|
|
|
|
|
|
|
complex behaviors by hand is challenging and prone to errors. |
|
|
|
|
|
|
|
With ML-Agents, it is possible to _train_ the behaviors of such NPCs (called |
|
|
|
**agents**) using a variety of methods. The basic idea is quite simple. We need |
|
|
|
**Agents**) using a variety of methods. The basic idea is quite simple. We need |
|
|
|
to define three entities at every moment of the game (called **environment**): |
|
|
|
|
|
|
|
- **Observations** - what the medic perceives about the environment. |
|
|
|
|
|
|
|
- **Agents** - which is attached to a Unity GameObject (any character within a |
|
|
|
scene) and handles generating its observations, performing the actions it |
|
|
|
receives and assigning a reward (positive / negative) when appropriate. Each |
|
|
|
Agent is linked to a Policy. |
|
|
|
Agent is linked to a Behavior. |
|
|
|
every character in the scene. While each Agent must be linked to a Policy, it is |
|
|
|
every character in the scene. While each Agent must be linked to a Behavior, it is |
|
|
|
the same Policy type. In our sample game, we have two teams each with their own medic. |
|
|
|
the same Behavior. In our sample game, we have two teams each with their own medic. |
|
|
|
but both of these medics can have the same Policy. Note that these two |
|
|
|
medics have the same Policy because their _space_ of observations and |
|
|
|
actions are similar. This does not mean that at each instance they will have |
|
|
|
identical observation and action _values_. In other words, the Policy defines the |
|
|
|
space of all possible observations and actions, while the Agents connected to it |
|
|
|
(in this case the medics) can each have their own, unique observation and action |
|
|
|
values. If we expanded our game to include tank driver NPCs, then the Agent |
|
|
|
attached to those characters cannot share a Policy with the Agent linked to the |
|
|
|
but both of these medics can have the same Behavior. Note that these two |
|
