当前提交
94c20ef0
共有 13 个文件被更改,包括 802 次插入 和 35 次删除
-
8python/curricula/push.json
-
8python/curricula/wall.json
-
4python/ppo.py
-
2python/unityagents/curriculum.py
-
28unity-environment/Assets/ML-Agents/Examples/Area/Scripts/AreaAgent.cs
-
8unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Push/PushAcademy.cs
-
11unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Push/PushAgent.cs
-
15unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Push/PushArea.cs
-
5unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Wall/WallAgent.cs
-
2unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Wall/WallArea.cs
-
85docs/curriculum.md
-
488images/curriculum.png
-
173images/math.png
|
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65], |
|||
"min_lesson_length" : 3, |
|||
"thresholds" : [0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75], |
|||
"min_lesson_length" : 2, |
|||
"object_size" : [2.0, 1.9, 1.8, 1.7, 1.6, 1.5, 1.4, 1.3, 1.2, 1.1] |
|||
"goal_size" : [2.5, 2.4, 2.3, 2.2, 2.1, 2.0, 1.9, 1.8, 1.7, 1.6, 1.5, 1.4, 1.3, 1.2, 1.1, 1.0], |
|||
"block_size": [1.5, 1.4, 1.3, 1.2, 1.1, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], |
|||
"x_variation":[1.0, 1.1, 1.2, 1.3, 1.4, 1.5, 1.6, 1.7, 1.8, 1.9, 2.0, 2.1, 2.2, 2.3, 2.4, 2.5] |
|||
} |
|||
} |
|||
|
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.7, 0.7, 0.7, 0.6, 0.6, 0.6, 0.5, 0.5, 0.5], |
|||
"min_lesson_length" : 3, |
|||
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5], |
|||
"min_lesson_length" : 2, |
|||
"min_wall_height" : [0, 0, 1, 1, 2, 2, 3, 3, 4, 4], |
|||
"max_wall_height" : [0, 1, 1, 2, 2, 3, 3, 4, 4, 5] |
|||
"min_wall_height" : [1, 1, 1, 2, 2, 3, 3, 4, 5], |
|||
"max_wall_height" : [2, 3, 4, 4, 5, 5, 6, 6, 6] |
|||
} |
|||
} |
|||
|
|||
# Curriculum Learning |
|||
|
|||
## Background |
|||
|
|||
Curriculum learning is a way of training a machine learning model where more difficult |
|||
aspects of a problem are gradually introduced in such a way that the model is always |
|||
optimally challenged. Here is a link to the original paper which introduces the ideal |
|||
formally. More generally, this idea has been around much longer, for it is how we humans |
|||
typically learn. If you imagine any childhood primary school education, there is an |
|||
ordering of classes and topics. Arithmetic is taught before algebra, for example. |
|||
Likewise, algebra is taught before calculus. The skills and knowledge learned in the |
|||
earlier subjects provide a scaffolding for later lessons. The same principle can be |
|||
applied to machine learning, where training on easier tasks can provide a scaffolding |
|||
for harder tasks in the future. |
|||
|
|||
[Math](../images/math.png) |
|||
_Example of a mathematics curriculum. Lessons progress from simpler topics to more |
|||
complex ones, with each building on the last._ |
|||
|
|||
When we think about how Reinforcement Learning actually works, the primary learning |
|||
signal is a scalar reward received occasionally throughout training. In more complex |
|||
or difficult tasks, this reward can often be sparse, and rarely achieved. For example, |
|||
imagine a task in which an agent needs to scale a wall to arrive at a goal. The starting |
|||
point when training an agent to accomplish this task will be a random policy. That |
|||
starting policy will have the agent running in circles, and will likely never, or very |
|||
rarely scale the wall properly to the achieve the reward. If we start with a simpler |
|||
task, such as moving toward an unobstructed goal, then the agent can easily learn to |
