浏览代码
Merge branch 'master' of github.com:Unity-Technologies/ml-agents into develop-sac-apex
/develop/sac-apex
Merge branch 'master' of github.com:Unity-Technologies/ml-agents into develop-sac-apex
/develop/sac-apex
当前提交
0bc4cc1e
共有 51 个文件被更改,包括 3208 次插入 和 4183 次删除
-
2Project/Assets/ML-Agents/Examples/3DBall/Demos/Expert3DBall.demo.meta
-
2Project/Assets/ML-Agents/Examples/3DBall/Demos/Expert3DBallHard.demo.meta
-
2Project/Assets/ML-Agents/Examples/Basic/Demos/ExpertBasic.demo.meta
-
2Project/Assets/ML-Agents/Examples/Bouncer/Demos/ExpertBouncer.demo.meta
-
2Project/Assets/ML-Agents/Examples/Crawler/Demos/ExpertCrawlerDyn.demo.meta
-
2Project/Assets/ML-Agents/Examples/Crawler/Demos/ExpertCrawlerSta.demo.meta
-
2Project/Assets/ML-Agents/Examples/FoodCollector/Demos/ExpertFood.demo.meta
-
2Project/Assets/ML-Agents/Examples/GridWorld/Demos/ExpertGrid.demo.meta
-
2Project/Assets/ML-Agents/Examples/Hallway/Demos/ExpertHallway.demo.meta
-
2Project/Assets/ML-Agents/Examples/PushBlock/Demos/ExpertPush.demo.meta
-
2Project/Assets/ML-Agents/Examples/Pyramids/Demos/ExpertPyramid.demo.meta
-
2Project/Assets/ML-Agents/Examples/Reacher/Demos/ExpertReacher.demo.meta
-
2Project/Assets/ML-Agents/Examples/Tennis/Demos/ExpertTennis.demo.meta
-
2Project/Assets/ML-Agents/Examples/Walker/Demos/ExpertWalker.demo.meta
-
2Project/ProjectSettings/ProjectVersion.txt
-
308com.unity.ml-agents/CHANGELOG.md
-
78com.unity.ml-agents/Editor/DemonstrationDrawer.cs
-
26com.unity.ml-agents/Editor/DemonstrationImporter.cs
-
68com.unity.ml-agents/Runtime/Communicator/GrpcExtensions.cs
-
2com.unity.ml-agents/Runtime/Demonstrations/DemonstrationWriter.cs
-
35com.unity.ml-agents/Runtime/Timer.cs
-
43com.unity.ml-agents/Tests/Editor/TimerTest.cs
-
92docs/FAQ.md
-
346docs/Getting-Started.md
-
120docs/Installation-Anaconda-Windows.md
-
508docs/Learning-Environment-Design-Agents.md
-
644docs/Learning-Environment-Examples.md
-
84docs/Learning-Environment-Executable.md
-
39docs/ML-Agents-Overview.md
-
100docs/Readme.md
-
6docs/Training-Imitation-Learning.md
-
368docs/Training-ML-Agents.md
-
147docs/Training-on-Amazon-Web-Service.md
-
145docs/Training-on-Microsoft-Azure.md
-
36docs/Using-Docker.md
-
82docs/Using-Tensorboard.md
-
66docs/Using-Virtual-Environment.md
-
257docs/images/demo_inspector.png
-
999docs/images/docker_build_settings.png
-
198docs/images/learning_environment_basic.png
-
545docs/images/learning_environment_example.png
-
604docs/images/unity_package_json.png
-
999docs/images/unity_package_manager_window.png
-
95ml-agents/mlagents/trainers/learn.py
-
22com.unity.ml-agents/Runtime/Demonstrations/DemonstrationMetaData.cs
-
11com.unity.ml-agents/Runtime/Demonstrations/DemonstrationMetaData.cs.meta
-
37com.unity.ml-agents/Runtime/Demonstrations/DemonstrationSummary.cs
-
122docs/images/learning_environment_full.png
-
38com.unity.ml-agents/Runtime/Demonstrations/Demonstration.cs
-
91docs/Training-on-Microsoft-Azure-Custom-Instance.md
-
0/com.unity.ml-agents/Runtime/Demonstrations/DemonstrationSummary.cs.meta
|
|||
m_EditorVersion: 2018.4.18f1 |
|||
m_EditorVersion: 2018.4.17f1 |
|||
|
|||
# Changelog |
|||
|
|||
and this project adheres to [Semantic Versioning](http://semver.org/spec/v2.0.0.html). |
|||
|
|||
and this project adheres to |
|||
[Semantic Versioning](http://semver.org/spec/v2.0.0.html). |
|||
|
|||
- The `--load` and `--train` command-line flags have been deprecated. Training now happens by default, and |
|||
use `--resume` to resume training instead. (#3705) |
|||
- The Jupyter notebooks have been removed from the repository. |
|||
- Introduced the `SideChannelUtils` to register, unregister and access side channels. |
|||
- `Academy.FloatProperties` was removed, please use `SideChannelUtils.GetSideChannel<FloatPropertiesChannel>()` instead. |
|||
- Removed the multi-agent gym option from the gym wrapper. For multi-agent scenarios, use the [Low Level Python API](Python-API.md). |
|||
- The low level Python API has changed. You can look at the document [Low Level Python API documentation](Python-API.md) for more information. If you use `mlagents-learn` for training, this should be a transparent change. |
|||
- Added ability to start training (initialize model weights) from a previous run ID. (#3710) |
|||
- The internal event `Academy.AgentSetStatus` was renamed to `Academy.AgentPreStep` and made public. |
|||
- The offset logic was removed from DecisionRequester. |
|||
- The signature of `Agent.Heuristic()` was changed to take a `float[]` as a parameter, instead of returning the array. This was done to prevent a common source of error where users would return arrays of the wrong size. |
|||
- The communication API version has been bumped up to 1.0.0 and will use [Semantic Versioning](https://semver.org/) to do compatibility checks for communication between Unity and the Python process. |
|||
- The obsolete `Agent` methods `GiveModel`, `Done`, `InitializeAgent`, `AgentAction` and `AgentReset` have been removed. |
|||
|
|||
- The `--load` and `--train` command-line flags have been deprecated. Training |
|||
now happens by default, and use `--resume` to resume training instead. (#3705) |
|||
- The Jupyter notebooks have been removed from the repository. |
|||
- Introduced the `SideChannelUtils` to register, unregister and access side |
|||
channels. |
|||
- `Academy.FloatProperties` was removed, please use |
|||
`SideChannelUtils.GetSideChannel<FloatPropertiesChannel>()` instead. |
|||
- Removed the multi-agent gym option from the gym wrapper. For multi-agent |
|||
scenarios, use the [Low Level Python API](../docs/Python-API.md). |
|||
- The low level Python API has changed. You can look at the document |
|||
[Low Level Python API documentation](../docs/Python-API.md) for more |
|||
information. If you use `mlagents-learn` for training, this should be a |
|||
transparent change. |
|||
- Added ability to start training (initialize model weights) from a previous run |
|||
ID. (#3710) |
|||
- The internal event `Academy.AgentSetStatus` was renamed to |
|||
`Academy.AgentPreStep` and made public. |
|||
- The offset logic was removed from DecisionRequester. |
|||
- The signature of `Agent.Heuristic()` was changed to take a `float[]` as a |
|||
parameter, instead of returning the array. This was done to prevent a common |
|||
source of error where users would return arrays of the wrong size. |
|||
- The communication API version has been bumped up to 1.0.0 and will use |
|||
[Semantic Versioning](https://semver.org/) to do compatibility checks for |
|||
communication between Unity and the Python process. |
|||
- The obsolete `Agent` methods `GiveModel`, `Done`, `InitializeAgent`, |
|||
`AgentAction` and `AgentReset` have been removed. |
|||
- Format of console output has changed slightly and now matches the name of the model/summary directory. (#3630, #3616) |
|||
- Added a feature to allow sending stats from C# environments to TensorBoard (and other python StatsWriters). To do this from your code, use `SideChannelUtils.GetSideChannel<StatsSideChannel>().AddStat(key, value)` (#3660) |
|||
- Renamed 'Generalization' feature to 'Environment Parameter Randomization'. |
|||
- Timer files now contain a dictionary of metadata, including things like the package version numbers. |
|||
- SideChannel IncomingMessages methods now take an optional default argument, which is used when trying to read more data than the message contains. |
|||
- The way that UnityEnvironment decides the port was changed. If no port is specified, the behavior will depend on the `file_name` parameter. If it is `None`, 5004 (the editor port) will be used; otherwise 5005 (the base environment port) will be used. |
|||
- Fixed an issue where exceptions from environments provided a returncode of 0. (#3680) |
|||
- Running `mlagents-learn` with the same `--run-id` twice will no longer overwrite the existing files. (#3705) |
|||
- `StackingSensor` was changed from `internal` visibility to `public` |
|||
- Updated Barracuda to 0.6.3-preview. |
|||
