浏览代码
0.2 Update
0.2 Update
* added broadcast to the player and heuristic brain. Allows the python API to record actions taken along with the states and rewards * removed the broadcast checkbox Added a Handshake method for the communicator The academy will try to handshake regardless of the brains present Player and Heuristic brains will send their information through the communicator but will not receive commands * bug fix : The environment only requests actions from external brains when unique * added warning in case no brins are set to external * fix on the instanciation of coreBrains, fix on the conversion of actions to arrays in the BrainInfo received from step * default discrete action is now 0 bug fix for discrete broadcast action (the action size should be one in Agents.cs) modified Tennis so that the default action is no action modified the TemplateDecsion.cs to ensure non null values are sent from Decide() and MakeMemory() * minor fixes * need to convert the s.../develop-generalizationTraining-TrainerController
当前提交
51f23cd2
共有 199 个文件被更改,包括 10977 次插入 和 1264 次删除
-
5.gitignore
-
85docs/Example-Environments.md
-
4docs/Getting-Started-with-Balance-Ball.md
-
40docs/Making-a-new-Unity-Environment.md
-
25docs/Readme.md
-
14docs/Using-TensorFlow-Sharp-in-Unity-(Experimental).md
-
45docs/best-practices-ppo.md
-
11docs/best-practices.md
-
56python/PPO.ipynb
-
89python/ppo.py
-
134python/ppo/models.py
-
85python/ppo/trainer.py
-
2python/setup.py
-
200python/test_unityagents.py
-
1python/unityagents/__init__.py
-
3python/unityagents/brain.py
-
247python/unityagents/environment.py
-
31python/unityagents/exception.py
-
29unity-environment/Assets/ML-Agents/Examples/3DBall/Prefabs/Game.prefab
-
183unity-environment/Assets/ML-Agents/Examples/3DBall/Scene.unity
-
12unity-environment/Assets/ML-Agents/Examples/3DBall/Scripts/Ball3DAgent.cs
-
96unity-environment/Assets/ML-Agents/Examples/Basic/Scripts/BasicAgent.cs
-
21unity-environment/Assets/ML-Agents/Examples/Basic/Scripts/BasicDecision.cs
-
100unity-environment/Assets/ML-Agents/Examples/GridWorld/GridWorld.unity
-
1unity-environment/Assets/ML-Agents/Examples/GridWorld/Scripts/GridAgent.cs
-
13unity-environment/Assets/ML-Agents/Examples/Tennis/Materials/ballMat.physicMaterial
-
2unity-environment/Assets/ML-Agents/Examples/Tennis/Materials/racketMat.physicMaterial
-
16unity-environment/Assets/ML-Agents/Examples/Tennis/Scripts/TennisAcademy.cs
-
62unity-environment/Assets/ML-Agents/Examples/Tennis/Scripts/TennisAgent.cs
-
34unity-environment/Assets/ML-Agents/Examples/Tennis/Scripts/hitWall.cs
-
256unity-environment/Assets/ML-Agents/Examples/Tennis/TFModels/Tennis.bytes
-
929unity-environment/Assets/ML-Agents/Examples/Tennis/Tennis.unity
-
49unity-environment/Assets/ML-Agents/Scripts/Academy.cs
-
31unity-environment/Assets/ML-Agents/Scripts/Agent.cs
-
36unity-environment/Assets/ML-Agents/Scripts/Brain.cs
-
13unity-environment/Assets/ML-Agents/Scripts/Communicator.cs
-
32unity-environment/Assets/ML-Agents/Scripts/CoreBrainExternal.cs
-
22unity-environment/Assets/ML-Agents/Scripts/CoreBrainHeuristic.cs
-
56unity-environment/Assets/ML-Agents/Scripts/CoreBrainInternal.cs
-
28unity-environment/Assets/ML-Agents/Scripts/CoreBrainPlayer.cs
-
129unity-environment/Assets/ML-Agents/Scripts/ExternalCommunicator.cs
-
19unity-environment/Assets/ML-Agents/Template/Scripts/TemplateDecision.cs
-
8unity-environment/ProjectSettings/TagManager.asset
-
18unity-environment/README.md
-
12docs/broadcast.md
-
87docs/curriculum.md
-
18docs/monitor.md
-
213images/broadcast.png
-
1001images/crawler.png
-
488images/curriculum.png
-
260images/curriculum_progress.png
-
173images/math.png
-
563images/monitor.png
-
495images/push.png
-
1001images/reacher.png
-
695images/wall.png
-
81python/unityagents/curriculum.py
-
9unity-environment/Assets/ML-Agents/Examples/Area.meta
-
9unity-environment/Assets/ML-Agents/Examples/Crawler.meta
-
9unity-environment/Assets/ML-Agents/Examples/Reacher.meta
-
10unity-environment/Assets/ML-Agents/Examples/Tennis/Prefabs.meta
-
40unity-environment/Assets/ML-Agents/Examples/Tennis/Scripts/TennisArea.cs
-
13unity-environment/Assets/ML-Agents/Examples/Tennis/Scripts/TennisArea.cs.meta
-
380unity-environment/Assets/ML-Agents/Scripts/Monitor.cs
-
12unity-environment/Assets/ML-Agents/Scripts/Monitor.cs.meta
-
12python/curricula/push.json
-
12python/curricula/test.json
-
11python/curricula/wall.json
-
9unity-environment/Assets/ML-Agents/Examples/Area/Materials.meta
-
76unity-environment/Assets/ML-Agents/Examples/Area/Materials/agent.mat
-
9unity-environment/Assets/ML-Agents/Examples/Area/Materials/agent.mat.meta
-
76unity-environment/Assets/ML-Agents/Examples/Area/Materials/block.mat
-
9unity-environment/Assets/ML-Agents/Examples/Area/Materials/block.mat.meta
-
76unity-environment/Assets/ML-Agents/Examples/Area/Materials/goal.mat
-
9unity-environment/Assets/ML-Agents/Examples/Area/Materials/goal.mat.meta
-
77unity-environment/Assets/ML-Agents/Examples/Area/Materials/wall.mat
-
9unity-environment/Assets/ML-Agents/Examples/Area/Materials/wall.mat.meta
-
9unity-environment/Assets/ML-Agents/Examples/Area/Prefabs.meta
-
224unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/Agent.prefab
-
9unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/Agent.prefab.meta
-
111unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/Block.prefab
-
9unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/Block.prefab.meta
-
190unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/GoalHolder.prefab
-
9unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/GoalHolder.prefab.meta
-
641unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/PushArea.prefab
-
9unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/PushArea.prefab.meta
-
757unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/WallArea.prefab
-
9unity-environment/Assets/ML-Agents/Examples/Area/Prefabs/WallArea.prefab.meta
-
1001unity-environment/Assets/ML-Agents/Examples/Area/Push.unity
-
8unity-environment/Assets/ML-Agents/Examples/Area/Push.unity.meta
-
9unity-environment/Assets/ML-Agents/Examples/Area/Scripts.meta
-
20unity-environment/Assets/ML-Agents/Examples/Area/Scripts/Area.cs
|
|||
# Unity ML Agents Documentation |
|||
|
|||
## Basic |
|||
## About |
|||
* [Example Environments](Example-Environments.md) |
|||
|
|||
## Tutorials |
|||
* [Example Environments](Example-Environments.md) |
|||
* [Making a new Unity Environment](Making-a-new-Unity-Environment.md) |
|||
* [How to use the Python API](Unity-Agents---Python-API.md) |
|||
## Advanced |
|||
* [How to make a new Unity Environment](Making-a-new-Unity-Environment.md) |
|||
* [Best practices when designing an Environment](best-practices.md) |
|||
* [Best practices when training using PPO](best-practices-ppo.md) |
|||
* [How to organize the Scene](Organizing-the-Scene.md) |
|||
* [How to use the Python API](Unity-Agents---Python-API.md) |
|||
* [How to use TensorflowSharp inside Unity [Experimental]](Using-TensorFlow-Sharp-in-Unity-(Experimental).md) |
|||
## Features |
|||
* [Scene Organization](Organizing-the-Scene.md) |
|||
* [Curriculum Learning](curriculum.md) |
|||
* [Broadcast](broadcast.md) |
|||
* [Monitor](monitor.md) |
|||
* [TensorflowSharp in Unity [Experimental]](Using-TensorFlow-Sharp-in-Unity-(Experimental).md) |
|||
|
|||
## Best Practices |
|||
* [Best practices when creating an Environment](best-practices.md) |
|||
* [Best practices when training using PPO](best-practices-ppo.md) |
|||
|
|||
## Help |
|||
* [Limitations & Common Issues](Limitations-&-Common-Issues.md) |
|||
|
|||
from .environment import * |
|||
from .brain import * |
|||
from .exception import * |
|||
from .curriculum import * |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!134 &13400000 |
|||
PhysicMaterial: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 0} |
|||
m_Name: ballMat |
|||
dynamicFriction: 0 |
|||
staticFriction: 0 |
|||
bounciness: 1 |
|||
frictionCombine: 1 |
|||
bounceCombine: 3 |
|||
929
unity-environment/Assets/ML-Agents/Examples/Tennis/Tennis.unity
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
|
|||
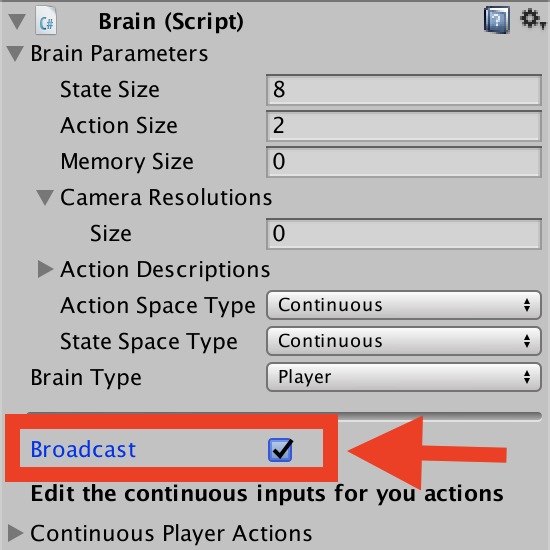
# Using the Broadcast Feature |
|||
The Player, Heuristic and Internal brains have been updated to support broadcast. The broadcast feature allows you to collect data from your agents in python without controling them. |
|||
## How to use : Unity |
|||
To turn it on in Unity, simply check the `Broadcast` box as shown bellow: |
|||
|
|||
 |
|||
|
|||
## How to use : Python |
|||
When you launch your Unity Environment from python, you can see what the agents connected to non-external brains are doing. When calling `step` or `reset` on your environment, you retrieve a dictionary from brain names to `BrainInfo` objects. Each `BrainInfo` the non-external brains set to broadcast. |
|||
Just like with an external brain, the `BrainInfo` object contains the fields for `observations`, `states`, `memories`,`rewards`, `local_done`, `agents` and `previous_actions`. Note that `previous_actions` corresponds to the actions that were taken by the agents at the previous step, not the current one. |
|||
Note that when you do a `step` on the environment, you cannot provide actions for non-external brains. If there are no external brains in the scene, simply call `step()` with no arguments. |
|||
You can use the broadcast feature to collect data generated by Player, Heuristics or Internal brains game sessions. You can then use this data to train an agent in a supervised context. |
|||
|
|||
# Training with Curriculum Learning |
|||
|
|||
## Background |
|||
|
|||
Curriculum learning is a way of training a machine learning model where more difficult |
