浏览代码
Merge pull request #461 from Unity-Technologies/dev-doc-fixes
Merge pull request #461 from Unity-Technologies/dev-doc-fixes
Several documentation enhancements/develop-generalizationTraining-TrainerController
当前提交
aff0ba28
共有 21 个文件被更改,包括 172 次插入 和 3180 次删除
-
4README.md
-
2docs/Feature-Memory.md
-
4docs/Getting-Started-with-Balance-Ball.md
-
12docs/Installation.md
-
23docs/Learning-Environment-Create-New.md
-
35docs/Learning-Environment-Design-Agents.md
-
19docs/Learning-Environment-Design-Brains.md
-
2docs/Limitations-and-Common-Issues.md
-
18docs/ML-Agents-Overview.md
-
5docs/Python-API.md
-
7docs/Readme.md
-
2docs/Training-Imitation-Learning.md
-
4docs/Training-ML-Agents.md
-
2docs/Training-on-Amazon-Web-Service.md
-
136docs/images/agent.png
-
1001docs/images/mlagents-3DBall.png
-
1001docs/images/mlagents-Scene.png
-
841docs/images/agents_diagram.png
-
176docs/images/ml-agents-ODD.png
-
19docs/Feature-Broadcasting.md
-
39docs/Feature-On-Demand-Decisions.md
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
| 宽度: 526 | 高度: 160 | 大小: 20 KiB |
1001
docs/images/mlagents-3DBall.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
1001
docs/images/mlagents-Scene.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
|
|||
# Using the Broadcast Feature |
|||
|
|||
The Player, Heuristic and Internal brains have been updated to support broadcast. The broadcast feature allows you to collect data from your agents using a Python program without controlling them. |
|||
|
|||
## How to use : Unity |
|||
|
|||
To turn it on in Unity, simply check the `Broadcast` box as shown bellow: |
|||
|
|||
 |
|||
|
|||
## How to use : Python |
|||
|
|||
When you launch your Unity Environment from a Python program, you can see what the agents connected to non-external brains are doing. When calling `step` or `reset` on your environment, you retrieve a dictionary mapping brain names to `BrainInfo` objects. The dictionary contains a `BrainInfo` object for each non-external brain set to broadcast as well as for any external brains. |
|||
|
|||
Just like with an external brain, the `BrainInfo` object contains the fields for `visual_observations`, `vector_observations`, `text_observations`, `memories`,`rewards`, `local_done`, `max_reached`, `agents` and `previous_actions`. Note that `previous_actions` corresponds to the actions that were taken by the agents at the previous step, not the current one. |
|||
|
|||
Note that when you do a `step` on the environment, you cannot provide actions for non-external brains. If there are no external brains in the scene, simply call `step()` with no arguments. |
|||
|
|||
You can use the broadcast feature to collect data generated by Player, Heuristics or Internal brains game sessions. You can then use this data to train an agent in a supervised context. |
|||
|
|||
# On Demand Decision Making |
|||
|
|||
## Description |
|||
On demand decision making allows agents to request decisions from their |
|||
brains only when needed instead of receiving decisions at a fixed |
|||
frequency. This is useful when the agents commit to an action for a |
|||
variable number of steps or when the agents cannot make decisions |
|||
at the same time. This typically the case for turn based games, games |
|||
where agents must react to events or games where agents can take |
|||
actions of variable duration. |
|||
|
|||
## How to use |
|||
|
|||
To enable or disable on demand decision making, use the checkbox called |
|||
`On Demand Decisions` in the Agent Inspector. |
|||
|
|||
<p align="center"> |
|||
<img src="images/ml-agents-ODD.png" |
|||
alt="On Demand Decision" |
|||
width="500" border="10" /> |
|||
</p> |
|||
|
|||
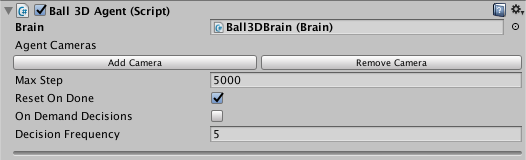
* If `On Demand Decisions` is not checked, the Agent will request a new |
|||
decision every `Decision Frequency` steps and |
|||
perform an action every step. In the example above, |
|||
`CollectObservations()` will be called every 5 steps and |
|||
`AgentAction()` will be called at every step. This means that the |
|||
Agent will reuse the decision the Brain has given it. |
|||
|
|||
* If `On Demand Decisions` is checked, the Agent controls when to receive |
|||
decisions, and take actions. To do so, the Agent may leverage one or two methods: |
|||
* `RequestDecision()` Signals that the Agent is requesting a decision. |
|||
This causes the Agent to collect its observations and ask the Brain for a |
|||
decision at the next step of the simulation. Note that when an Agent |
|||
requests a decision, it also request an action. |
|||
This is to ensure that all decisions lead to an action during training. |
|||
* `RequestAction()` Signals that the Agent is requesting an action. The |
|||
action provided to the Agent in this case is the same action that was |
|||
provided the last time it requested a decision. |
|||
撰写
预览
正在加载...
取消
保存
Reference in new issue