- Model updates now happen asynchronously with environment steps. (#3690) |
|||
|
|||
- Format of console output has changed slightly and now matches the name of the |
|||
model/summary directory. (#3630, #3616) |
|||
- Added a feature to allow sending stats from C# environments to TensorBoard |
|||
(and other python StatsWriters). To do this from your code, use |
|||
`SideChannelUtils.GetSideChannel<StatsSideChannel>().AddStat(key, value)` |
|||
(#3660) |
|||
- Renamed 'Generalization' feature to 'Environment Parameter Randomization'. |
|||
- Timer files now contain a dictionary of metadata, including things like the |
|||
package version numbers. |
|||
- SideChannel IncomingMessages methods now take an optional default argument, |
|||
which is used when trying to read more data than the message contains. |
|||
- The way that UnityEnvironment decides the port was changed. If no port is |
|||
specified, the behavior will depend on the `file_name` parameter. If it is |
|||
`None`, 5004 (the editor port) will be used; otherwise 5005 (the base |
|||
environment port) will be used. |
|||
- Fixed an issue where exceptions from environments provided a returncode of 0. |
|||
(#3680) |
|||
- Running `mlagents-learn` with the same `--run-id` twice will no longer |
|||
overwrite the existing files. (#3705) |
|||
- `StackingSensor` was changed from `internal` visibility to `public` |
|||
- Updated Barracuda to 0.6.3-preview. |
|||
- Model updates can now happen asynchronously with environment steps for better performance. (#3690) |
|||
### Bug Fixes |
|||
|
|||
- Fixed a display bug when viewing Demonstration files in the inspector. The |
|||
shapes of the observations in the file now display correctly. (#3771) |
|||
|
|||
|
|||
- Raise the wall in CrawlerStatic scene to prevent Agent from falling off. (#3650) |
|||
- Fixed an issue where specifying `vis_encode_type` was required only for SAC. (#3677) |
|||
- Fixed the reported entropy values for continuous actions (#3684) |
|||
- Fixed an issue where switching models using `SetModel()` during training would use an excessive amount of memory. (#3664) |
|||
- Environment subprocesses now close immediately on timeout or wrong API version. (#3679) |
|||
- Fixed an issue in the gym wrapper that would raise an exception if an Agent called EndEpisode multiple times in the same step. (#3700) |
|||
- Fixed an issue where logging output was not visible; logging levels are now set consistently. (#3703) |
|||
- Raise the wall in CrawlerStatic scene to prevent Agent from falling off. |
|||
(#3650) |
|||
- Fixed an issue where specifying `vis_encode_type` was required only for SAC. |
|||
(#3677) |
|||
- Fixed the reported entropy values for continuous actions (#3684) |
|||
- Fixed an issue where switching models using `SetModel()` during training would |
|||
use an excessive amount of memory. (#3664) |
|||
- Environment subprocesses now close immediately on timeout or wrong API |
|||
version. (#3679) |
|||
- Fixed an issue in the gym wrapper that would raise an exception if an Agent |
|||
called EndEpisode multiple times in the same step. (#3700) |
|||
- Fixed an issue where logging output was not visible; logging levels are now |
|||
set consistently. (#3703) |
|||
|
|||
- `Agent.CollectObservations` now takes a VectorSensor argument. (#3352, #3389) |
|||
- Added `Agent.CollectDiscreteActionMasks` virtual method with a `DiscreteActionMasker` argument to specify which discrete actions are unavailable to the Agent. (#3525) |
|||
- Beta support for ONNX export was added. If the `tf2onnx` python package is installed, models will be saved to `.onnx` as well as `.nn` format. |
|||
Note that Barracuda 0.6.0 or later is required to import the `.onnx` files properly |
|||
- Multi-GPU training and the `--multi-gpu` option has been removed temporarily. (#3345) |
|||
- All Sensor related code has been moved to the namespace `MLAgents.Sensors`. |
|||
- All SideChannel related code has been moved to the namespace `MLAgents.SideChannels`. |
|||
- `BrainParameters` and `SpaceType` have been removed from the public API |
|||
- `BehaviorParameters` have been removed from the public API. |
|||
- The following methods in the `Agent` class have been deprecated and will be removed in a later release: |
|||
- `InitializeAgent()` was renamed to `Initialize()` |
|||
- `AgentAction()` was renamed to `OnActionReceived()` |
|||
- `AgentReset()` was renamed to `OnEpisodeBegin()` |
|||
- `Done()` was renamed to `EndEpisode()` |
|||
- `GiveModel()` was renamed to `SetModel()` |
|||
|
|||
- `Agent.CollectObservations` now takes a VectorSensor argument. (#3352, #3389) |
|||
- Added `Agent.CollectDiscreteActionMasks` virtual method with a |
|||
`DiscreteActionMasker` argument to specify which discrete actions are |
|||
unavailable to the Agent. (#3525) |
|||
- Beta support for ONNX export was added. If the `tf2onnx` python package is |
|||
installed, models will be saved to `.onnx` as well as `.nn` format. Note that |
|||
Barracuda 0.6.0 or later is required to import the `.onnx` files properly |
|||
- Multi-GPU training and the `--multi-gpu` option has been removed temporarily. |
|||
(#3345) |
|||
- All Sensor related code has been moved to the namespace `MLAgents.Sensors`. |
|||
- All SideChannel related code has been moved to the namespace |
|||
`MLAgents.SideChannels`. |
|||
- `BrainParameters` and `SpaceType` have been removed from the public API |
|||
- `BehaviorParameters` have been removed from the public API. |
|||
- The following methods in the `Agent` class have been deprecated and will be |
|||
removed in a later release: |
|||
- `InitializeAgent()` was renamed to `Initialize()` |
|||
- `AgentAction()` was renamed to `OnActionReceived()` |
|||
- `AgentReset()` was renamed to `OnEpisodeBegin()` |
|||
- `Done()` was renamed to `EndEpisode()` |
|||
- `GiveModel()` was renamed to `SetModel()` |
|||
- Monitor.cs was moved to Examples. (#3372) |
|||
- Automatic stepping for Academy is now controlled from the AutomaticSteppingEnabled property. (#3376) |
|||
- The GetEpisodeCount, GetStepCount, GetTotalStepCount and methods of Academy were changed to EpisodeCount, StepCount, TotalStepCount properties respectively. (#3376) |
|||
- Several classes were changed from public to internal visibility. (#3390) |
|||
- Academy.RegisterSideChannel and UnregisterSideChannel methods were added. (#3391) |
|||
- A tutorial on adding custom SideChannels was added (#3391) |
|||
- The stepping logic for the Agent and the Academy has been simplified (#3448) |
|||
- Update Barracuda to 0.6.1-preview |
|||
* The interface for `RayPerceptionSensor.PerceiveStatic()` was changed to take an input class and write to an output class, and the method was renamed to `Perceive()`. |
|||
- The checkpoint file suffix was changed from `.cptk` to `.ckpt` (#3470) |
|||
- The command-line argument used to determine the port that an environment will listen on was changed from `--port` to `--mlagents-port`. |
|||
- `DemonstrationRecorder` can now record observations outside of the editor. |
|||
- `DemonstrationRecorder` now has an optional path for the demonstrations. This will default to `Application.dataPath` if not set. |
|||
- `DemonstrationStore` was changed to accept a `Stream` for its constructor, and was renamed to `DemonstrationWriter` |
|||
- The method `GetStepCount()` on the Agent class has been replaced with the property getter `StepCount` |
|||
- `RayPerceptionSensorComponent` and related classes now display the debug gizmos whenever the Agent is selected (not just Play mode). |
|||
- Most fields on `RayPerceptionSensorComponent` can now be changed while the editor is in Play mode. The exceptions to this are fields that affect the number of observations. |
|||
- Most fields on `CameraSensorComponent` and `RenderTextureSensorComponent` were changed to private and replaced by properties with the same name. |
|||
- Unused static methods from the `Utilities` class (ShiftLeft, ReplaceRange, AddRangeNoAlloc, and GetSensorFloatObservationSize) were removed. |
