|
|
|
|
|
|
|
from mlagents.envs import AllBrainInfo, BrainInfo |
|
|
|
from mlagents.trainers.buffer import Buffer |
|
|
|
from mlagents.trainers.ppo.policy import PPOPolicy |
|
|
|
from mlagents.trainers.trainer import UnityTrainerException, Trainer |
|
|
|
from mlagents.trainers.trainer import Trainer |
|
|
|
|
|
|
|
logger = logging.getLogger("mlagents.trainers") |
|
|
|
|
|
|
|
|
|
|
|
self.policy = PPOPolicy(seed, brain, trainer_parameters, |
|
|
|
self.is_training, load) |
|
|
|
|
|
|
|
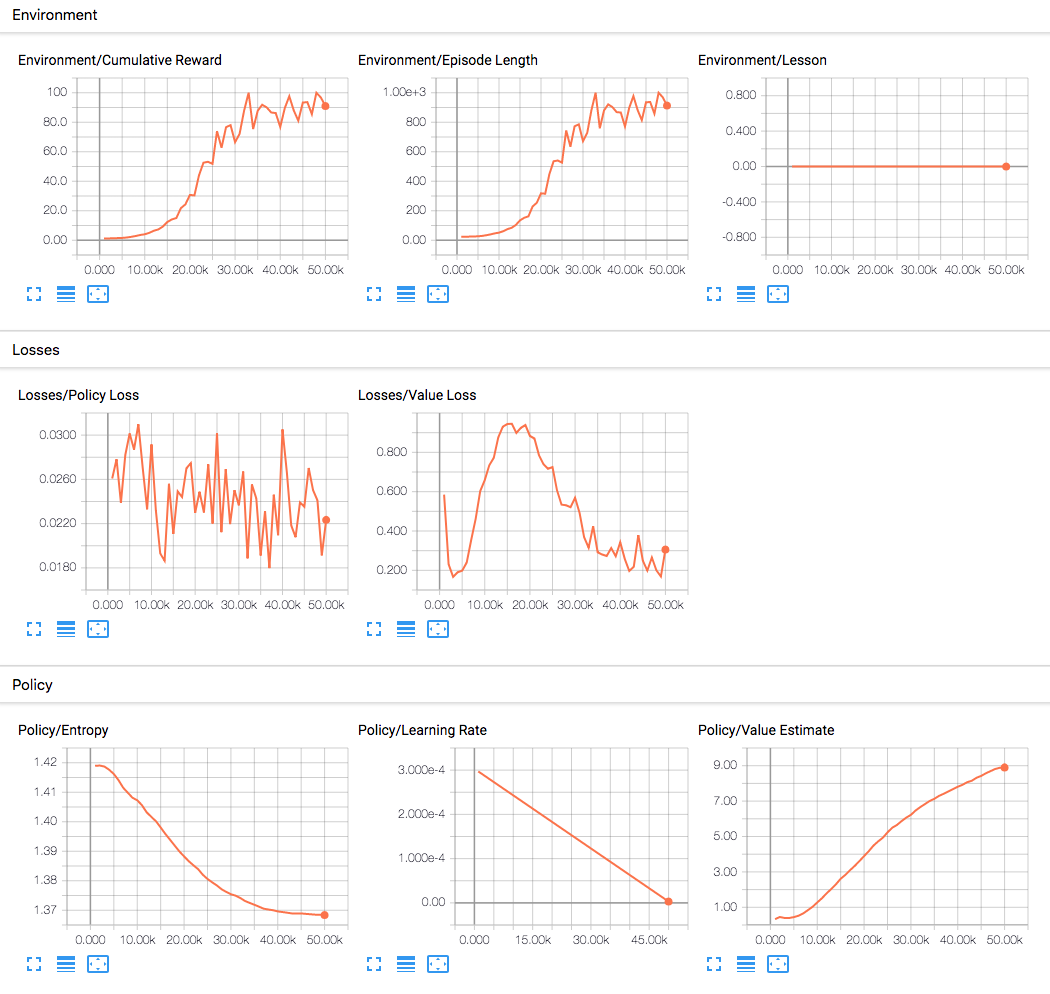
stats = {'cumulative_reward': [], 'episode_length': [], 'value_estimate': [], |
|
|
|
'entropy': [], 'value_loss': [], 'policy_loss': [], 'learning_rate': []} |
|
|
|
stats = {'Environment/Cumulative Reward': [], 'Environment/Episode Length': [], |
|
|
|
'Policy/Value Estimate': [], 'Policy/Entropy': [], 'Losses/Value Loss': [], |
|
|
|
'Losses/Policy Loss': [], 'Policy/Learning Rate': []} |
|
|
|
stats['forward_loss'] = [] |
|
|
|
stats['inverse_loss'] = [] |
|
|
|
stats['intrinsic_reward'] = [] |
|
|
|
stats['Losses/Forward Loss'] = [] |
|
|
|
stats['Losses/Inverse Loss'] = [] |
|
|
|
stats['Policy/Curiosity Reward'] = [] |
|
|
|
self.intrinsic_rewards = {} |
|
|
|
self.stats = stats |
|
|
|
|
|
|
|
|
|
|
|
""" |
|
|
|
Increment the step count of the trainer and Updates the last reward |
|
|
|
""" |
|
|
|
if len(self.stats['cumulative_reward']) > 0: |
|
|
|
mean_reward = np.mean(self.stats['cumulative_reward']) |
|
|
|
if len(self.stats['Environment/Cumulative Reward']) > 0: |
|
|
|
mean_reward = np.mean(self.stats['Environment/Cumulative Reward']) |
|
|
|
self.policy.update_reward(mean_reward) |
|
|
|
self.policy.increment_step() |
|
|
|
self.step = self.policy.get_current_step() |
|
|
|
|
|
|
|
return [], [], [], None, None |
|
|
|
|
|
|
|
run_out = self.policy.evaluate(curr_brain_info) |