|||
aspects of a problem are gradually introduced in such a way that the model is always |
|||
optimally challenged. Here is a link to the original paper which introduces the ideal |
|||
formally. More generally, this idea has been around much longer, for it is how we humans |
|||
typically learn. If you imagine any childhood primary school education, there is an |
|||
ordering of classes and topics. Arithmetic is taught before algebra, for example. |
|||
Likewise, algebra is taught before calculus. The skills and knowledge learned in the |
|||
earlier subjects provide a scaffolding for later lessons. The same principle can be |
|||
applied to machine learning, where training on easier tasks can provide a scaffolding |
|||
for harder tasks in the future. |
|||
|
|||
 |
|||
|
|||
_Example of a mathematics curriculum. Lessons progress from simpler topics to more |
|||
complex ones, with each building on the last._ |
|||
|
|||
When we think about how Reinforcement Learning actually works, the primary learning |
|||
signal is a scalar reward received occasionally throughout training. In more complex |
|||
or difficult tasks, this reward can often be sparse, and rarely achieved. For example, |
|||
imagine a task in which an agent needs to scale a wall to arrive at a goal. The starting |
|||
point when training an agent to accomplish this task will be a random policy. That |
|||
starting policy will have the agent running in circles, and will likely never, or very |
|||
rarely scale the wall properly to the achieve the reward. If we start with a simpler |
|||
task, such as moving toward an unobstructed goal, then the agent can easily learn to |
|||
accomplish the task. From there, we can slowly add to the difficulty of the task by |
|||
increasing the size of the wall, until the agent can complete the initially |
|||
near-impossible task of scaling the wall. We are including just such an environment with |
|||
ML-Agents 0.2, called Wall Area. |
|||
|
|||
 |
|||
|
|||
_Demonstration of a curriculum training scenario in which a progressively taller wall |
|||
obstructs the path to the goal._ |
|||
|
|||
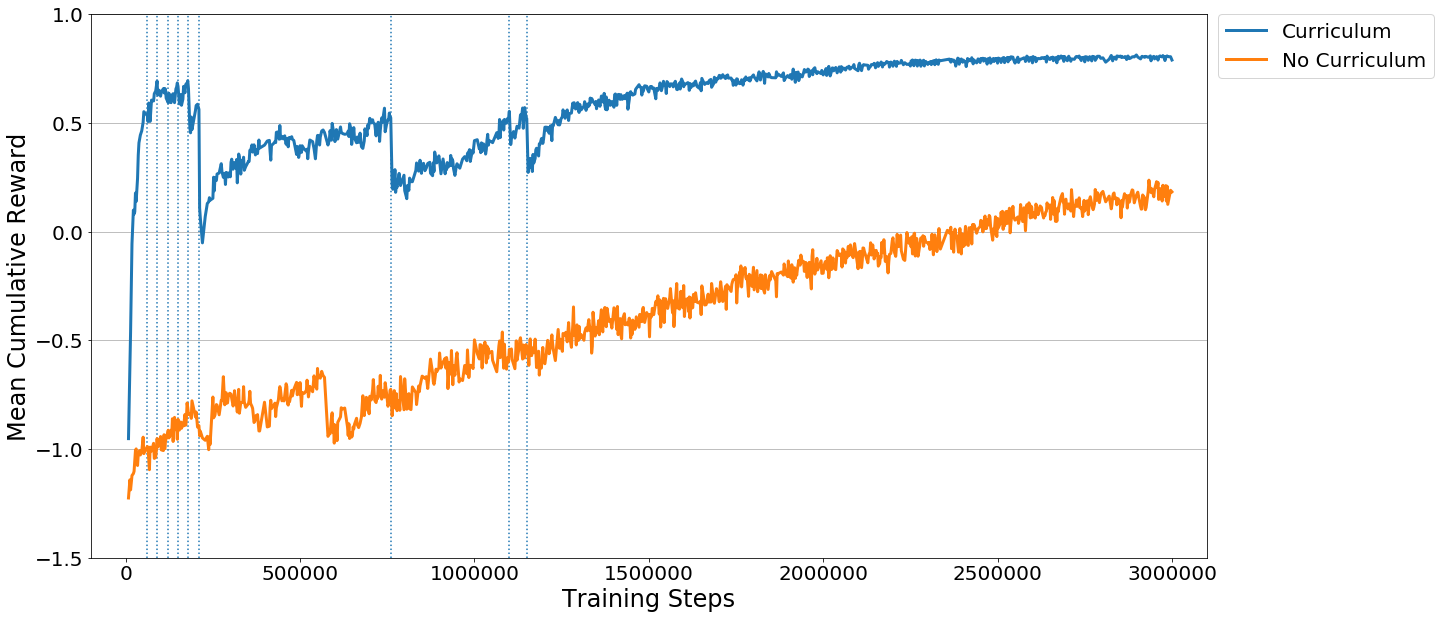
To see this in action, observe the two learning curves below. Each displays the reward |
|||
over time for an agent trained using PPO with the same set of training hyperparameters. |
|||
The difference is that the agent on the left was trained using the full-height wall |
|||
version of the task, and the right agent was trained using the curriculum version of |
|||
the task. As you can see, without using curriculum learning the agent has a lot of |
|||
difficulty. We think that by using well-crafted curricula, agents trained using |
|||
reinforcement learning will be able to accomplish tasks otherwise much more difficult. |
|||
|
|||
 |
|||
|
|||
## How-To |
|||
|
|||
So how does it work? In order to define a curriculum, the first step is to decide which |
|||
parameters of the environment will vary. In the case of the Wall Area environment, what |
|||
varies is the height of the wall. We can define this as a reset parameter in the Academy |
|||
object of our scene, and by doing so it becomes adjustable via the Python API. Rather |
|||
than adjusting it by hand, we then create a simple JSON file which describes the |
|||
structure of the curriculum. Within it we can set at what points in the training process |
|||
our wall height will change, either based on the percentage of training steps which have |
|||
taken place, or what the average reward the agent has received in the recent past is. |
|||
Once these are in place, we simply launch ppo.py using the `–curriculum-file` flag to |
|||
point to the JSON file, and PPO we will train using Curriculum Learning. Of course we can |
|||
then keep track of the current lesson and progress via TensorBoard. |
|||
|
|||
|
|||
```json |
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5], |
|||
"min_lesson_length" : 2, |
|||
"signal_smoothing" : true, |
|||
"parameters" : |
|||
{ |
|||
"min_wall_height" : [0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5], |
|||
"max_wall_height" : [1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0] |
|||
} |
|||
} |
|||
``` |
|||
|
|||
* `measure` - What to measure learning progress, and advancement in lessons by. |
|||
* `reward` - Uses a measure received reward. |
|||
* `progress` - Uses ratio of steps/max_steps. |
|||
* `thresholds` (float array) - Points in value of `measure` where lesson should be increased. |
|||
* `min_lesson_length` (int) - How many times the progress measure should be reported before |
|||
incrementing the lesson. |
|||
* `signal_smoothing` (true/false) - Whether to weight the current progress measure by previous values. |
|||
* If `true`, weighting will be 0.75 (new) 0.25 (old). |
|||
* `parameters` (dictionary of key:string, value:float array) - Corresponds to academy reset parameters to control. Length of each array |
|||
should be one greater than number of thresholds. |
|||
|
|||
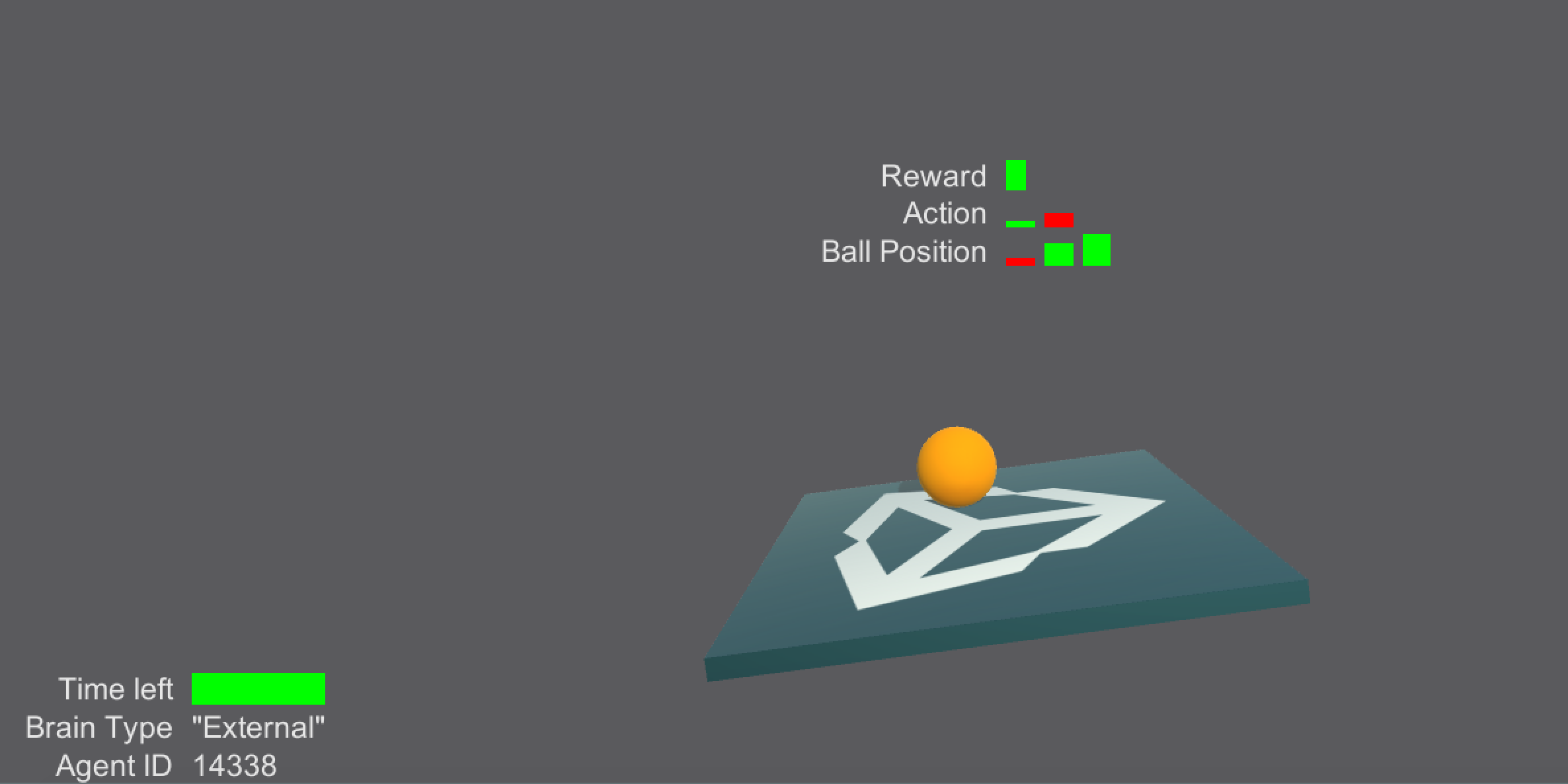
# Using the Monitor |
|||
|
|||
 |
|||
|
|||
The monitor allows visualizing information related to the agents or training process within a Unity scene. |
|||
|
|||
You can track many different things both related and unrelated to the agents themselves. To use the Monitor, call the Log function anywhere in your code : |
|||
```csharp |
|||
Monitor.Log(key, value, displayType , target) |
|||
``` |
|||
* *`key`* is the name of the information you want to display. |
|||
* *`value`* is the information you want to display. |
|||
* *`displayType`* is a MonitorType that can be either `text`, `slider`, `bar` or `hist`. |
|||
* `text` will convert `value` into a string and display it. It can be useful for displaying error messages! |
|||
* `slider` is used to display a single float between -1 and 1. Note that value must be a float if you want to use a slider. If the value is positive, the slider will be green, if the value is negative, the slider will be red. |
|||
* `hist` is used to display multiple floats. Note that value must be a list or array of floats. The Histogram will be a sequence of vertical sliders. |
|||
* `bar` is used to see the proportions. Note that value must be a list or array of positive floats. For each float in values, a rectangle of width of value divided by the sum of all values will be show. It is best for visualizing values that sum to 1. |
|||
* *`target`* is the transform to which you want to attach information. If the transform is `null` the information will be attached to the global monitor. |
|||
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 550 | 高度: 550 | 大小: 64 KiB |
1001
images/crawler.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 2069 | 高度: 449 | 大小: 116 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 1441 | 高度: 619 | 大小: 96 KiB |
173
images/math.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
| 宽度: 2372 | 高度: 1186 | 大小: 146 KiB |
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 2550 | 高度: 1494 | 大小: 192 KiB |
1001
images/reacher.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|

|
|
| 宽度: 2444 | 高度: 1424 | 大小: 255 KiB |
|
|||
import json |
|||
import numpy as np |
|||
|
|||
from .exception import UnityEnvironmentException |
|||
|
|||
|
|||
class Curriculum(object): |
|||
def __init__(self, location, default_reset_parameters): |
|||
""" |
|||
Initializes a Curriculum object. |
|||
:param location: Path to JSON defining curriculum. |
|||
:param default_reset_parameters: Set of reset parameters for environment. |
|||
""" |
|||
self.lesson_number = 0 |
|||
self.lesson_length = 0 |
|||
self.measure_type = None |
|||
if location is None: |
|||
self.data = None |
|||
else: |
|||
try: |
|||
with open(location) as data_file: |
|||
self.data = json.load(data_file) |
|||
except FileNotFoundError: |
|||
raise UnityEnvironmentException( |
|||
"The file {0} could not be found.".format(location)) |
|||
except UnicodeDecodeError: |
|||
raise UnityEnvironmentException("There was an error decoding {}".format(location)) |
|||
self.smoothing_value = 0 |
|||
for key in ['parameters', 'measure', 'thresholds', |
|||
'min_lesson_length', 'signal_smoothing']: |
|||
if key not in self.data: |
|||
raise UnityEnvironmentException("{0} does not contain a " |
|||
"{1} field.".format(location, key)) |
|||
parameters = self.data['parameters'] |
|||
self.measure_type = self.data['measure'] |
|||
self.max_lesson_number = len(self.data['thresholds']) |
|||
for key in parameters: |
|||
if key not in default_reset_parameters: |
|||
raise UnityEnvironmentException( |
|||
"The parameter {0} in Curriculum {1} is not present in " |
|||
"the Environment".format(key, location)) |
|||
for key in parameters: |
|||
if len(parameters[key]) != self.max_lesson_number + 1: |
|||
raise UnityEnvironmentException( |
|||
"The parameter {0} in Curriculum {1} must have {2} values " |
|||
"but {3} were found".format(key, location, |
|||
self.max_lesson_number + 1, len(parameters[key]))) |
|||
|
|||
@property |
|||
def measure(self): |
|||
return self.measure_type |
|||
|
|||
def get_lesson_number(self): |
|||
return self.lesson_number |
|||
|
|||
def set_lesson_number(self, value): |
|||
self.lesson_length = 0 |
|||
self.lesson_number = max(0, min(value, self.max_lesson_number)) |
|||
|
|||
def get_lesson(self, progress): |
|||
""" |
|||
Returns reset parameters which correspond to current lesson. |
|||
:param progress: Measure of progress (either reward or percentage steps completed). |
|||
:return: Dictionary containing reset parameters. |
|||
""" |
|||
if self.data is None or progress is None: |
|||
return {} |