|||
- The `Agent` class is no longer abstract. |
|||
- SensorBase was moved out of the package and into the Examples directory. |
|||
- `AgentInfo.actionMasks` has been renamed to `AgentInfo.discreteActionMasks`. |
|||
- `DecisionRequester` has been made internal (you can still use the DecisionRequesterComponent from the inspector). `RepeatAction` was renamed `TakeActionsBetweenDecisions` for clarity. (#3555) |
|||
- The `IFloatProperties` interface has been removed. |
|||
- Fix #3579. |
|||
- Improved inference performance for models with multiple action branches. (#3598) |
|||
- Fixed an issue when using GAIL with less than `batch_size` number of demonstrations. (#3591) |
|||
- The interfaces to the `SideChannel` classes (on C# and python) have changed to use new `IncomingMessage` and `OutgoingMessage` classes. These should make reading and writing data to the channel easier. (#3596) |
|||
- Updated the ExpertPyramid.demo example demonstration file (#3613) |
|||
- Updated project version for example environments to 2018.4.18f1. (#3618) |
|||
- Changed the Product Name in the example environments to remove spaces, so that the default build executable file doesn't contain spaces. (#3612) |
|||
|
|||
- Monitor.cs was moved to Examples. (#3372) |
|||
- Automatic stepping for Academy is now controlled from the |
|||
AutomaticSteppingEnabled property. (#3376) |
|||
- The GetEpisodeCount, GetStepCount, GetTotalStepCount and methods of Academy |
|||
were changed to EpisodeCount, StepCount, TotalStepCount properties |
|||
respectively. (#3376) |
|||
- Several classes were changed from public to internal visibility. (#3390) |
|||
- Academy.RegisterSideChannel and UnregisterSideChannel methods were added. |
|||
(#3391) |
|||
- A tutorial on adding custom SideChannels was added (#3391) |
|||
- The stepping logic for the Agent and the Academy has been simplified (#3448) |
|||
- Update Barracuda to 0.6.1-preview |
|||
|
|||
* The interface for `RayPerceptionSensor.PerceiveStatic()` was changed to take |
|||
an input class and write to an output class, and the method was renamed to |
|||
`Perceive()`. |
|||
|
|||
- The checkpoint file suffix was changed from `.cptk` to `.ckpt` (#3470) |
|||
- The command-line argument used to determine the port that an environment will |
|||
listen on was changed from `--port` to `--mlagents-port`. |
|||
- `DemonstrationRecorder` can now record observations outside of the editor. |
|||
- `DemonstrationRecorder` now has an optional path for the demonstrations. This |
|||
will default to `Application.dataPath` if not set. |
|||
- `DemonstrationStore` was changed to accept a `Stream` for its constructor, and |
|||
was renamed to `DemonstrationWriter` |
|||
- The method `GetStepCount()` on the Agent class has been replaced with the |
|||
property getter `StepCount` |
|||
- `RayPerceptionSensorComponent` and related classes now display the debug |
|||
gizmos whenever the Agent is selected (not just Play mode). |
|||
- Most fields on `RayPerceptionSensorComponent` can now be changed while the |
|||
editor is in Play mode. The exceptions to this are fields that affect the |
|||
number of observations. |
|||
- Most fields on `CameraSensorComponent` and `RenderTextureSensorComponent` were |
|||
changed to private and replaced by properties with the same name. |
|||
- Unused static methods from the `Utilities` class (ShiftLeft, ReplaceRange, |
|||
AddRangeNoAlloc, and GetSensorFloatObservationSize) were removed. |
|||
- The `Agent` class is no longer abstract. |
|||
- SensorBase was moved out of the package and into the Examples directory. |
|||
- `AgentInfo.actionMasks` has been renamed to `AgentInfo.discreteActionMasks`. |
|||
- `DecisionRequester` has been made internal (you can still use the |
|||
DecisionRequesterComponent from the inspector). `RepeatAction` was renamed |
|||
`TakeActionsBetweenDecisions` for clarity. (#3555) |
|||
- The `IFloatProperties` interface has been removed. |
|||
- Fix #3579. |
|||
- Improved inference performance for models with multiple action branches. |
|||
(#3598) |
|||
- Fixed an issue when using GAIL with less than `batch_size` number of |
|||
demonstrations. (#3591) |
|||
- The interfaces to the `SideChannel` classes (on C# and python) have changed to |
|||
use new `IncomingMessage` and `OutgoingMessage` classes. These should make |
|||
reading and writing data to the channel easier. (#3596) |
|||
- Updated the ExpertPyramid.demo example demonstration file (#3613) |
|||
- Updated project version for example environments to 2018.4.18f1. (#3618) |
|||
- Changed the Product Name in the example environments to remove spaces, so that |
|||
the default build executable file doesn't contain spaces. (#3612) |
|||
- Fixed an issue which caused self-play training sessions to consume a lot of memory. (#3451) |
|||
- Fixed an IndexError when using GAIL or behavioral cloning with demonstrations recorded with 0.14.0 or later (#3464) |
|||
|
|||
- Fixed an issue which caused self-play training sessions to consume a lot of |
|||
memory. (#3451) |
|||
- Fixed an IndexError when using GAIL or behavioral cloning with demonstrations |
|||
recorded with 0.14.0 or later (#3464) |
|||
- Fixed a bug with the rewards of multiple Agents in the gym interface (#3471, #3496) |
|||
|
|||
- Fixed a bug with the rewards of multiple Agents in the gym interface (#3471, |
|||
#3496) |
|||
- A new self-play mechanism for training agents in adversarial scenarios was added (#3194) |
|||
- Tennis and Soccer environments were refactored to enable training with self-play (#3194, #3331) |
|||
- UnitySDK folder was split into a Unity Package (com.unity.ml-agents) and our examples were moved to the Project folder (#3267) |
|||
|
|||
- A new self-play mechanism for training agents in adversarial scenarios was |
|||
added (#3194) |
|||
- Tennis and Soccer environments were refactored to enable training with |
|||
self-play (#3194, #3331) |
|||
- UnitySDK folder was split into a Unity Package (com.unity.ml-agents) and our |
|||
examples were moved to the Project folder (#3267) |
|||
- In order to reduce the size of the API, several classes and methods were marked as internal or private. Some public fields on the Agent were trimmed (#3342, #3353, #3269) |
|||
- Decision Period and on-demand decision checkboxes were removed from the Agent. on-demand decision is now the default (#3243) |
|||
- Calling Done() on the Agent will reset it immediately and call the AgentReset virtual method (#3291, #3242) |
|||
- The "Reset on Done" setting in AgentParameters was removed; this is now always true. AgentOnDone virtual method on the Agent was removed (#3311, #3222) |
|||
- Trainer steps are now counted per-Agent, not per-environment as in previous versions. For instance, if you have 10 Agents in the scene, 20 environment steps now correspond to 200 steps as printed in the terminal and in Tensorboard (#3113) |
|||
- In order to reduce the size of the API, several classes and methods were |
|||
marked as internal or private. Some public fields on the Agent were trimmed |
|||
(#3342, #3353, #3269) |
|||
- Decision Period and on-demand decision checkboxes were removed from the Agent. |
|||
on-demand decision is now the default (#3243) |
|||
- Calling Done() on the Agent will reset it immediately and call the AgentReset |
|||
virtual method (#3291, #3242) |
|||
- The "Reset on Done" setting in AgentParameters was removed; this is now always |
|||
true. AgentOnDone virtual method on the Agent was removed (#3311, #3222) |
|||
- Trainer steps are now counted per-Agent, not per-environment as in previous |
|||
versions. For instance, if you have 10 Agents in the scene, 20 environment |
|||
steps now correspond to 200 steps as printed in the terminal and in |
|||
Tensorboard (#3113) |
|||
|
|||
- Curriculum config files are now YAML formatted and all curricula for a training run are combined into a single file (#3186) |
|||