|
|
|
self.stats['value_estimate'].append(run_out['value'].mean()) |
|
|
|
self.stats['entropy'].append(run_out['entropy'].mean()) |
|
|
|
self.stats['learning_rate'].append(run_out['learning_rate']) |
|
|
|
self.stats['Policy/Value Estimate'].append(run_out['value'].mean()) |
|
|
|
self.stats['Policy/Entropy'].append(run_out['entropy'].mean()) |
|
|
|
self.stats['Policy/Learning Rate'].append(run_out['learning_rate']) |
|
|
|
if self.policy.use_recurrent: |
|
|
|
return run_out['action'], run_out['memory_out'], None, \ |
|
|
|
run_out['value'], run_out |
|
|
|
|
|
|
|
|
|
|
|
self.training_buffer[agent_id].reset_agent() |
|
|
|
if info.local_done[l]: |
|
|
|
self.stats['cumulative_reward'].append( |
|
|
|
self.stats['Environment/Cumulative Reward'].append( |
|
|
|
self.stats['episode_length'].append( |
|
|
|
self.stats['Environment/Episode Length'].append( |
|
|
|
self.stats['intrinsic_reward'].append( |
|
|
|
self.stats['Policy/Curiosity Reward'].append( |
|
|
|
self.intrinsic_rewards.get(agent_id, 0)) |
|
|
|
self.intrinsic_rewards[agent_id] = 0 |
|
|
|
|
|
|
|
|
|
|
|
if self.use_curiosity: |
|
|
|
inverse_total.append(run_out['inverse_loss']) |
|
|
|
forward_total.append(run_out['forward_loss']) |
|
|
|
self.stats['value_loss'].append(np.mean(value_total)) |
|
|
|
self.stats['policy_loss'].append(np.mean(policy_total)) |
|
|
|
self.stats['Losses/Value Loss'].append(np.mean(value_total)) |
|
|
|
self.stats['Losses/Policy Loss'].append(np.mean(policy_total)) |
|
|
|
self.stats['forward_loss'].append(np.mean(forward_total)) |
|
|
|
self.stats['inverse_loss'].append(np.mean(inverse_total)) |
|
|
|
self.stats['Losses/Forward Loss'].append(np.mean(forward_total)) |
|
|
|
self.stats['Losses/Inverse Loss'].append(np.mean(inverse_total)) |
|
|
|
self.training_buffer.reset_update_buffer() |
|
|
|
|
|
|
|
|
|
|
|
|
{kind=link}