|||
if self.data["signal_smoothing"]: |
|||
progress = self.smoothing_value * 0.25 + 0.75 * progress |
|||
self.smoothing_value = progress |
|||
self.lesson_length += 1 |
|||
if self.lesson_number < self.max_lesson_number: |
|||
if ((progress > self.data['thresholds'][self.lesson_number]) and |
|||
(self.lesson_length > self.data['min_lesson_length'])): |
|||
self.lesson_length = 0 |
|||
self.lesson_number += 1 |
|||
config = {} |
|||
parameters = self.data["parameters"] |
|||
for key in parameters: |
|||
config[key] = parameters[key][self.lesson_number] |
|||
return config |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: dd0ac6aeac49a4adcb3e8db0f7280fc0 |
|||
folderAsset: yes |
|||
timeCreated: 1506303336 |
|||
licenseType: Pro |
|||
DefaultImporter: |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 0efc731e39fd04495bee94884abad038 |
|||
folderAsset: yes |
|||
timeCreated: 1509574928 |
|||
licenseType: Free |
|||
DefaultImporter: |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 605a889b6a7da4449a954adbd51b3c3b |
|||
folderAsset: yes |
|||
timeCreated: 1508533646 |
|||
licenseType: Pro |
|||
DefaultImporter: |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: cbd3b3ae7cdbe42eaa03e192885900cf |
|||
folderAsset: yes |
|||
timeCreated: 1511815356 |
|||
licenseType: Pro |
|||
DefaultImporter: |
|||
externalObjects: {} |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
using System.Collections; |
|||
using System.Collections.Generic; |
|||
using UnityEngine; |
|||
|
|||
public class TennisArea : MonoBehaviour { |
|||
|
|||
public GameObject ball; |
|||
public GameObject agentA; |
|||
public GameObject agentB; |
|||
|
|||
// Use this for initialization
|
|||
void Start () { |
|||
|
|||
} |
|||
|
|||
// Update is called once per frame
|
|||
void Update () { |
|||
|
|||
} |
|||
|
|||
public void MatchReset() { |
|||
float ballOut = Random.Range(4f, 11f); |
|||
int flip = Random.Range(0, 2); |
|||
if (flip == 0) |
|||
{ |
|||
ball.transform.position = new Vector3(-ballOut, 5f, 0f) + transform.position; |
|||
} |
|||
else |
|||
{ |
|||
ball.transform.position = new Vector3(ballOut, 5f, 0f) + transform.position; |
|||
} |
|||
ball.GetComponent<Rigidbody>().velocity = new Vector3(0f, 0f, 0f); |
|||
ball.transform.localScale = new Vector3(1, 1, 1); |
|||
} |
|||
|
|||
void FixedUpdate() { |
|||
Vector3 rgV = ball.GetComponent<Rigidbody>().velocity; |
|||
ball.GetComponent<Rigidbody>().velocity = new Vector3(Mathf.Clamp(rgV.x, -9f, 9f), Mathf.Clamp(rgV.y, -9f, 9f), rgV.z); |
|||
} |
|||
} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: bc15854a4efe14dceb84a3183ca4c896 |
|||
timeCreated: 1511824270 |
|||
licenseType: Pro |
|||
MonoImporter: |
|||
externalObjects: {} |
|||
serializedVersion: 2 |
|||
defaultReferences: [] |
|||
executionOrder: 0 |
|||
icon: {instanceID: 0} |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
using System.Collections; |
|||
using System.Collections.Generic; |
|||
using UnityEngine; |
|||
using UnityEngine.UI; |
|||
using Newtonsoft.Json; |
|||
using System.Linq; |
|||
|
|||
|
|||
/** The type of monitor the information must be displayed in. |
|||
* <slider> corresponds to a slingle rectangle which width is given |
|||
* by a float between -1 and 1. (green is positive, red is negative) |
|||
* <hist> corresponds to n vertical sliders. |
|||
* <text> is a text field. |
|||
* <bar> is a rectangle of fixed length to represent the proportions |
|||
* of a list of floats. |
|||
*/ |
|||
public enum MonitorType |
|||
{ |
|||
slider, |
|||
hist, |
|||
text, |
|||
bar |
|||
} |
|||
|
|||
/** Monitor is used to display information. Use the log function to add |
|||
* information to your monitor. |
|||
*/ |
|||
public class Monitor : MonoBehaviour |
|||
{ |
|||
|
|||
static bool isInstanciated; |
|||
static GameObject canvas; |
|||
|
|||
private struct DisplayValue |
|||
{ |
|||
public float time; |
|||
public object value; |
|||
public MonitorType monitorDisplayType; |
|||
} |
|||
|
|||
static Dictionary<Transform, Dictionary<string, DisplayValue>> displayTransformValues; |
|||
static private Color[] barColors; |
|||
[HideInInspector] |
|||
static public float verticalOffset = 3f; |
|||
/**< \brief This float represents how high above the target the monitors will be. */ |
|||
|
|||
static GUIStyle keyStyle; |
|||
static GUIStyle valueStyle; |
|||
static GUIStyle greenStyle; |
|||
static GUIStyle redStyle; |
|||
static GUIStyle[] colorStyle; |
|||
static bool initialized; |
|||
|
|||
|
|||
/** Use the Monitor.Log static function to attach information to a transform. |
|||
* If displayType is <text>, value can be any object. |
|||
* If sidplayType is <slider>, value must be a float. |
|||
* If sidplayType is <hist>, value must be a List or Array of floats. |
|||
* If sidplayType is <bar>, value must be a list or Array of positive floats. |
|||
* Note that <slider> and <hist> caps values between -1 and 1. |
|||
* @param key The name of the information you wish to Log. |
|||
* @param value The value you want to display. |
|||
* @param displayType The type of display. |
|||
* @param target The transform you want to attach the information to. |
|||
*/ |
|||
public static void Log( |
|||
string key, |
|||
object value, |
|||
MonitorType displayType = MonitorType.text, |
|||
Transform target = null) |
|||
{ |
|||
|
|||
|
|||
|
|||
if (!isInstanciated) |
|||
{ |
|||
InstanciateCanvas(); |
|||
isInstanciated = true; |
|||
|
|||
} |
|||
|
|||
if (target == null) |
|||
{ |
|||
target = canvas.transform; |
|||
} |
|||
|
|||
if (!displayTransformValues.Keys.Contains(target)) |
|||
{ |
|||
displayTransformValues[target] = new Dictionary<string, DisplayValue>(); |
|||
} |
|||
|
|||
Dictionary<string, DisplayValue> displayValues = displayTransformValues[target]; |
|||
|
|||
if (value == null) |
|||
{ |
|||
RemoveValue(target, key); |
|||
return; |
|||
} |
|||
if (!displayValues.ContainsKey(key)) |
|||
{ |
|||
DisplayValue dv = new DisplayValue(); |
|||
dv.time = Time.timeSinceLevelLoad; |
|||
dv.value = value; |
|||
dv.monitorDisplayType = displayType; |
|||
displayValues[key] = dv; |
|||
while (displayValues.Count > 20) |
|||
{ |
|||
string max = displayValues.Aggregate((l, r) => l.Value.time < r.Value.time ? l : r).Key; |
|||
RemoveValue(target, max); |
|||
} |
|||
} |
|||
else |
|||
{ |
|||
DisplayValue dv = displayValues[key]; |
|||
dv.value = value; |
|||
displayValues[key] = dv; |
|||
} |
|||
} |
|||
|
|||
/** Remove a value from a monitor |
|||
* @param target The transform to which the information is attached |
|||
* @param key The key of the information you want to remove |
|||
*/ |
|||
public static void RemoveValue(Transform target, string key) |
|||
{ |
|||
if (target == null) |
|||
{ |
|||
target = canvas.transform; |
|||
} |
|||
if (displayTransformValues.Keys.Contains(target)) |
|||
{ |
|||
if (displayTransformValues[target].ContainsKey(key)) |
|||
{ |
|||
displayTransformValues[target].Remove(key); |
|||
if (displayTransformValues[target].Keys.Count == 0) |
|||
{ |
|||
displayTransformValues.Remove(target); |
|||
} |
|||
} |
|||
} |
|||
|
|||
} |
|||
|
|||
/** Remove all information from a monitor |
|||
* @param target The transform to which the information is attached |
|||
*/ |
|||
public static void RemoveAllValues(Transform target) |
|||
{ |
|||
if (target == null) |
|||
{ |
|||
target = canvas.transform; |
|||
} |
|||
if (displayTransformValues.Keys.Contains(target)) |
|||
{ |
|||
displayTransformValues.Remove(target); |
|||
} |
|||
|
|||
} |
|||
|
|||
/** Use SetActive to enable or disable the Monitor via script |
|||
* @param active Set the Monitor's status to the value of active |
|||
*/ |
|||
public static void SetActive(bool active){ |
|||
if (!isInstanciated) |
|||
{ |
|||
InstanciateCanvas(); |
|||
isInstanciated = true; |
|||
|
|||
} |
|||
canvas.SetActive(active); |
|||
|
|||
} |
|||
|
|||
private static void InstanciateCanvas() |
|||
{ |
|||
canvas = GameObject.Find("AgentMonitorCanvas"); |
|||
if (canvas == null) |
|||
{ |
|||
canvas = new GameObject(); |
|||
canvas.name = "AgentMonitorCanvas"; |
|||
canvas.AddComponent<Monitor>(); |
|||
} |
|||
displayTransformValues = new Dictionary<Transform, Dictionary< string , DisplayValue>>(); |
|||
|
|||
} |
|||
|
|||
private float[] ToFloatArray(object input) |
|||
{ |
|||
try |
|||
{ |
|||
return JsonConvert.DeserializeObject<float[]>( |
|||
JsonConvert.SerializeObject(input, Formatting.None)); |
|||
} |
|||
catch |
|||
{ |
|||
} |
|||
try |
|||
{ |
|||
return new float[1] |
|||
{JsonConvert.DeserializeObject<float>( |
|||
JsonConvert.SerializeObject(input, Formatting.None)) |
|||
}; |
|||
} |
|||
catch |
|||
{ |
|||
} |
|||
|
|||
return new float[0]; |
|||
} |
|||
|
|||
void OnGUI() |
|||
{ |
|||
if (!initialized) |
|||
{ |
|||
Initialize(); |
|||
initialized = true; |
|||
} |
|||
|
|||
var toIterate = displayTransformValues.Keys.ToList(); |
|||
foreach (Transform target in toIterate) |
|||
{ |
|||
if (target == null) |
|||
{ |
|||
displayTransformValues.Remove(target); |
|||
continue; |
|||
} |
|||
|
|||
float widthScaler = (Screen.width / 1000f); |
|||
float keyPixelWidth = 100 * widthScaler; |
|||
float keyPixelHeight = 20 * widthScaler; |
|||
float paddingwidth = 10 * widthScaler; |
|||
|
|||
float scale = 1f; |
|||
Vector2 origin = new Vector3(0, Screen.height); |
|||
if (!(target == canvas.transform)) |
|||
{ |
|||
Vector3 cam2obj = target.position - Camera.main.transform.position; |
|||
scale = Mathf.Min(1, 20f / (Vector3.Dot(cam2obj, Camera.main.transform.forward))); |
|||
Vector3 worldPosition = Camera.main.WorldToScreenPoint(target.position + new Vector3(0, verticalOffset, 0)); |
|||