|||
accomplish the task. From there, we can slowly add to the difficulty of the task by |
|||
increasing the size of the wall, until the agent can complete the initially |
|||
near-impossible task of scaling the wall. We are including just such an environment with |
|||
ML-Agents 0.2, called Wall Area. |
|||
|
|||
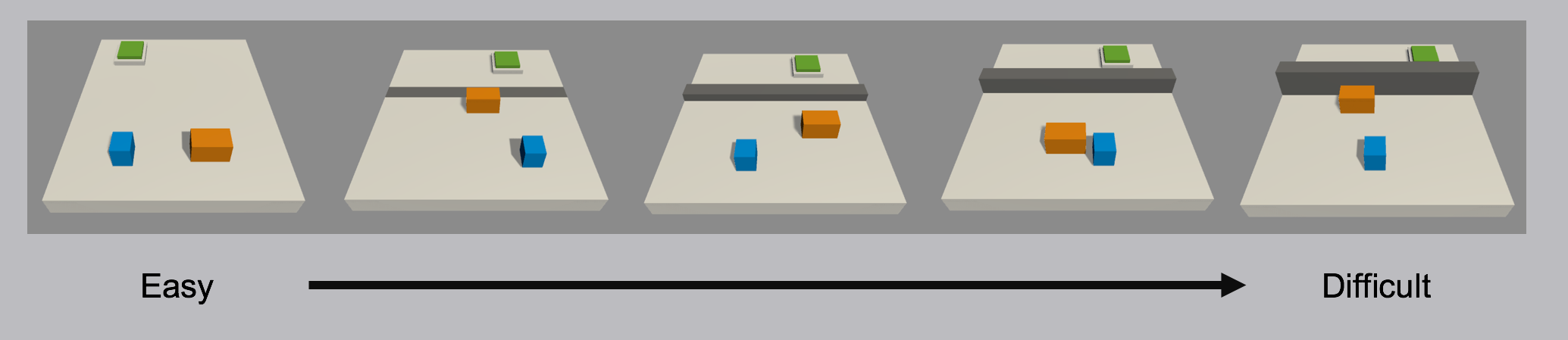
[Wall](../images/curriculum.png) |
|||
_Demonstration of a curriculum training scenario in which a progressively taller wall |
|||
obstructs the path to the goal._ |
|||
|
|||
To see this in action, observe the two learning curves below. Each displays the reward |
|||
over time for an agent trained using PPO with the same set of training hyperparameters. |
|||
The difference is that the agent on the left was trained using the full-height wall |
|||
version of the task, and the right agent was trained using the curriculum version of |
|||
the task. As you can see, without using curriculum learning the agent has a lot of |
|||
difficulty. We think that by using well-crafted curricula, agents trained using |
|||
reinforcement learning will be able to accomplish tasks otherwise much more difficult. |
|||
|
|||
[INSERT TRAINING CURVES] |
|||
|
|||
## How-To |
|||
|
|||
So how does it work? In order to define a curriculum, the first step is to decide which |
|||
parameters of the environment will vary. In the case of the Wall Area environment, what |
|||
varies is the height of the wall. We can define this as a reset parameter in the Academy |
|||
object of our scene, and by doing so it becomes adjustable via the Python API. Rather |
|||
than adjusting it by hand, we then create a simple JSON file which describes the |
|||
structure of the curriculum. Within it we can set at what points in the training process |
|||
our wall height will change, either based on the percentage of training steps which have |
|||
taken place, or what the average reward the agent has received in the recent past is. |
|||
Once these are in place, we simply launch ppo.py using the `–curriculum-file` flag to |
|||
point to the JSON file, and PPO we will train using Curriculum Learning. Of course we can |
|||
then keep track of the current lesson and progress via TensorBoard. |
|||
|
|||
|
|||
``` |
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5], |
|||
"min_lesson_length" : 2, |
|||
"signal_smoothing" : true, |
|||
"parameters" : |
|||
{ |
|||
"min_wall_height" : [1, 1, 1, 2, 2, 3, 3, 4, 5], |
|||
"max_wall_height" : [2, 3, 4, 4, 5, 5, 6, 6, 6] |
|||
} |
|||
} |
|||
``` |
|||
|
|||
* `measure` - What to measure learning progress, and advancement in lessons by. |
|||
* `reward` - Uses a measure received reward. |
|||
* `progress` - Uses ratio of steps/max_steps. |
|||
* `thresholds` (float array) - Points in value of `measure` where lesson should be increased. |
|||
* `min_lesson_length` (int) - How many times the progress measure should be reported before |
|||
incrementing the lesson. |
|||
* `signal_smoothing` (true/false) - Whether to weight the current progress measure by previous values. |
|||
* If `true`, weighting will be 0.75 (new) 0.25 (old). |
|||
* `parameters` (dictionary of key:string, value:float array) - Corresponds to academy reset parameters to control. Length of each array |
|||
should be one greater than number of thresholds. |
|||
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 2069 | 高度: 449 | 大小: 116 KiB |
173
images/math.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
撰写
预览
正在加载...
取消
保存
Reference in new issue