- ML-Agents components, such as BehaviorParameters and various Sensor implementations, now appear in the Components menu (#3231) |
|||
- Exceptions are now raised in Unity (in debug mode only) if NaN observations or rewards are passed (#3221) |
|||
- RayPerception MonoBehavior, which was previously deprecated, was removed (#3304) |
|||
- Uncompressed visual (i.e. 3d float arrays) observations are now supported. CameraSensorComponent and RenderTextureSensor now have an option to write uncompressed observations (#3148) |
|||
- Agent’s handling of observations during training was improved so that an extra copy of the observations is no longer maintained (#3229) |
|||
- Error message for missing trainer config files was improved to include the absolute path (#3230) |
|||
- Curriculum config files are now YAML formatted and all curricula for a |
|||
training run are combined into a single file (#3186) |
|||
- ML-Agents components, such as BehaviorParameters and various Sensor |
|||
implementations, now appear in the Components menu (#3231) |
|||
- Exceptions are now raised in Unity (in debug mode only) if NaN observations or |
|||
rewards are passed (#3221) |
|||
- RayPerception MonoBehavior, which was previously deprecated, was removed |
|||
(#3304) |
|||
- Uncompressed visual (i.e. 3d float arrays) observations are now supported. |
|||
CameraSensorComponent and RenderTextureSensor now have an option to write |
|||
uncompressed observations (#3148) |
|||
- Agent’s handling of observations during training was improved so that an extra |
|||
copy of the observations is no longer maintained (#3229) |
|||
- Error message for missing trainer config files was improved to include the |
|||
absolute path (#3230) |
|||
|
|||
- A bug that caused RayPerceptionSensor to behave inconsistently with transforms that have non-1 scale was fixed (#3321) |
|||
- Some small bugfixes to tensorflow_to_barracuda.py were backported from the barracuda release (#3341) |
|||
- Base port in the jupyter notebook example was updated to use the same port that the editor uses (#3283) |
|||
|
|||
- A bug that caused RayPerceptionSensor to behave inconsistently with transforms |
|||
that have non-1 scale was fixed (#3321) |
|||
- Some small bugfixes to tensorflow_to_barracuda.py were backported from the |
|||
barracuda release (#3341) |
|||
- Base port in the jupyter notebook example was updated to use the same port |
|||
that the editor uses (#3283) |
|||
### This is the first release of *Unity Package ML-Agents*. |
|||
### This is the first release of _Unity Package ML-Agents_. |
|||
*Short description of this release* |
|||
_Short description of this release_ |
|||
|
|||
# Training ML-Agents |
|||
|
|||
The ML-Agents toolkit conducts training using an external Python training |
|||
process. During training, this external process communicates with the Academy |
|||
to generate a block of agent experiences. These |
|||
experiences become the training set for a neural network used to optimize the |
|||
agent's policy (which is essentially a mathematical function mapping |
|||
observations to actions). In reinforcement learning, the neural network |
|||
optimizes the policy by maximizing the expected rewards. In imitation learning, |
|||
the neural network optimizes the policy to achieve the smallest difference |
|||
between the actions chosen by the agent trainee and the actions chosen by the |
|||
expert in the same situation. |
|||
|
|||
The output of the training process is a model file containing the optimized |
|||
policy. This model file is a TensorFlow data graph containing the mathematical |
|||
operations and the optimized weights selected during the training process. You |
|||
can set the generated model file in the Behaviors Parameters under your |
|||
Agent in your Unity project to decide the best course of action for an agent. |
|||
|
|||
Use the command `mlagents-learn` to train your agents. This command is installed |
|||
with the `mlagents` package and its implementation can be found at |
|||
`ml-agents/mlagents/trainers/learn.py`. The [configuration file](#training-config-file), |
|||
like `config/trainer_config.yaml` specifies the hyperparameters used during training. |
|||
You can edit this file with a text editor to add a specific configuration for |
|||
each Behavior. |
|||
For a broad overview of reinforcement learning, imitation learning and all the |
|||
training scenarios, methods and options within the ML-Agents Toolkit, see |
|||
[ML-Agents Toolkit Overview](ML-Agents-Overview.md). |
|||
For a broader overview of reinforcement learning, imitation learning and the |
|||
ML-Agents training process, see [ML-Agents Toolkit |
|||
Overview](ML-Agents-Overview.md). |
|||
Once your learning environment has been created and is ready for training, the |
|||
next step is to initiate a training run. Training in the ML-Agents Toolkit is |
|||
powered by a dedicated Python package, `mlagents`. This package exposes a |
|||
command `mlagents-learn` that is the single entry point for all training |
|||
workflows (e.g. reinforcement leaning, imitation learning, curriculum learning). |
|||
Its implementation can be found at |
|||
[ml-agents/mlagents/trainers/learn.py](../ml-agents/mlagents/trainers/learn.py). |
|||
Use the `mlagents-learn` command to train agents. `mlagents-learn` supports |
|||
training with |
|||
[reinforcement learning](Background-Machine-Learning.md#reinforcement-learning), |
|||
[curriculum learning](Training-Curriculum-Learning.md), |
|||
and [behavioral cloning imitation learning](Training-Imitation-Learning.md). |
|||
### Starting Training |
|||
Run `mlagents-learn` from the command line to launch the training process. Use |
|||
the command line patterns and the `config/trainer_config.yaml` file to control |
|||
training options. |
|||
`mlagents-learn` is the main training utility provided by the ML-Agents Toolkit. |
|||
It accepts a number of CLI options in addition to a YAML configuration file that |
|||
contains all the configurations and hyperparameters to be used during training. |
|||
The set of configurations and hyperparameters to include in this file depend on |
|||
the agents in your environment and the specific training method you wish to |
|||
utilize. Keep in mind that the hyperparameter values can have a big impact on |
|||
the training performance (i.e. your agent's ability to learn a policy that |
|||
solves the task). In this page, we will review all the hyperparameters for all |
|||
training methods and provide guidelines and advice on their values. |
|||
The basic command for training is: |
|||
To view a description of all the CLI options accepted by `mlagents-learn`, use |
|||
the `--help`: |
|||
mlagents-learn <trainer-config-file> --env=<env_name> --run-id=<run-identifier> |
|||
mlagents-learn --help |
|||
where |
|||
|
|||
* `<trainer-config-file>` is the file path of the trainer configuration yaml. |
|||
* `<env_name>`__(Optional)__ is the name (including path) of your Unity |
|||
executable containing the agents to be trained. If `<env_name>` is not passed, |
|||
the training will happen in the Editor. Press the :arrow_forward: button in |
|||
Unity when the message _"Start training by pressing the Play button in the |
|||
Unity Editor"_ is displayed on the screen. |
|||
* `<run-identifier>` is an optional identifier you can use to identify the |
|||
results of individual training runs. |
|||
|
|||
For example, suppose you have a project in Unity named "CatsOnBicycles" which |
|||
contains agents ready to train. To perform the training: |
|||
|
|||
1. [Build the project](Learning-Environment-Executable.md), making sure that you |
|||
only include the training scene. |
|||
2. Open a terminal or console window. |
|||
3. Navigate to the directory where you installed the ML-Agents Toolkit. |
|||
4. Run the following to launch the training process using the path to the Unity |
|||
environment you built in step 1: |
|||
The basic command for training is: |
|||