origin = new Vector3(worldPosition.x - keyPixelWidth * scale, Screen.height - worldPosition.y); |
|||
} |
|||
keyPixelWidth *= scale; |
|||
keyPixelHeight *= scale; |
|||
paddingwidth *= scale; |
|||
keyStyle.fontSize = (int)(keyPixelHeight * 0.8f); |
|||
if (keyStyle.fontSize < 2) |
|||
{ |
|||
continue; |
|||
} |
|||
|
|||
|
|||
Dictionary<string, DisplayValue> displayValues = displayTransformValues[target]; |
|||
|
|||
int index = 0; |
|||
foreach (string key in displayValues.Keys.OrderBy(x => -displayValues[x].time)) |
|||
{ |
|||
keyStyle.alignment = TextAnchor.MiddleRight; |
|||
GUI.Label(new Rect(origin.x, origin.y - (index + 1) * keyPixelHeight, keyPixelWidth, keyPixelHeight), key, keyStyle); |
|||
if (displayValues[key].monitorDisplayType == MonitorType.text) |
|||
{ |
|||
valueStyle.alignment = TextAnchor.MiddleLeft; |
|||
GUI.Label(new Rect( |
|||
origin.x + paddingwidth + keyPixelWidth, |
|||
origin.y - (index + 1) * keyPixelHeight, |
|||
keyPixelWidth, keyPixelHeight), |
|||
JsonConvert.SerializeObject(displayValues[key].value, Formatting.None), valueStyle); |
|||
|
|||
} |
|||
else if (displayValues[key].monitorDisplayType == MonitorType.slider) |
|||
{ |
|||
float sliderValue = 0f; |
|||
if (displayValues[key].value.GetType() == typeof(float)) |
|||
{ |
|||
sliderValue = (float)displayValues[key].value; |
|||
} |
|||
else |
|||
{ |
|||
Debug.LogError(string.Format("The value for {0} could not be displayed as " + |
|||
"a slider because it is not a number.", key)); |
|||
} |
|||
|
|||
sliderValue = Mathf.Min(1f, sliderValue); |
|||
GUIStyle s = greenStyle; |
|||
if (sliderValue < 0) |
|||
{ |
|||
sliderValue = Mathf.Min(1f, -sliderValue); |
|||
s = redStyle; |
|||
} |
|||
GUI.Box(new Rect( |
|||
origin.x + paddingwidth + keyPixelWidth, |
|||
origin.y - (index + 0.9f) * keyPixelHeight, |
|||
keyPixelWidth * sliderValue, keyPixelHeight * 0.8f), |
|||
GUIContent.none, s); |
|||
|
|||
} |
|||
else if (displayValues[key].monitorDisplayType == MonitorType.hist) |
|||
{ |
|||
float histWidth = 0.15f; |
|||
float[] vals = ToFloatArray(displayValues[key].value); |
|||
for (int i = 0; i < vals.Length; i++) |
|||
{ |
|||
float value = Mathf.Min(vals[i], 1); |
|||
GUIStyle s = greenStyle; |
|||
if (value < 0) |
|||
{ |
|||
value = Mathf.Min(1f, -value); |
|||
s = redStyle; |
|||
} |
|||
GUI.Box(new Rect( |
|||
origin.x + paddingwidth + keyPixelWidth + (keyPixelWidth * histWidth + paddingwidth / 2) * i, |
|||
origin.y - (index + 0.1f) * keyPixelHeight, |
|||
keyPixelWidth * histWidth, -keyPixelHeight * value), |
|||
GUIContent.none, s); |
|||
} |
|||
|
|||
|
|||
} |
|||
else if (displayValues[key].monitorDisplayType == MonitorType.bar) |
|||
{ |
|||
float[] vals = ToFloatArray(displayValues[key].value); |
|||
float valsSum = 0f; |
|||
float valsCum = 0f; |
|||
foreach (float f in vals) |
|||
{ |
|||
valsSum += Mathf.Max(f, 0); |
|||
} |
|||
if (valsSum == 0) |
|||
{ |
|||
Debug.LogError(string.Format("The Monitor value for key {0} must be " |
|||
+ "a list or array of positive values and cannot be empty.", key)); |
|||
} |
|||
else |
|||
{ |
|||
for (int i = 0; i < vals.Length; i++) |
|||
{ |
|||
float value = Mathf.Max(vals[i], 0) / valsSum; |
|||
GUI.Box(new Rect( |
|||
origin.x + paddingwidth + keyPixelWidth + keyPixelWidth * valsCum, |
|||
origin.y - (index + 0.9f) * keyPixelHeight, |
|||
keyPixelWidth * value, keyPixelHeight * 0.8f), |
|||
GUIContent.none, colorStyle[i % colorStyle.Length]); |
|||
valsCum += value; |
|||
|
|||
} |
|||
|
|||
} |
|||
|
|||
} |
|||
|
|||
index++; |
|||
} |
|||
} |
|||
} |
|||
|
|||
private void Initialize() |
|||
{ |
|||
|
|||
keyStyle = GUI.skin.label; |
|||
valueStyle = GUI.skin.label; |
|||
valueStyle.clipping = TextClipping.Overflow; |
|||
valueStyle.wordWrap = false; |
|||
|
|||
|
|||
|
|||
barColors = new Color[6]{ Color.magenta, Color.blue, Color.cyan, Color.green, Color.yellow, Color.red }; |
|||
colorStyle = new GUIStyle[barColors.Length]; |
|||
for (int i = 0; i < barColors.Length; i++) |
|||
{ |
|||
Texture2D texture = new Texture2D(1, 1, TextureFormat.ARGB32, false); |
|||
texture.SetPixel(0, 0, barColors[i]); |
|||
texture.Apply(); |
|||
GUIStyle staticRectStyle = new GUIStyle(); |
|||
staticRectStyle.normal.background = texture; |
|||
colorStyle[i] = staticRectStyle; |
|||
} |
|||
greenStyle = colorStyle[3]; |
|||
redStyle = colorStyle[5]; |
|||
} |
|||
|
|||
} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: e59a31a1cc2f5464d9a61bef0bc9a53b |
|||
timeCreated: 1508031727 |
|||
licenseType: Free |
|||
MonoImporter: |
|||
serializedVersion: 2 |
|||
defaultReferences: [] |
|||
executionOrder: 0 |
|||
icon: {instanceID: 0} |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75, 0.75], |
|||
"min_lesson_length" : 2, |
|||
"signal_smoothing" : true, |
|||
"parameters" : |
|||
{ |
|||
"goal_size" : [3.5, 3.25, 3.0, 2.75, 2.5, 2.25, 2.0, 1.75, 1.5, 1.25, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], |
|||
"block_size": [1.5, 1.4, 1.3, 1.2, 1.1, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0], |
|||
"x_variation":[1.5, 1.55, 1.6, 1.65, 1.7, 1.75, 1.8, 1.85, 1.9, 1.95, 2.0, 2.1, 2.2, 2.3, 2.4, 2.5] |
|||
} |
|||
} |
|||
|
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [10, 20, 50], |
|||
"min_lesson_length" : 3, |
|||
"signal_smoothing" : true, |
|||
"parameters" : |
|||
{ |
|||
"param1" : [0.7, 0.5, 0.3, 0.1], |
|||
"param2" : [100, 50, 20, 15], |
|||
"param3" : [0.2, 0.3, 0.7, 0.9] |
|||
} |
|||
} |
|||
|
|||
{ |
|||
"measure" : "reward", |
|||
"thresholds" : [0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5], |
|||
"min_lesson_length" : 2, |
|||
"signal_smoothing" : true, |
|||
"parameters" : |
|||
{ |
|||
"min_wall_height" : [0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5], |
|||
"max_wall_height" : [1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5, 5.0, 5.5, 6.0] |
|||
} |
|||
} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 8f94ab12d7c27400a998ea33e8163b40 |
|||
folderAsset: yes |
|||
timeCreated: 1506189694 |
|||
licenseType: Pro |
|||
DefaultImporter: |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!21 &2100000 |
|||
Material: |
|||
serializedVersion: 6 |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 0} |
|||
m_Name: agent |
|||
m_Shader: {fileID: 46, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_ShaderKeywords: |
|||
m_LightmapFlags: 4 |
|||
m_EnableInstancingVariants: 0 |
|||
m_DoubleSidedGI: 0 |
|||
m_CustomRenderQueue: -1 |
|||
stringTagMap: {} |
|||
disabledShaderPasses: [] |
|||
m_SavedProperties: |
|||
serializedVersion: 3 |
|||
m_TexEnvs: |
|||
- _BumpMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailAlbedoMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailMask: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailNormalMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _EmissionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MainTex: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MetallicGlossMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _OcclusionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _ParallaxMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
m_Floats: |
|||
- _BumpScale: 1 |
|||
- _Cutoff: 0.5 |
|||
- _DetailNormalMapScale: 1 |
|||
- _DstBlend: 0 |
|||
- _GlossMapScale: 1 |
|||
- _Glossiness: 0.5 |
|||
- _GlossyReflections: 1 |
|||
- _Metallic: 0 |
|||
- _Mode: 0 |
|||
- _OcclusionStrength: 1 |
|||
- _Parallax: 0.02 |
|||
- _SmoothnessTextureChannel: 0 |
|||
- _SpecularHighlights: 1 |
|||
- _SrcBlend: 1 |
|||
- _UVSec: 0 |
|||
- _ZWrite: 1 |
|||
m_Colors: |
|||
- _Color: {r: 0.10980392, g: 0.6039216, b: 1, a: 0.8392157} |
|||
- _EmissionColor: {r: 0, g: 0, b: 0, a: 1} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 7cc0e3ba03770412c98e9cca1eb132d0 |
|||
timeCreated: 1506189720 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 2100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!21 &2100000 |
|||
Material: |
|||
serializedVersion: 6 |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 0} |
|||
m_Name: block |
|||
m_Shader: {fileID: 46, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_ShaderKeywords: |
|||
m_LightmapFlags: 4 |
|||
m_EnableInstancingVariants: 0 |
|||
m_DoubleSidedGI: 0 |
|||
m_CustomRenderQueue: -1 |
|||
stringTagMap: {} |
|||
disabledShaderPasses: [] |
|||
m_SavedProperties: |
|||
serializedVersion: 3 |
|||
m_TexEnvs: |
|||
- _BumpMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailAlbedoMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailMask: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailNormalMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _EmissionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MainTex: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MetallicGlossMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _OcclusionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _ParallaxMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
m_Floats: |
|||
- _BumpScale: 1 |
|||
- _Cutoff: 0.5 |
|||
- _DetailNormalMapScale: 1 |
|||
- _DstBlend: 0 |
|||
- _GlossMapScale: 1 |
|||
- _Glossiness: 0.5 |
|||
- _GlossyReflections: 1 |
|||
- _Metallic: 0 |
|||
- _Mode: 0 |
|||
- _OcclusionStrength: 1 |
|||
- _Parallax: 0.02 |
|||
- _SmoothnessTextureChannel: 0 |
|||
- _SpecularHighlights: 1 |
|||
- _SrcBlend: 1 |
|||
- _UVSec: 0 |
|||
- _ZWrite: 1 |
|||
m_Colors: |
|||
- _Color: {r: 0.96862745, g: 0.5803922, b: 0.11764706, a: 1} |
|||
- _EmissionColor: {r: 0, g: 0, b: 0, a: 1} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 668b3b8d9195149df9e09f1a3b0efd98 |
|||
timeCreated: 1506379314 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 2100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!21 &2100000 |
