911docs/images/ml-agents-LSTM.png
-
61docs/images/ml-agents-ODD.png
993
unity-environment/Assets/ML-Agents/Examples/GridWorld/TFModels/GridWorld_3x3.bytes
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
|
|||
fileFormatVersion: 2 |
|||
guid: 426162c47484e466d8378d2321a5617c |
|||
timeCreated: 1515001510 |
|||
licenseType: Pro |
|||
guid: c9452e7152c084dfeb7db2db89067546 |
|||
timeCreated: 1520389551 |
|||
licenseType: Free |
|||
TextScriptImporter: |
|||
externalObjects: {} |
|||
userData: |
|||
977
unity-environment/Assets/ML-Agents/Examples/GridWorld/TFModels/GridWorld_5x5.bytes
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
|
|||
fileFormatVersion: 2 |
|||
guid: 69bc5a8ff4f4b465b8b374d88541c8bd |
|||
timeCreated: 1517599883 |
|||
licenseType: Pro |
|||
guid: 5cf779dc0ed064c7080b9f4a3bfffed8 |
|||
timeCreated: 1520389566 |
|||
licenseType: Free |
|||
TextScriptImporter: |
|||
externalObjects: {} |
|||
userData: |
|||
979
unity-environment/Assets/ML-Agents/Examples/Tennis/TFModels/Tennis.bytes
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
|
|||
fileFormatVersion: 2 |
|||
guid: 57cd436ad0d12422ba379708e135815b |
|||
timeCreated: 1516054446 |
|||
licenseType: Pro |
|||
guid: c428950472279436d97dd5fa123febc4 |
|||
timeCreated: 1520386972 |
|||
licenseType: Free |
|||
TextScriptImporter: |
|||
externalObjects: {} |
|||
userData: |
|||
|
|||
# On Demand Decision Making |
|||
|
|||
## Description |
|||
On demand decision making allows agents to request decisions from their |
|||
brains only when needed instead of requesting decisions at a fixed |
|||
frequency. This is useful when the agents commit to an action for a |
|||
variable number of steps or when the agents cannot make decisions |
|||
at the same time. This typically the case for turn based games, games |
|||
where agents must react to events or games where agents can take |
|||
actions of variable duration. |
|||
|
|||
## How to use |
|||
|
|||
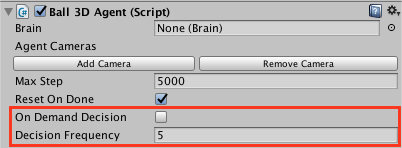
In the agent inspector, there is a checkbox called |
|||
`On Demand Decision` |
|||
|
|||
 |
|||
|
|||
* If `On Demand Decision` is not checked, all the agents will |
|||
request a new decision every `Decision Frequency` steps and |
|||
perform an action every step. In the example above, |
|||
`CollectObservations()` will be called every 5 steps and |
|||
`AgentAct()` will be called at every step. This means that the |
|||
agent will reuse the decision the brain has given it. |
|||
|
|||
* If `On Demand Decision` is checked, you are in charge of telling |
|||
the agent when to request a decision and when to request an action. |
|||
To do so, call the following methods on your agent component. |
|||
* `RequestDecision()` Call this method to signal the agent that it |
|||
must collect its observations and ask the brain for a decision at |
|||
the next step of the simulation. Note that when an agent requests |
|||
a decision, it will also request an action automatically |
|||
(This is to ensure that all decisions lead to an action during training) |
|||
* `RequestAction()` Call this method to signal the agent that |
|||
it must reuse its previous action at the next step of the |
|||
simulation. The Agent will not ask the brain for a new decision, |
|||
it will just call `AgentAct()` with the same action. |
|||
|
|||
# Using Recurrent Neural Network in ML-Agents |
|||
|
|||
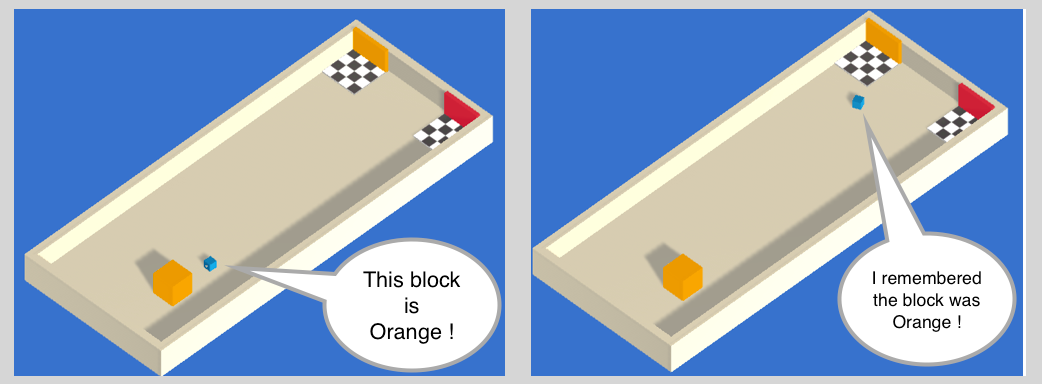
## What are memories for? |
|||
Have you ever entered a room to get something and immediately forgot |
|||
what you were looking for? Don't let that happen to |
|||
your agents. |
|||
|
|||
It is now possible to give memories to your agents. When training, the |
|||
agents will be able to store a vector of floats to be used next time |
|||
they need to make a decision. |
|||
|
|||
 |
|||
|
|||
Deciding what the agents should remember in order to solve a task is not |
|||
easy to do by hand, but our training algorithms can learn to keep |
|||
track of what is important to remember with [LSTM](https://en.wikipedia.org/wiki/Long_short-term_memory). |
|||
|
|||
## How to use |
|||
When configuring the trainer parameters in the `trainer_config.yaml` |
|||
file, add the following parameters to the Brain you want to use. |
|||
|
|||
``` |
|||
use_recurrent: true |
|||
sequence_length: 64 |
|||
memory_size: 256 |
|||
``` |
|||
|
|||
* `use_recurent` is a flag that notifies the trainer that you want |
|||
to use a Recurrent Neural Network. |
|||
* `sequence_length` defines how long the sequences of experiences |
|||
must be while training. In order to use a LSTM, training requires |
|||
a sequence of experiences instead of single experiences. |
|||
* `memory_size` corresponds to the size of the memory the agent |
|||
must keep. Note that if this number is too small, the agent will not |
|||
be able to remember a lot of things. If this number is too large, |
|||
the neural network will take longer to train. |
|||
|
|||
## Limitations |
|||
* LSTM does not work well with continuous vector action space. |
|||
Please use discrete vector action space for better results. |
|||
* Since the memories must be sent back and forth between python |
|||
and Unity, using too large `memory_size` will slow down training. |
|||
* Adding a recurrent layer increases the complexity of the neural |
|||
network, it is recommended to decrease `num_layers` when using recurrent. |
|||
* It is required that `memory_size` be divisible by 4. |
|||
|
|||
|
|||
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 1042 | 高度: 384 | 大小: 216 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 402 | 高度: 148 | 大小: 17 KiB |
撰写
预览
正在加载...
取消
保存
Reference in new issue