mlagents-learn config/trainer_config.yaml --env=../../projects/Cats/CatsOnBicycles.app --run-id=cob_1 |
|||
mlagents-learn <trainer-config-file> --env=<env_name> --run-id=<run-identifier> |
|||
During a training session, the training program prints out and saves updates at |
|||
regular intervals (specified by the `summary_freq` option). The saved statistics |
|||
are grouped by the `run-id` value so you should assign a unique id to each |
|||
training run if you plan to view the statistics. You can view these statistics |
|||
using TensorBoard during or after training by running the following command: |
|||
where |
|||
```sh |
|||
tensorboard --logdir=summaries --port 6006 |
|||
``` |
|||
- `<trainer-config-file>` is the file path of the trainer configuration yaml. |
|||
This contains all the hyperparameter values. We offer a detailed guide on the |
|||
structure of this file and the meaning of the hyperameters (and advice on how |
|||
to set them) in the dedicated [Training Config File](#training-config-file) |
|||
section below. |
|||
- `<env_name>`**(Optional)** is the name (including path) of your |
|||
[Unity executable](Learning-Environment-Executable.md) containing the agents |
|||
to be trained. If `<env_name>` is not passed, the training will happen in the |
|||
Editor. Press the :arrow_forward: button in Unity when the message _"Start |
|||
training by pressing the Play button in the Unity Editor"_ is displayed on |
|||
the screen. |
|||
- `<run-identifier>` is a unique name you can use to identify the results of |
|||
your training runs. |
|||
And then opening the URL: [localhost:6006](http://localhost:6006). |
|||
See the |
|||
[Getting Started Guide](Getting-Started.md#training-a-new-model-with-reinforcement-learning) |
|||
for a sample execution of the `mlagents-learn` command. |
|||
**Note:** The default port TensorBoard uses is 6006. If there is an existing session |
|||
running on port 6006 a new session can be launched on an open port using the --port |
|||
option. |
|||
#### Observing Training |
|||
When training is finished, you can find the saved model in the `models` folder |
|||
under the assigned run-id — in the cats example, the path to the model would be |
|||
`models/cob_1/CatsOnBicycles_cob_1.nn`. |
|||
Regardless of which training methods, configurations or hyperparameters you |
|||
provide, the training process will always generate three artifacts: |
|||
While this example used the default training hyperparameters, you can edit the |
|||
[trainer_config.yaml file](#training-config-file) with a text editor to set |
|||
different values. |
|||
1. Summaries (under the `summaries/` folder): these are training metrics that |
|||
are updated throughout the training process. They are helpful to monitor your |
|||
training performance and may help inform how to update your hyperparameter |
|||
values. See [Using TensorBoard](Using-Tensorboard.md) for more details on how |
|||
to visualize the training metrics. |
|||
1. Models (under the `models/` folder): these contain the model checkpoints that |
|||
are updated throughout training and the final model file (`.nn`). This final |
|||
model file is generated once either when training completes or is |
|||
interrupted. |
|||
1. Timers file (also under the `summaries/` folder): this contains aggregated |
|||
metrics on your training process, including time spent on specific code |
|||
blocks. See [Profiling in Python](Profiling-Python.md) for more information |
|||
on the timers generated. |
|||
To interrupt training and save the current progress, hit Ctrl+C once and wait for the |
|||
model to be saved out. |
|||
These artifacts (except the `.nn` file) are updated throughout the training |
|||
process and finalized when training completes or is interrupted. |
|||
### Loading an Existing Model |
|||
#### Stopping and Resuming Training |
|||
If you've quit training early using Ctrl+C, you can resume the training run by running |
|||
`mlagents-learn` again, specifying the same `<run-identifier>` and appending the `--resume` flag |
|||
to the command. |
|||
To interrupt training and save the current progress, hit `Ctrl+C` once and wait |
|||
for the model(s) to be saved out. |
|||
You can also use this mode to run inference of an already-trained model in Python. |
|||
Append both the `--resume` and `--inference` to do this. Note that if you want to run |
|||
inference in Unity, you should use the |
|||
[Unity Inference Engine](Getting-started#Running-a-pre-trained-model). |
|||
To resume a previously interrupted or completed training run, use the `--resume` |
|||
flag and make sure to specify the previously used run ID. |
|||
If you've already trained a model using the specified `<run-identifier>` and `--resume` is not |
|||
specified, you will not be able to continue with training. Use `--force` to force ML-Agents to |
|||
overwrite the existing data. |
|||
If you would like to re-run a previously interrupted or completed training run |
|||
and re-use the same run ID (in this case, overwriting the previously generated |
|||
artifacts), then use the `--force` flag. |
|||
Alternatively, you might want to start a new training run but _initialize_ it using an already-trained |
|||
model. You may want to do this, for instance, if your environment changed and you want |
|||
a new model, but the old behavior is still better than random. You can do this by specifying `--initialize-from=<run-identifier>`, where `<run-identifier>` is the old run ID. |
|||
#### Loading an Existing Model |
|||
### Command Line Training Options |
|||
You can also use this mode to run inference of an already-trained model in |
|||
Python by using both the `--resume` and `--inference` flags. Note that if you |
|||
want to run inference in Unity, you should use the |
|||
[Unity Inference Engine](Getting-Started.md#running-a-pre-trained-model). |
|||
In addition to passing the path of the Unity executable containing your training |
|||
environment, you can set the following command line options when invoking |
|||
`mlagents-learn`: |
|||
Alternatively, you might want to start a new training run but _initialize_ it |
|||
using an already-trained model. You may want to do this, for instance, if your |
|||
environment changed and you want a new model, but the old behavior is still |
|||
better than random. You can do this by specifying |
|||
`--initialize-from=<run-identifier>`, where `<run-identifier>` is the old run |
|||
ID. |
|||
* `--env=<env>`: Specify an executable environment to train. |
|||
* `--curriculum=<file>`: Specify a curriculum JSON file for defining the |
|||
lessons for curriculum training. See [Curriculum |
|||
Training](Training-Curriculum-Learning.md) for more information. |
|||
* `--sampler=<file>`: Specify a sampler YAML file for defining the |
|||
sampler for parameter randomization. See [Environment Parameter Randomization](Training-Environment-Parameter-Randomization.md) for more information. |
|||
* `--keep-checkpoints=<n>`: Specify the maximum number of model checkpoints to |
|||
keep. Checkpoints are saved after the number of steps specified by the |
|||
`save-freq` option. Once the maximum number of checkpoints has been reached, |
|||
the oldest checkpoint is deleted when saving a new checkpoint. Defaults to 5. |
|||
* `--lesson=<n>`: Specify which lesson to start with when performing curriculum |
|||
training. Defaults to 0. |
|||
* `--num-envs=<n>`: Specifies the number of concurrent Unity environment instances to |
|||
collect experiences from when training. Defaults to 1. |
|||
* `--run-id=<run-identifier>`: Specifies an identifier for each training run. This |
|||
identifier is used to name the subdirectories in which the trained model and |
|||
summary statistics are saved as well as the saved model itself. The default id |
|||
is "ppo". If you use TensorBoard to view the training statistics, always set a |
|||
unique run-id for each training run. (The statistics for all runs with the |
|||
same id are combined as if they were produced by a the same session.) |