|||
Material: |
|||
serializedVersion: 6 |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 0} |
|||
m_Name: goal |
|||
m_Shader: {fileID: 46, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_ShaderKeywords: |
|||
m_LightmapFlags: 4 |
|||
m_EnableInstancingVariants: 0 |
|||
m_DoubleSidedGI: 0 |
|||
m_CustomRenderQueue: -1 |
|||
stringTagMap: {} |
|||
disabledShaderPasses: [] |
|||
m_SavedProperties: |
|||
serializedVersion: 3 |
|||
m_TexEnvs: |
|||
- _BumpMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailAlbedoMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailMask: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailNormalMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _EmissionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MainTex: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MetallicGlossMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _OcclusionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _ParallaxMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
m_Floats: |
|||
- _BumpScale: 1 |
|||
- _Cutoff: 0.5 |
|||
- _DetailNormalMapScale: 1 |
|||
- _DstBlend: 0 |
|||
- _GlossMapScale: 1 |
|||
- _Glossiness: 0.5 |
|||
- _GlossyReflections: 1 |
|||
- _Metallic: 0 |
|||
- _Mode: 0 |
|||
- _OcclusionStrength: 1 |
|||
- _Parallax: 0.02 |
|||
- _SmoothnessTextureChannel: 0 |
|||
- _SpecularHighlights: 1 |
|||
- _SrcBlend: 1 |
|||
- _UVSec: 0 |
|||
- _ZWrite: 1 |
|||
m_Colors: |
|||
- _Color: {r: 0.5058824, g: 0.74509805, b: 0.25490198, a: 1} |
|||
- _EmissionColor: {r: 0, g: 0, b: 0, a: 1} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 5a1d800a316ca462185fb2cde559a859 |
|||
timeCreated: 1506189863 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 2100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!21 &2100000 |
|||
Material: |
|||
serializedVersion: 6 |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 0} |
|||
m_Name: wall |
|||
m_Shader: {fileID: 46, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_ShaderKeywords: _ALPHAPREMULTIPLY_ON |
|||
m_LightmapFlags: 4 |
|||
m_EnableInstancingVariants: 0 |
|||
m_DoubleSidedGI: 0 |
|||
m_CustomRenderQueue: 3000 |
|||
stringTagMap: |
|||
RenderType: Transparent |
|||
disabledShaderPasses: [] |
|||
m_SavedProperties: |
|||
serializedVersion: 3 |
|||
m_TexEnvs: |
|||
- _BumpMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailAlbedoMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailMask: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _DetailNormalMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _EmissionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MainTex: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _MetallicGlossMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _OcclusionMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
- _ParallaxMap: |
|||
m_Texture: {fileID: 0} |
|||
m_Scale: {x: 1, y: 1} |
|||
m_Offset: {x: 0, y: 0} |
|||
m_Floats: |
|||
- _BumpScale: 1 |
|||
- _Cutoff: 0.5 |
|||
- _DetailNormalMapScale: 1 |
|||
- _DstBlend: 10 |
|||
- _GlossMapScale: 1 |
|||
- _Glossiness: 0.5 |
|||
- _GlossyReflections: 1 |
|||
- _Metallic: 0 |
|||
- _Mode: 3 |
|||
- _OcclusionStrength: 1 |
|||
- _Parallax: 0.02 |
|||
- _SmoothnessTextureChannel: 0 |
|||
- _SpecularHighlights: 1 |
|||
- _SrcBlend: 1 |
|||
- _UVSec: 0 |
|||
- _ZWrite: 0 |
|||
m_Colors: |
|||
- _Color: {r: 0.44705883, g: 0.4509804, b: 0.4627451, a: 0.78431374} |
|||
- _EmissionColor: {r: 0, g: 0, b: 0, a: 1} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 89f7d13576c6e4dca869ab9230b27995 |
|||
timeCreated: 1506376733 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 2100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: f29cfbaff0a0e4f709b21db38252801f |
|||
folderAsset: yes |
|||
timeCreated: 1506376605 |
|||
licenseType: Pro |
|||
DefaultImporter: |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!1001 &100100000 |
|||
Prefab: |
|||
m_ObjectHideFlags: 1 |
|||
serializedVersion: 2 |
|||
m_Modification: |
|||
m_TransformParent: {fileID: 0} |
|||
m_Modifications: [] |
|||
m_RemovedComponents: [] |
|||
m_ParentPrefab: {fileID: 0} |
|||
m_RootGameObject: {fileID: 1471005081904204} |
|||
m_IsPrefabParent: 1 |
|||
--- !u!1 &1351954254040180 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4825862818515900} |
|||
- component: {fileID: 20625028530897182} |
|||
m_Layer: 0 |
|||
m_Name: AgentCam |
|||
m_TagString: MainCamera |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1471005081904204 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4341551706977178} |
|||
- component: {fileID: 33768489696193324} |
|||
- component: {fileID: 65944835440933686} |
|||
- component: {fileID: 23578527932782524} |
|||
- component: {fileID: 54367032332921974} |
|||
- component: {fileID: 114320123443645048} |
|||
- component: {fileID: 114684674594323502} |
|||
m_Layer: 0 |
|||
m_Name: Agent |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!4 &4341551706977178 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1471005081904204} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 1, z: -3} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: |
|||
- {fileID: 4825862818515900} |
|||
m_Father: {fileID: 0} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4825862818515900 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1351954254040180} |
|||
m_LocalRotation: {x: 0.38268343, y: -0, z: -0, w: 0.92387956} |
|||
m_LocalPosition: {x: 0, y: 9, z: -7} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4341551706977178} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 45, y: 0, z: 0} |
|||
--- !u!20 &20625028530897182 |
|||
Camera: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1351954254040180} |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_ClearFlags: 2 |
|||
m_BackGroundColor: {r: 0, g: 0, b: 0, a: 0} |
|||
m_NormalizedViewPortRect: |
|||
serializedVersion: 2 |
|||
x: 0 |
|||
y: 0 |
|||
width: 1 |
|||
height: 1 |
|||
near clip plane: 0.3 |
|||
far clip plane: 1000 |
|||
field of view: 60 |
|||
orthographic: 1 |
|||
orthographic size: 5 |
|||
m_Depth: 1 |
|||
m_CullingMask: |
|||
serializedVersion: 2 |
|||
m_Bits: 4294967295 |
|||
m_RenderingPath: -1 |
|||
m_TargetTexture: {fileID: 0} |
|||
m_TargetDisplay: 0 |
|||
m_TargetEye: 3 |
|||
m_HDR: 1 |
|||
m_AllowMSAA: 1 |
|||
m_ForceIntoRT: 0 |
|||
m_OcclusionCulling: 1 |
|||
m_StereoConvergence: 10 |
|||
m_StereoSeparation: 0.022 |
|||
m_StereoMirrorMode: 0 |
|||
--- !u!23 &23578527932782524 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1471005081904204} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 260483cdfc6b14e26823a02f23bd8baa, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!33 &33768489696193324 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1471005081904204} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!54 &54367032332921974 |
|||
Rigidbody: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1471005081904204} |
|||
serializedVersion: 2 |
|||
m_Mass: 1 |
|||
m_Drag: 0 |
|||
m_AngularDrag: 0.05 |
|||
m_UseGravity: 1 |
|||
m_IsKinematic: 0 |
|||
m_Interpolate: 0 |
|||
m_Constraints: 112 |
|||
m_CollisionDetection: 0 |
|||
--- !u!65 &65944835440933686 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1471005081904204} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!114 &114320123443645048 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1471005081904204} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 4276057469b484664b731803aa947656, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
brain: {fileID: 0} |
|||
observations: |
|||
- {fileID: 20625028530897182} |
|||
maxStep: 1000 |
|||
resetOnDone: 1 |
|||
reward: 0 |
|||
done: 0 |
|||
value: 0 |
|||
CummulativeReward: 0 |
|||
stepCounter: 0 |
|||
agentStoredAction: [] |
|||
memory: [] |
|||
id: 0 |
|||
goalHolder: {fileID: 0} |
|||
--- !u!114 &114684674594323502 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1471005081904204} |
|||
m_Enabled: 0 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: e040eaa8759024abbbb14994dc4c55ee, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
fixedPosition: 0 |
|||
verticalOffset: 2 |
|||
DisplayBrainName: 0 |
|||
DisplayBrainType: 0 |
|||
DisplayFrameCount: 0 |
|||
DisplayCurrentReward: 0 |
|||
DisplayMaxReward: 0 |
|||
DisplayState: 0 |
|||
DisplayAction: 0 |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 959536c2771f44a0489fc25936a43f41 |
|||
timeCreated: 1506376696 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 100100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!1001 &100100000 |
|||
Prefab: |
|||
m_ObjectHideFlags: 1 |
|||
serializedVersion: 2 |
|||
m_Modification: |
|||
m_TransformParent: {fileID: 0} |
|||
m_Modifications: [] |
|||
m_RemovedComponents: [] |
|||
m_ParentPrefab: {fileID: 0} |
|||
m_RootGameObject: {fileID: 1613473834313808} |
|||
m_IsPrefabParent: 1 |
|||
--- !u!1 &1613473834313808 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4825123375970766} |
|||
- component: {fileID: 33204045482639674} |
|||
- component: {fileID: 65659409536765156} |
|||
- component: {fileID: 23124344287969304} |
|||
- component: {fileID: 54231619317383454} |
|||
m_Layer: 0 |
|||
m_Name: Block |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!4 &4825123375970766 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1613473834313808} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 3, y: 1, z: -3} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 0} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!23 &23124344287969304 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1613473834313808} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 668b3b8d9195149df9e09f1a3b0efd98, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!33 &33204045482639674 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1613473834313808} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!54 &54231619317383454 |