|
|
medics have the same Behavior. This does not mean that at each instance they will have |
|
|
|
identical observation and action _values_. If we expanded our game to include |
|
|
|
tank driver NPCs, then the Agent |
|
|
|
attached to those characters cannot share its Behavior with the Agent linked to the |
|
|
|
medics (medics and drivers have different actions). |
|
|
|
|
|
|
|
<p align="center"> |
|
|
|
|
|
|
|
We have yet to discuss how the ML-Agents toolkit trains behaviors, and what role |
|
|
|
the Python API and External Communicator play. Before we dive into those |
|
|
|
details, let's summarize the earlier components. Each character is attached to |
|
|
|
an Agent, and each Agent has a Policy. The Policy receives observations |
|
|
|
and rewards from the Agent and returns actions. The Academy ensures that all the |
|
|
|
an Agent, and each Agent has a Behavior. The Behavior can be thought as a function |
|
|
|
that receives observations |
|
|
|
and rewards from the Agent and returns actions. The Learning Environment through |
|
|
|
the Academy (not represented in the diagram) ensures that all the |
|
|
|
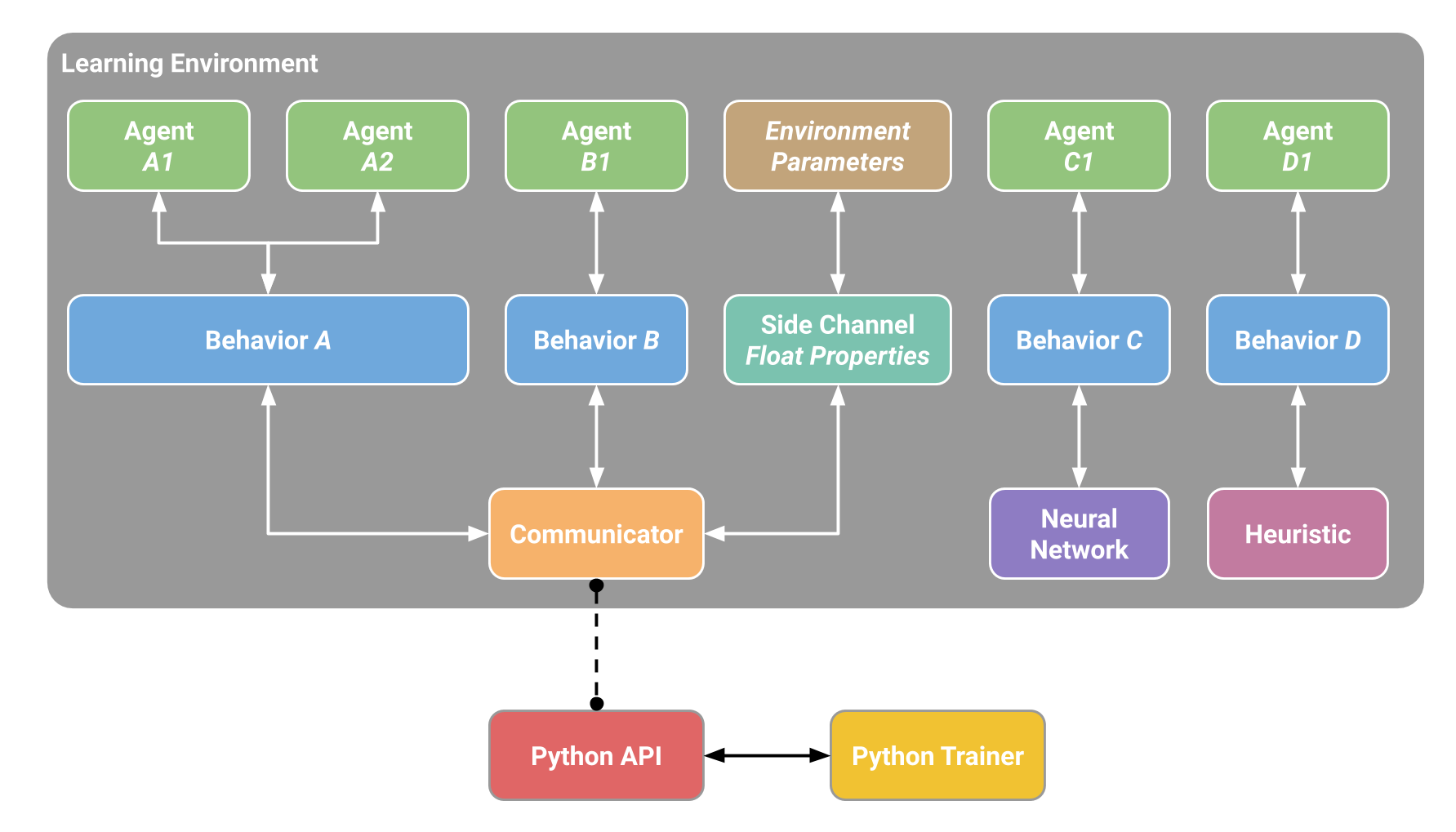
Note that in a single environment, there can be multiple Agents and multiple Behaviors |
|
|
|
at the same time. These Behaviors can communicate with Python through the communicator |
|
|
|
but can also use a pre-trained _Neural Network_ or a _Heuristic_. Note that it is also |
|
|
|
possible to communicate data with Python without using Agents through _Side Channels_. |
|
|
|
One example of using _Side Channels_ is to exchange data with Python about |
|
|
|
_Environment Parameters_. The following diagram illustrates the above. |
|
|
|
|
|
|
|
<p align="center"> |
|
|
|
<img src="images/learning_environment_full.png" |
|
|
|
alt="More Complete Example ML-Agents Scene Block Diagram" |
|
|
|
border="10" /> |
|
|
|
</p> |
|
|
|
|
|
|
|
## Training Modes |
|
|
|
|
|
|
|
|
{kind=link}
{kind=link}
{kind=link}