|||
* `--save-freq=<n>`: Specifies how often (in steps) to save the model during |
|||
training. Defaults to 50000. |
|||
* `--seed=<n>`: Specifies a number to use as a seed for the random number |
|||
generator used by the training code. |
|||
* `--env-args=<string>`: Specify arguments for the executable environment. Be aware that |
|||
the standalone build will also process these as |
|||
[Unity Command Line Arguments](https://docs.unity3d.com/Manual/CommandLineArguments.html). |
|||
You should choose different argument names if you want to create environment-specific arguments. |
|||
All arguments after this flag will be passed to the executable. For example, setting |
|||
`mlagents-learn config/trainer_config.yaml --env-args --num-orcs 42` would result in |
|||
` --num-orcs 42` passed to the executable. |
|||
* `--base-port`: Specifies the starting port. Each concurrent Unity environment instance |
|||
will get assigned a port sequentially, starting from the `base-port`. Each instance |
|||
will use the port `(base_port + worker_id)`, where the `worker_id` is sequential IDs |
|||
given to each instance from 0 to `num_envs - 1`. Default is 5005. __Note:__ When |
|||
training using the Editor rather than an executable, the base port will be ignored. |
|||
* `--inference`: Specifies whether to only run in inference mode. Omit to train the model. |
|||
To load an existing model, specify a run-id and combine with `--resume`. |
|||
* `--resume`: If set, the training code loads an already trained model to |
|||
initialize the neural network before training. The learning code looks for the |
|||
model in `models/<run-id>/` (which is also where it saves models at the end of |
|||
training). This option only works when the models exist, and have the same behavior names |
|||
as the current agents in your scene. |
|||
* `--force`: Attempting to train a model with a run-id that has been used before will |
|||
throw an error. Use `--force` to force-overwrite this run-id's summary and model data. |
|||
* `--initialize-from=<run-identifier>`: Specify an old run-id here to initialize your model from |
|||
a previously trained model. Note that the previously saved models _must_ have the same behavior |
|||
parameters as your current environment. |
|||
* `--no-graphics`: Specify this option to run the Unity executable in |
|||
`-batchmode` and doesn't initialize the graphics driver. Use this only if your |
|||
training doesn't involve visual observations (reading from Pixels). See |
|||
[here](https://docs.unity3d.com/Manual/CommandLineArguments.html) for more |
|||
details. |
|||
* `--debug`: Specify this option to enable debug-level logging for some parts of the code. |
|||
* `--cpu`: Forces training using CPU only. |
|||
* Engine Configuration : |
|||
* `--width` : The width of the executable window of the environment(s) in pixels |
|||
(ignored for editor training) (Default 84) |
|||
* `--height` : The height of the executable window of the environment(s) in pixels |
|||
(ignored for editor training). (Default 84) |
|||
* `--quality-level` : The quality level of the environment(s). Equivalent to |
|||
calling `QualitySettings.SetQualityLevel` in Unity. (Default 5) |
|||
* `--time-scale` : The time scale of the Unity environment(s). Equivalent to setting |
|||
`Time.timeScale` in Unity. (Default 20.0, maximum 100.0) |
|||
* `--target-frame-rate` : The target frame rate of the Unity environment(s). |
|||
Equivalent to setting `Application.targetFrameRate` in Unity. (Default: -1) |
|||
## Training Config File |
|||
### Training Config File |
|||
The Unity ML-Agents Toolkit provides a wide range of training scenarios, methods |
|||
and options. As such, specific training runs may require different training |
|||
configurations and may generate different artifacts and TensorBoard statistics. |
|||
This section offers a detailed guide into how to manage the different training |
|||
set-ups withing the toolkit. |
|||
The training config files `config/trainer_config.yaml`, `config/sac_trainer_config.yaml`, |
|||
`config/gail_config.yaml` and `config/offline_bc_config.yaml` specifies the training method, |
|||
the hyperparameters, and a few additional values to use when training with Proximal Policy |
|||
Optimization(PPO), Soft Actor-Critic(SAC), GAIL (Generative Adversarial Imitation Learning) |
|||
with PPO/SAC, and Behavioral Cloning(BC)/Imitation with PPO/SAC. These files are divided |
|||
into sections. The **default** section defines the default values for all the available |
|||
training with PPO, SAC, GAIL (with PPO), and BC. These files are divided into sections. |
|||
The **default** section defines the default values for all the available settings. You can |
|||
also add new sections to override these defaults to train specific Behaviors. Name each of these |
|||
override sections after the appropriate `Behavior Name`. Sections for the |
|||
The training config files `config/trainer_config.yaml`, |
|||
`config/sac_trainer_config.yaml`, `config/gail_config.yaml` and |
|||
`config/offline_bc_config.yaml` specifies the training method, the |
|||
hyperparameters, and a few additional values to use when training with Proximal |
|||
Policy Optimization(PPO), Soft Actor-Critic(SAC), GAIL (Generative Adversarial |
|||
Imitation Learning) with PPO/SAC, and Behavioral Cloning(BC)/Imitation with |
|||
PPO/SAC. These files are divided into sections. The **default** section defines |
|||
the default values for all the available training with PPO, SAC, GAIL (with |
|||
PPO), and BC. These files are divided into sections. The **default** section |
|||
defines the default values for all the available settings. You can also add new |
|||
sections to override these defaults to train specific Behaviors. Name each of |
|||
these override sections after the appropriate `Behavior Name`. Sections for the |
|||
| **Setting** | **Description** | **Applies To Trainer\*** | |
|||
| :------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :----------------------- | |
|||
| batch_size | The number of experiences in each iteration of gradient descent. | PPO, SAC | |
|||
| batches_per_epoch | In imitation learning, the number of batches of training examples to collect before training the model. | | |
|||
| beta | The strength of entropy regularization. | PPO | |
|||
| buffer_size | The number of experiences to collect before updating the policy model. In SAC, the max size of the experience buffer. | PPO, SAC | |
|||
| buffer_init_steps | The number of experiences to collect into the buffer before updating the policy model. | SAC | |
|||
| epsilon | Influences how rapidly the policy can evolve during training. | PPO | |
|||
| hidden_units | The number of units in the hidden layers of the neural network. | PPO, SAC | |
|||
| init_entcoef | How much the agent should explore in the beginning of training. | SAC | |
|||
| lambd | The regularization parameter. | PPO | |
|||
| learning_rate | The initial learning rate for gradient descent. | PPO, SAC | |
|||
| learning_rate_schedule | Determines how learning rate changes over time. | PPO, SAC | |
|||
| max_steps | The maximum number of simulation steps to run during a training session. | PPO, SAC | |
|||
| memory_size | The size of the memory an agent must keep. Used for training with a recurrent neural network. See [Using Recurrent Neural Networks](Feature-Memory.md). | PPO, SAC | |
|||
| normalize | Whether to automatically normalize observations. | PPO, SAC | |
|||
| num_epoch | The number of passes to make through the experience buffer when performing gradient descent optimization. | PPO | |
|||
| num_layers | The number of hidden layers in the neural network. | PPO, SAC | |
|||
| behavioral_cloning | Use demonstrations to bootstrap the policy neural network. See [Pretraining Using Demonstrations](Training-PPO.md#optional-behavioral-cloning-using-demonstrations). | PPO, SAC | |
|||