|||
Rigidbody: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1613473834313808} |
|||
serializedVersion: 2 |
|||
m_Mass: 1 |
|||
m_Drag: 0 |
|||
m_AngularDrag: 0.05 |
|||
m_UseGravity: 1 |
|||
m_IsKinematic: 0 |
|||
m_Interpolate: 0 |
|||
m_Constraints: 112 |
|||
m_CollisionDetection: 0 |
|||
--- !u!65 &65659409536765156 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1613473834313808} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 3440948a701c14331ac3e95c5fcc211a |
|||
timeCreated: 1506379447 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 100100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!1001 &100100000 |
|||
Prefab: |
|||
m_ObjectHideFlags: 1 |
|||
serializedVersion: 2 |
|||
m_Modification: |
|||
m_TransformParent: {fileID: 0} |
|||
m_Modifications: [] |
|||
m_RemovedComponents: [] |
|||
m_ParentPrefab: {fileID: 0} |
|||
m_RootGameObject: {fileID: 1093938163042392} |
|||
m_IsPrefabParent: 1 |
|||
--- !u!1 &1093938163042392 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4594833237433442} |
|||
- component: {fileID: 33853507630763772} |
|||
- component: {fileID: 65000393534394434} |
|||
- component: {fileID: 23163266357712870} |
|||
m_Layer: 0 |
|||
m_Name: GoalHolder |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1232271100291552 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4019088600287448} |
|||
- component: {fileID: 33803078476476916} |
|||
- component: {fileID: 65139902615771232} |
|||
- component: {fileID: 23831508413836252} |
|||
- component: {fileID: 114488534897618924} |
|||
m_Layer: 0 |
|||
m_Name: Goal |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!4 &4019088600287448 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1232271100291552} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 0.8, y: 1.4, z: 0.8} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4594833237433442} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4594833237433442 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1093938163042392} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0.2, z: 3} |
|||
m_LocalScale: {x: 2.2, y: 1.1, z: 2.2} |
|||
m_Children: |
|||
- {fileID: 4019088600287448} |
|||
m_Father: {fileID: 0} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!23 &23163266357712870 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1093938163042392} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 10303, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23831508413836252 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1232271100291552} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 5a1d800a316ca462185fb2cde559a859, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!33 &33803078476476916 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1232271100291552} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33853507630763772 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1093938163042392} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!65 &65000393534394434 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1093938163042392} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65139902615771232 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1232271100291552} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!114 &114488534897618924 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1232271100291552} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 7f7d39fa1cc584f83aa99151c78122f4, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 7ccb91bfa6fe24c77b2af05f536122c7 |
|||
timeCreated: 1506376607 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 100100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!1001 &100100000 |
|||
Prefab: |
|||
m_ObjectHideFlags: 1 |
|||
serializedVersion: 2 |
|||
m_Modification: |
|||
m_TransformParent: {fileID: 0} |
|||
m_Modifications: [] |
|||
m_RemovedComponents: [] |
|||
m_ParentPrefab: {fileID: 0} |
|||
m_RootGameObject: {fileID: 1279120735226386} |
|||
m_IsPrefabParent: 1 |
|||
--- !u!1 &1059215260888894 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4466531474194842} |
|||
- component: {fileID: 33267997474687550} |
|||
- component: {fileID: 65552681347262880} |
|||
- component: {fileID: 23688276419612968} |
|||
- component: {fileID: 114824876818673492} |
|||
m_Layer: 0 |
|||
m_Name: Goal |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1204575965717360 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4126968495145778} |
|||
m_Layer: 0 |
|||
m_Name: GameObject |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 1 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1279120735226386 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4797372522419518} |
|||
- component: {fileID: 114258304849110948} |
|||
m_Layer: 0 |
|||
m_Name: PushArea |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1493483966197088 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4632585043262026} |
|||
- component: {fileID: 33577517975120114} |
|||
- component: {fileID: 65850181500434670} |
|||
- component: {fileID: 23990588433939486} |
|||
- component: {fileID: 54247299082550478} |
|||
m_Layer: 0 |
|||
m_Name: Block |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1536368250397626 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4140757973958978} |
|||
m_Layer: 0 |
|||
m_Name: GameObject |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1576612233868982 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4119604677329682} |
|||
- component: {fileID: 33517912653557962} |
|||
- component: {fileID: 65033772802134810} |
|||
- component: {fileID: 23991594936726584} |
|||
m_Layer: 0 |
|||
m_Name: GoalHolder |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1684647471145214 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4289233568094604} |
|||
- component: {fileID: 33314271061899244} |
|||
- component: {fileID: 65270983637680522} |
|||
- component: {fileID: 23361251118430556} |
|||
m_Layer: 0 |
|||
m_Name: Ground |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 1 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1842524606753826 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4270194855204468} |
|||
m_Layer: 0 |
|||
m_Name: GameObject |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1893190605547158 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4777271908265906} |
|||
- component: {fileID: 33027222173954196} |
|||
- component: {fileID: 65667507680723650} |
|||
- component: {fileID: 23372235118339718} |
|||
- component: {fileID: 54979596905483200} |
|||
- component: {fileID: 114371909629876940} |
|||
m_Layer: 0 |
|||
m_Name: Agent |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 1 |
|||
m_IsActive: 1 |
|||
--- !u!4 &4119604677329682 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1576612233868982} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 7, y: 0, z: -7} |
|||
m_LocalScale: {x: 3, y: 1, z: 3} |
|||
m_Children: |
|||
- {fileID: 4466531474194842} |
|||
- {fileID: 4140757973958978} |
|||
m_Father: {fileID: 4797372522419518} |
|||
m_RootOrder: 2 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4126968495145778 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1204575965717360} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4289233568094604} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4140757973958978 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1536368250397626} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4119604677329682} |
|||
m_RootOrder: 1 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4270194855204468 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1842524606753826} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4632585043262026} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4289233568094604 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1684647471145214} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: -4} |
|||
m_LocalScale: {x: 10, y: 1, z: 10} |
|||
m_Children: |
|||
- {fileID: 4126968495145778} |
|||
m_Father: {fileID: 4797372522419518} |
|||
m_RootOrder: 1 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4466531474194842 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1059215260888894} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 0.8, y: 1.4, z: 0.8} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4119604677329682} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4632585043262026 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1493483966197088} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 2, y: 1, z: -8} |
|||
m_LocalScale: {x: 2, y: 1, z: 2} |
|||
m_Children: |
|||
- {fileID: 4270194855204468} |
|||
m_Father: {fileID: 4797372522419518} |
|||
m_RootOrder: 3 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4777271908265906 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1893190605547158} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 1, z: -9} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4797372522419518} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4797372522419518 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1279120735226386} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: -10, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: |
|||
- {fileID: 4777271908265906} |
|||
- {fileID: 4289233568094604} |
|||
- {fileID: 4119604677329682} |
|||
- {fileID: 4632585043262026} |
|||
m_Father: {fileID: 0} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!23 &23361251118430556 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1684647471145214} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 10303, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23372235118339718 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1893190605547158} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 260483cdfc6b14e26823a02f23bd8baa, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23688276419612968 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1059215260888894} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 5a1d800a316ca462185fb2cde559a859, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23990588433939486 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1493483966197088} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 668b3b8d9195149df9e09f1a3b0efd98, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23991594936726584 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1576612233868982} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 10303, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!33 &33027222173954196 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1893190605547158} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33267997474687550 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1059215260888894} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33314271061899244 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1684647471145214} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33517912653557962 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1576612233868982} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33577517975120114 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1493483966197088} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!54 &54247299082550478 |
|||
Rigidbody: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1493483966197088} |
|||
serializedVersion: 2 |
|||
m_Mass: 1 |
|||
m_Drag: 0 |
|||
m_AngularDrag: 0.05 |
|||
m_UseGravity: 1 |
|||
m_IsKinematic: 0 |
|||
m_Interpolate: 0 |
|||
m_Constraints: 112 |
|||
m_CollisionDetection: 0 |
|||
--- !u!54 &54979596905483200 |
|||
Rigidbody: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1893190605547158} |
|||
serializedVersion: 2 |
|||
m_Mass: 1 |
|||
m_Drag: 0 |
|||
m_AngularDrag: 0.05 |
|||
m_UseGravity: 1 |
|||
m_IsKinematic: 0 |
|||
m_Interpolate: 0 |
|||
m_Constraints: 112 |
|||
m_CollisionDetection: 0 |
|||
--- !u!65 &65033772802134810 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1576612233868982} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65270983637680522 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1684647471145214} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65552681347262880 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1059215260888894} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65667507680723650 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1893190605547158} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65850181500434670 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1493483966197088} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!114 &114258304849110948 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1279120735226386} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 0572958da97104432a0f155301472bbb, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
block: {fileID: 1493483966197088} |
|||
goalHolder: {fileID: 1576612233868982} |
|||
academy: {fileID: 0} |
|||
--- !u!114 &114371909629876940 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1893190605547158} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 49f021cd5b5ee49a7bbce654270e260e, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
brain: {fileID: 0} |
|||
observations: [] |
|||
maxStep: 1000 |
|||
resetOnDone: 1 |
|||
reward: 0 |
|||
done: 0 |
|||
value: 0 |
|||
CumulativeReward: 0 |
|||
stepCounter: 0 |
|||
agentStoredAction: [] |
|||
memory: [] |
|||
id: 0 |
|||
area: {fileID: 1279120735226386} |
|||
goalHolder: {fileID: 1576612233868982} |
|||
block: {fileID: 1493483966197088} |
|||
--- !u!114 &114824876818673492 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1059215260888894} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 7f7d39fa1cc584f83aa99151c78122f4, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
myAgent: {fileID: 1893190605547158} |
|||
myObject: {fileID: 1493483966197088} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: db6eac8138a454addbb6d1e5f475d886 |
|||
timeCreated: 1506809670 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 100100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
%YAML 1.1 |
|||
%TAG !u! tag:unity3d.com,2011: |
|||
--- !u!1001 &100100000 |
|||
Prefab: |
|||
m_ObjectHideFlags: 1 |
|||
serializedVersion: 2 |
|||
m_Modification: |
|||
m_TransformParent: {fileID: 0} |
|||
m_Modifications: [] |
|||
m_RemovedComponents: [] |
|||
m_ParentPrefab: {fileID: 0} |
|||
m_RootGameObject: {fileID: 1718829686919056} |
|||
m_IsPrefabParent: 1 |
|||
--- !u!1 &1003322958675180 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4027646054827514} |
|||
- component: {fileID: 33310804766006786} |
|||
- component: {fileID: 65805671049923310} |
|||
- component: {fileID: 23989531925820236} |
|||
m_Layer: 0 |
|||
m_Name: Ground |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1091036355213978 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4743003964451344} |
|||
- component: {fileID: 33055054802220634} |
|||
- component: {fileID: 65383542428029016} |
|||
- component: {fileID: 23838418589051694} |
|||
- component: {fileID: 114068218045167000} |
|||
m_Layer: 0 |
|||
m_Name: Goal |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1120334905894282 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4764499261748320} |
|||
m_Layer: 0 |
|||
m_Name: GameObject |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1214336592793772 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4106492414392050} |
|||
m_Layer: 0 |
|||
m_Name: GameObject |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1312874949203312 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4826682057551308} |
|||
- component: {fileID: 33075621139442950} |
|||
- component: {fileID: 65682297171473436} |
|||
- component: {fileID: 23415401456686744} |
|||
- component: {fileID: 54888074337309264} |
|||
m_Layer: 0 |
|||
m_Name: Block |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1506931635139370 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4291466584800356} |
|||
- component: {fileID: 33182874640342044} |
|||
- component: {fileID: 65870467061381816} |
|||
- component: {fileID: 23592361877126024} |
|||
m_Layer: 0 |
|||
m_Name: Wall |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1718829686919056 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4601298475788644} |
|||
- component: {fileID: 114215545026793406} |
|||
m_Layer: 0 |
|||
m_Name: WallArea |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1814211526417990 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4114454554371512} |
|||
m_Layer: 0 |
|||
m_Name: GameObject |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1936799145621512 |
|||
GameObject: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4014430987640782} |
|||
m_Layer: 0 |
|||
m_Name: GameObject |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1960504220667788 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4694771220406452} |
|||
- component: {fileID: 33877165510012086} |
|||
- component: {fileID: 65141972714734648} |
|||
- component: {fileID: 23797186539098740} |
|||
m_Layer: 0 |
|||
m_Name: GoalHolder |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!1 &1986507356043702 |
|||
GameObject: |
|||
m_ObjectHideFlags: 0 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
serializedVersion: 5 |
|||
m_Component: |
|||
- component: {fileID: 4182184265281318} |
|||
- component: {fileID: 33677970134608566} |
|||
- component: {fileID: 65486269132317776} |
|||
- component: {fileID: 23613202787206598} |
|||
- component: {fileID: 54973601004961626} |
|||
- component: {fileID: 114200736018184412} |
|||
m_Layer: 0 |
|||
m_Name: Agent |
|||
m_TagString: Untagged |
|||
m_Icon: {fileID: 0} |
|||
m_NavMeshLayer: 0 |
|||
m_StaticEditorFlags: 0 |
|||
m_IsActive: 1 |
|||
--- !u!4 &4014430987640782 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1936799145621512} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4027646054827514} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4027646054827514 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1003322958675180} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: -4} |
|||
m_LocalScale: {x: 12, y: 1, z: 12} |
|||
m_Children: |
|||
- {fileID: 4014430987640782} |
|||
m_Father: {fileID: 4601298475788644} |
|||
m_RootOrder: 1 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4106492414392050 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1214336592793772} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4826682057551308} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4114454554371512 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1814211526417990} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4694771220406452} |
|||
m_RootOrder: 1 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4182184265281318 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1986507356043702} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 1, z: -9} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4601298475788644} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4291466584800356 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1506931635139370} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: -3} |