| reward_signals | The reward signals used to train the policy. Enable Curiosity and GAIL here. See [Reward Signals](Reward-Signals.md) for configuration options. | PPO, SAC | |
|||
| save_replay_buffer | Saves the replay buffer when exiting training, and loads it on resume. | SAC | |
|||
| sequence_length | Defines how long the sequences of experiences must be while training. Only used for training with a recurrent neural network. See [Using Recurrent Neural Networks](Feature-Memory.md). | PPO, SAC | |
|||
| summary_freq | How often, in steps, to save training statistics. This determines the number of data points shown by TensorBoard. | PPO, SAC | |
|||
| tau | How aggressively to update the target network used for bootstrapping value estimation in SAC. | SAC | |
|||
| time_horizon | How many steps of experience to collect per-agent before adding it to the experience buffer. | PPO, SAC | |
|||
| trainer | The type of training to perform: "ppo", "sac", "offline_bc" or "online_bc". | PPO, SAC | |
|||
| train_interval | How often to update the agent. | SAC | |
|||
| steps_per_update | Ratio of agent steps per mini-batch update. | SAC | |
|||
| use_recurrent | Train using a recurrent neural network. See [Using Recurrent Neural Networks](Feature-Memory.md). | PPO, SAC | |
|||
| init_path | Initialize trainer from a previously saved model. | PPO, SAC | |
|||
\*PPO = Proximal Policy Optimization, SAC = Soft Actor-Critic, BC = Behavioral |
|||
Cloning (Imitation), GAIL = Generative Adversarial Imitation Learning |
|||
\*PPO = Proximal Policy Optimization, SAC = Soft Actor-Critic, BC = Behavioral Cloning (Imitation), GAIL = Generative Adversarial Imitaiton Learning |
|||
| **Setting** | **Description** | **Applies To Trainer\*** | |
|||
| :--------------------- | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | :----------------------- | |
|||
| batch_size | The number of experiences in each iteration of gradient descent. | PPO, SAC | |
|||
| batches_per_epoch | In imitation learning, the number of batches of training examples to collect before training the model. | | |
|||
| beta | The strength of entropy regularization. | PPO | |
|||
| buffer_size | The number of experiences to collect before updating the policy model. In SAC, the max size of the experience buffer. | PPO, SAC | |
|||
| buffer_init_steps | The number of experiences to collect into the buffer before updating the policy model. | SAC | |
|||
| epsilon | Influences how rapidly the policy can evolve during training. | PPO | |
|||
| hidden_units | The number of units in the hidden layers of the neural network. | PPO, SAC | |
|||
| init_entcoef | How much the agent should explore in the beginning of training. | SAC | |
|||
| lambd | The regularization parameter. | PPO | |
|||
| learning_rate | The initial learning rate for gradient descent. | PPO, SAC | |
|||
| learning_rate_schedule | Determines how learning rate changes over time. | PPO, SAC | |
|||
| max_steps | The maximum number of simulation steps to run during a training session. | PPO, SAC | |
|||
| memory_size | The size of the memory an agent must keep. Used for training with a recurrent neural network. See [Using Recurrent Neural Networks](Feature-Memory.md). | PPO, SAC | |
|||
| normalize | Whether to automatically normalize observations. | PPO, SAC | |
|||
| num_epoch | The number of passes to make through the experience buffer when performing gradient descent optimization. | PPO | |
|||
| num_layers | The number of hidden layers in the neural network. | PPO, SAC | |
|||
| behavioral_cloning | Use demonstrations to bootstrap the policy neural network. See [Pretraining Using Demonstrations](Training-PPO.md#optional-behavioral-cloning-using-demonstrations). | PPO, SAC | |
|||
| reward_signals | The reward signals used to train the policy. Enable Curiosity and GAIL here. See [Reward Signals](Reward-Signals.md) for configuration options. | PPO, SAC | |
|||
| save_replay_buffer | Saves the replay buffer when exiting training, and loads it on resume. | SAC | |
|||
| sequence_length | Defines how long the sequences of experiences must be while training. Only used for training with a recurrent neural network. See [Using Recurrent Neural Networks](Feature-Memory.md). | PPO, SAC | |
|||
| summary_freq | How often, in steps, to save training statistics. This determines the number of data points shown by TensorBoard. | PPO, SAC | |
|||
| tau | How aggressively to update the target network used for bootstrapping value estimation in SAC. | SAC | |
|||
| time_horizon | How many steps of experience to collect per-agent before adding it to the experience buffer. | PPO, SAC | |
|||
| trainer | The type of training to perform: "ppo", "sac", "offline_bc" or "online_bc". | PPO, SAC | |
|||
| steps_per_update | Ratio of agent steps per mini-batch update. | SAC | |
|||
| use_recurrent | Train using a recurrent neural network. See [Using Recurrent Neural Networks](Feature-Memory.md). | PPO, SAC | |
|||
| init_path | Initialize trainer from a previously saved model. | PPO, SAC | |
|||
| threaded | Run the trainer in a parallel thread from the environment steps. (Default: true) | PPO, SAC | |
|||
* [Training with PPO](Training-PPO.md) |
|||
* [Training with SAC](Training-SAC.md) |
|||
* [Using Recurrent Neural Networks](Feature-Memory.md) |
|||
* [Training with Curriculum Learning](Training-Curriculum-Learning.md) |
|||
* [Training with Imitation Learning](Training-Imitation-Learning.md) |
|||
* [Training with Environment Parameter Randomization](Training-Environment-Parameter-Randomization.md) |
|||
- [Training with PPO](Training-PPO.md) |
|||
- [Training with SAC](Training-SAC.md) |
|||
- [Training with Self-Play](Training-Self-Play.md) |
|||
- [Using Recurrent Neural Networks](Feature-Memory.md) |
|||
- [Training with Curriculum Learning](Training-Curriculum-Learning.md) |
|||
- [Training with Imitation Learning](Training-Imitation-Learning.md) |
|||
- [Training with Environment Parameter Randomization](Training-Environment-Parameter-Randomization.md) |
|||
[example environments](Learning-Environment-Examples.md) |
|||
to the corresponding sections of the `config/trainer_config.yaml` file for each |
|||
example to see how the hyperparameters and other configuration variables have |
|||
been changed from the defaults. |
|||
|
|||
### Debugging and Profiling |
|||
If you enable the `--debug` flag in the command line, the trainer metrics are logged to a CSV file |
|||
stored in the `summaries` directory. The metrics stored are: |
|||
* brain name |
|||
* time to update policy |
|||
* time since start of training |
|||
* time for last experience collection |
|||
* number of experiences used for training |
|||
* mean return |
|||
|
|||
This option is not available currently for Behavioral Cloning. |
|||
|
|||
Additionally, we have included basic [Profiling in Python](Profiling-Python.md) as part of the toolkit. |
|||
This information is also saved in the `summaries` directory. |
|||
[example environments](Learning-Environment-Examples.md) to the corresponding |
|||
sections of the `config/trainer_config.yaml` file for each example to see how |
|||
the hyperparameters and other configuration variables have been changed from the |
|||
defaults. |
|||
{kind=link}
| 之前 | 之后 |
|---|---|
|
|

|
| 宽度: 245 | 高度: 236 | 大小: 13 KiB |
999
docs/images/docker_build_settings.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
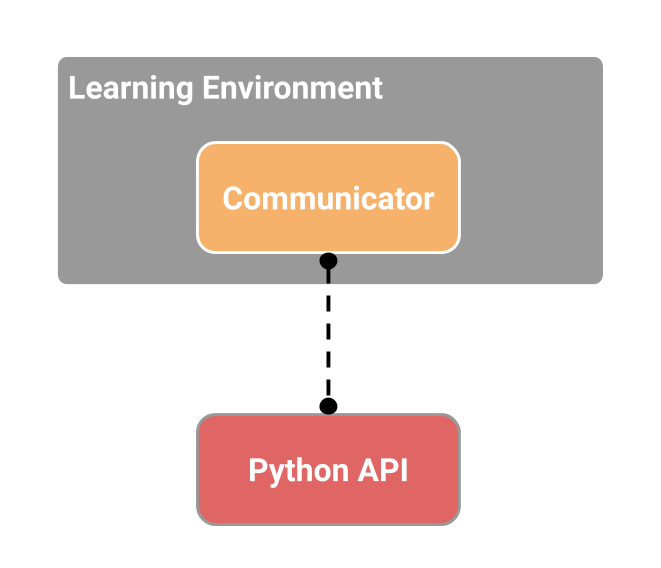
|
| 宽度: 661 | 高度: 568 | 大小: 13 KiB |
545
docs/images/learning_environment_example.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
{kind=link}
| 之前 | 之后 |
|---|---|
|
|

|
| 宽度: 1117 | 高度: 596 | 大小: 128 KiB |
999
docs/images/unity_package_manager_window.png
文件差异内容过多而无法显示
查看文件
文件差异内容过多而无法显示
查看文件
{kind=link}
|
|||
using System; |
|||
using UnityEngine; |
|||
using MLAgents.Policies; |
|||
using UnityEngine.Serialization; |
|||
|
|||
namespace MLAgents.Demonstrations |
|||
{ |
|||
/// <summary>
|
|||
/// Demonstration meta-data.
|
|||
/// Kept in a struct for easy serialization and deserialization.