|||
m_LocalScale: {x: 12, y: 4, z: 1} |
|||
m_Children: |
|||
- {fileID: 4764499261748320} |
|||
m_Father: {fileID: 4601298475788644} |
|||
m_RootOrder: 3 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4601298475788644 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1718829686919056} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: -10, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: |
|||
- {fileID: 4182184265281318} |
|||
- {fileID: 4027646054827514} |
|||
- {fileID: 4694771220406452} |
|||
- {fileID: 4291466584800356} |
|||
- {fileID: 4826682057551308} |
|||
m_Father: {fileID: 0} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4694771220406452 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1960504220667788} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0.25, z: 0} |
|||
m_LocalScale: {x: 2.2, y: 1.1, z: 2.2} |
|||
m_Children: |
|||
- {fileID: 4743003964451344} |
|||
- {fileID: 4114454554371512} |
|||
m_Father: {fileID: 4601298475788644} |
|||
m_RootOrder: 2 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4743003964451344 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1091036355213978} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 0.8, y: 1.4, z: 0.8} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4694771220406452} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4764499261748320 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1120334905894282} |
|||
m_LocalRotation: {x: 0, y: 0, z: 0, w: 1} |
|||
m_LocalPosition: {x: 0, y: 0, z: 0} |
|||
m_LocalScale: {x: 1, y: 1, z: 1} |
|||
m_Children: [] |
|||
m_Father: {fileID: 4291466584800356} |
|||
m_RootOrder: 0 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!4 &4826682057551308 |
|||
Transform: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1312874949203312} |
|||
m_LocalRotation: {x: -0, y: -0, z: -0, w: 1} |
|||
m_LocalPosition: {x: 2, y: 1, z: -8} |
|||
m_LocalScale: {x: 2, y: 1, z: 1} |
|||
m_Children: |
|||
- {fileID: 4106492414392050} |
|||
m_Father: {fileID: 4601298475788644} |
|||
m_RootOrder: 4 |
|||
m_LocalEulerAnglesHint: {x: 0, y: 0, z: 0} |
|||
--- !u!23 &23415401456686744 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1312874949203312} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 668b3b8d9195149df9e09f1a3b0efd98, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23592361877126024 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1506931635139370} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 89f7d13576c6e4dca869ab9230b27995, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23613202787206598 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1986507356043702} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 260483cdfc6b14e26823a02f23bd8baa, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23797186539098740 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1960504220667788} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 10303, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23838418589051694 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1091036355213978} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 2100000, guid: 5a1d800a316ca462185fb2cde559a859, type: 2} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!23 &23989531925820236 |
|||
MeshRenderer: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1003322958675180} |
|||
m_Enabled: 1 |
|||
m_CastShadows: 1 |
|||
m_ReceiveShadows: 1 |
|||
m_DynamicOccludee: 1 |
|||
m_MotionVectors: 1 |
|||
m_LightProbeUsage: 1 |
|||
m_ReflectionProbeUsage: 1 |
|||
m_Materials: |
|||
- {fileID: 10303, guid: 0000000000000000f000000000000000, type: 0} |
|||
m_StaticBatchInfo: |
|||
firstSubMesh: 0 |
|||
subMeshCount: 0 |
|||
m_StaticBatchRoot: {fileID: 0} |
|||
m_ProbeAnchor: {fileID: 0} |
|||
m_LightProbeVolumeOverride: {fileID: 0} |
|||
m_ScaleInLightmap: 1 |
|||
m_PreserveUVs: 1 |
|||
m_IgnoreNormalsForChartDetection: 0 |
|||
m_ImportantGI: 0 |
|||
m_StitchLightmapSeams: 0 |
|||
m_SelectedEditorRenderState: 3 |
|||
m_MinimumChartSize: 4 |
|||
m_AutoUVMaxDistance: 0.5 |
|||
m_AutoUVMaxAngle: 89 |
|||
m_LightmapParameters: {fileID: 0} |
|||
m_SortingLayerID: 0 |
|||
m_SortingLayer: 0 |
|||
m_SortingOrder: 0 |
|||
--- !u!33 &33055054802220634 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1091036355213978} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33075621139442950 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1312874949203312} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33182874640342044 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1506931635139370} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33310804766006786 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1003322958675180} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33677970134608566 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1986507356043702} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!33 &33877165510012086 |
|||
MeshFilter: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1960504220667788} |
|||
m_Mesh: {fileID: 10202, guid: 0000000000000000e000000000000000, type: 0} |
|||
--- !u!54 &54888074337309264 |
|||
Rigidbody: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1312874949203312} |
|||
serializedVersion: 2 |
|||
m_Mass: 1 |
|||
m_Drag: 0 |
|||
m_AngularDrag: 0.05 |
|||
m_UseGravity: 1 |
|||
m_IsKinematic: 0 |
|||
m_Interpolate: 0 |
|||
m_Constraints: 112 |
|||
m_CollisionDetection: 0 |
|||
--- !u!54 &54973601004961626 |
|||
Rigidbody: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1986507356043702} |
|||
serializedVersion: 2 |
|||
m_Mass: 1 |
|||
m_Drag: 0 |
|||
m_AngularDrag: 0.05 |
|||
m_UseGravity: 1 |
|||
m_IsKinematic: 0 |
|||
m_Interpolate: 0 |
|||
m_Constraints: 112 |
|||
m_CollisionDetection: 0 |
|||
--- !u!65 &65141972714734648 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1960504220667788} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65383542428029016 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1091036355213978} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65486269132317776 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1986507356043702} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65682297171473436 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1312874949203312} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65805671049923310 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1003322958675180} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!65 &65870467061381816 |
|||
BoxCollider: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1506931635139370} |
|||
m_Material: {fileID: 0} |
|||
m_IsTrigger: 0 |
|||
m_Enabled: 1 |
|||
serializedVersion: 2 |
|||
m_Size: {x: 1, y: 1, z: 1} |
|||
m_Center: {x: 0, y: 0, z: 0} |
|||
--- !u!114 &114068218045167000 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1091036355213978} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 7f7d39fa1cc584f83aa99151c78122f4, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
myAgent: {fileID: 1986507356043702} |
|||
myObject: {fileID: 1986507356043702} |
|||
--- !u!114 &114200736018184412 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1986507356043702} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 4276057469b484664b731803aa947656, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
brain: {fileID: 0} |
|||
observations: [] |
|||
maxStep: 1000 |
|||
resetOnDone: 1 |
|||
reward: 0 |
|||
done: 0 |
|||
value: 0 |
|||
CumulativeReward: 0 |
|||
stepCounter: 0 |
|||
agentStoredAction: [] |
|||
memory: [] |
|||
id: 0 |
|||
area: {fileID: 1718829686919056} |
|||
goalHolder: {fileID: 1960504220667788} |
|||
block: {fileID: 1312874949203312} |
|||
wall: {fileID: 1506931635139370} |
|||
--- !u!114 &114215545026793406 |
|||
MonoBehaviour: |
|||
m_ObjectHideFlags: 1 |
|||
m_PrefabParentObject: {fileID: 0} |
|||
m_PrefabInternal: {fileID: 100100000} |
|||
m_GameObject: {fileID: 1718829686919056} |
|||
m_Enabled: 1 |
|||
m_EditorHideFlags: 0 |
|||
m_Script: {fileID: 11500000, guid: 8852782dcebdd427799bf307c5ef2314, type: 3} |
|||
m_Name: |
|||
m_EditorClassIdentifier: |
|||
wall: {fileID: 1506931635139370} |
|||
academy: {fileID: 0} |
|||
block: {fileID: 1312874949203312} |
|||
goalHolder: {fileID: 1960504220667788} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: 2f5be533719824ee78ab11f49b193ef3 |
|||
timeCreated: 1506471890 |
|||
licenseType: Pro |
|||
NativeFormatImporter: |
|||
mainObjectFileID: 100100000 |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
1001
unity-environment/Assets/ML-Agents/Examples/Area/Push.unity
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
|
|||
fileFormatVersion: 2 |
|||
guid: 1faf90b0c489d45aab7a6111f56bfc56 |
|||
timeCreated: 1506808980 |
|||
licenseType: Pro |
|||
DefaultImporter: |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: b412b865c66f042ad8cf9b2e2ae8ebad |
|||
folderAsset: yes |
|||
timeCreated: 1503355437 |
|||
licenseType: Free |
|||
DefaultImporter: |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
using System.Collections; |
|||
using System.Collections.Generic; |
|||
using UnityEngine; |
|||
|
|||
public class Area : MonoBehaviour { |
|||
|
|||
// Use this for initialization
|
|||
void Start () { |
|||
|
|||
} |
|||
|
|||
// Update is called once per frame
|
|||
void Update () { |
|||
|
|||
} |
|||
|
|||
public virtual void ResetArea() { |
|||
|
|||
} |
|||
} |
|||
部分文件因为文件数量过多而无法显示
撰写
预览
正在加载...
取消
保存
Reference in new issue