|
|||
/// </summary>
|
|||
[Serializable] |
|||
internal class DemonstrationMetaData |
|||
{ |
|||
[FormerlySerializedAs("numberExperiences")] |
|||
public int numberSteps; |
|||
public int numberEpisodes; |
|||
public float meanReward; |
|||
public string demonstrationName; |
|||
public const int ApiVersion = 1; |
|||
} |
|||
} |
|||
|
|||
fileFormatVersion: 2 |
|||
guid: af5f3b4258a2d4ead90e733f30cfaa7a |
|||
MonoImporter: |
|||
externalObjects: {} |
|||
serializedVersion: 2 |
|||
defaultReferences: [] |
|||
executionOrder: 0 |
|||
icon: {instanceID: 0} |
|||
userData: |
|||
assetBundleName: |
|||
assetBundleVariant: |
|||
|
|||
using System; |
|||
using System.Collections.Generic; |
|||
using UnityEngine; |
|||
using MLAgents.Policies; |
|||
|
|||
namespace MLAgents.Demonstrations |
|||
{ |
|||
/// <summary>
|
|||
/// Summary of a loaded Demonstration file. Only used for display in the Inspector.
|
|||
/// </summary>
|
|||
[Serializable] |
|||
internal class DemonstrationSummary : ScriptableObject |
|||
{ |
|||
public DemonstrationMetaData metaData; |
|||
public BrainParameters brainParameters; |
|||
public List<ObservationSummary> observationSummaries; |
|||
|
|||
public void Initialize(BrainParameters brainParams, |
|||
DemonstrationMetaData demonstrationMetaData, List<ObservationSummary> obsSummaries) |
|||
{ |
|||
brainParameters = brainParams; |
|||
metaData = demonstrationMetaData; |
|||
observationSummaries = obsSummaries; |
|||
} |
|||
} |
|||
|
|||
|
|||
/// <summary>
|
|||
/// Summary of a loaded Observation. Currently only contains the shape of the Observation.
|
|||
/// </summary>
|
|||
/// <remarks>This is necessary because serialization doesn't support nested containers or arrays.</remarks>
|
|||
[Serializable] |
|||
internal struct ObservationSummary |
|||
{ |
|||
public int[] shape; |
|||
} |
|||
} |
|||
{kind=link}
| 之前 | 之后 |
|---|---|
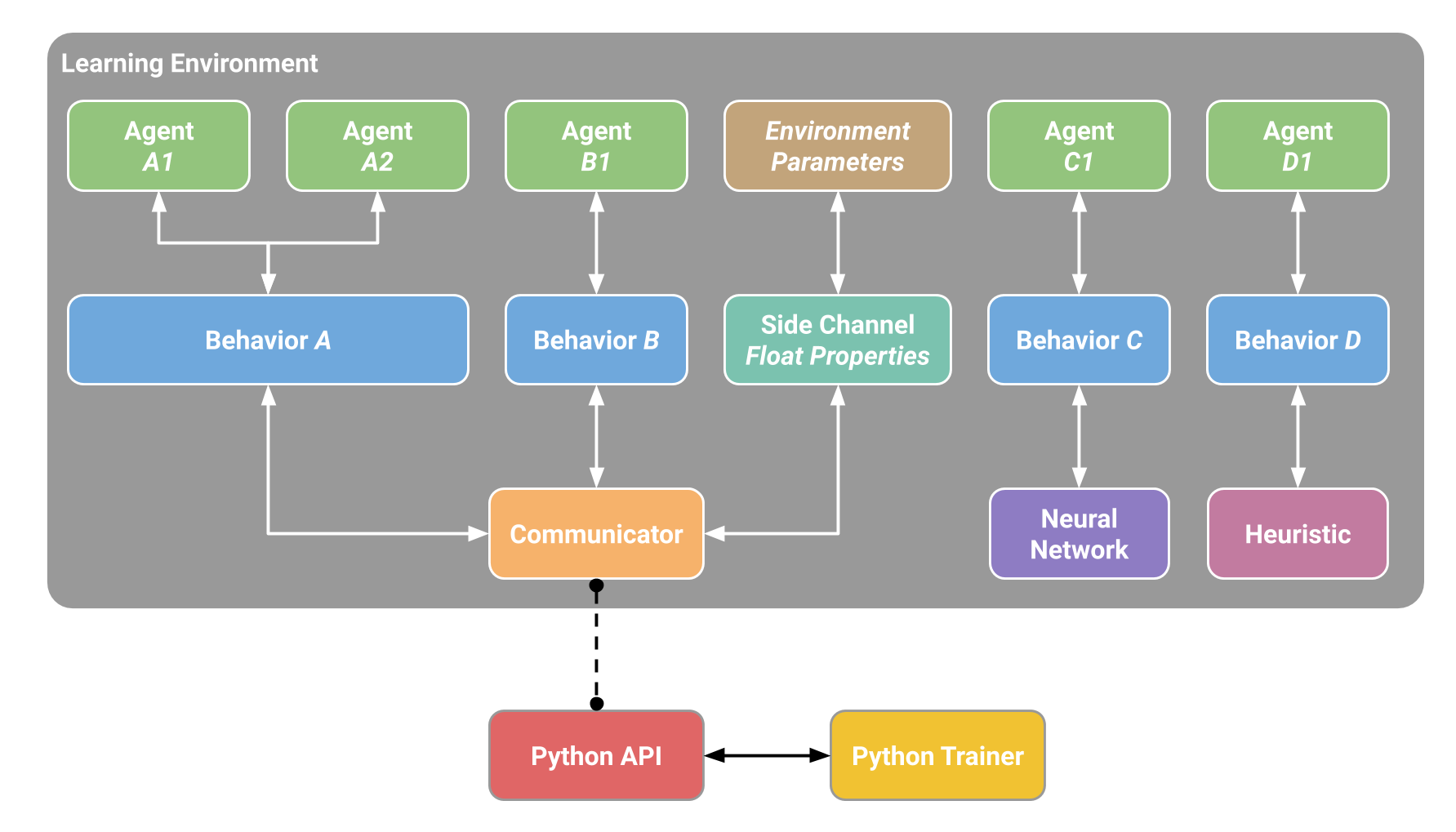
|
|
| 宽度: 1783 | 高度: 1019 | 大小: 71 KiB |
|
|||
using System; |
|||
using UnityEngine; |
|||
using MLAgents.Policies; |
|||
|
|||
namespace MLAgents.Demonstrations |
|||
{ |
|||
/// <summary>
|
|||
/// Demonstration Object. Contains meta-data regarding demonstration.
|
|||
/// Used for imitation learning, or other forms of learning from data.
|
|||
/// </summary>
|
|||
[Serializable] |
|||
internal class Demonstration : ScriptableObject |
|||
{ |
|||
public DemonstrationMetaData metaData; |
|||
public BrainParameters brainParameters; |
|||
|
|||
public void Initialize(BrainParameters brainParams, |
|||
DemonstrationMetaData demonstrationMetaData) |
|||
{ |
|||
brainParameters = brainParams; |
|||
metaData = demonstrationMetaData; |
|||
} |
|||
} |
|||
|
|||
/// <summary>
|
|||
/// Demonstration meta-data.
|
|||
/// Kept in a struct for easy serialization and deserialization.
|
|||
/// </summary>
|
|||
[Serializable] |
|||
internal class DemonstrationMetaData |
|||
{ |
|||
public int numberExperiences; |
|||
public int numberEpisodes; |
|||
public float meanReward; |
|||
public string demonstrationName; |
|||
public const int ApiVersion = 1; |
|||
} |
|||
} |
|||
|
|||
# Setting up a Custom Instance on Microsoft Azure for Training (works with the ML-Agents toolkit v0.3) |
|||
|
|||
This page contains instructions for setting up a custom Virtual Machine on Microsoft Azure so you can running ML-Agents training in the cloud. |
|||
|
|||
1. Start by |
|||
[deploying an Azure VM](https://docs.microsoft.com/azure/virtual-machines/linux/quick-create-portal) |
|||
with Ubuntu Linux (tests were done with 16.04 LTS). To use GPU support, use |
|||
a N-Series VM. |
|||
2. SSH into your VM. |
|||
3. Start with the following commands to install the Nvidia driver: |
|||
|
|||
```sh |
|||
wget http://us.download.nvidia.com/tesla/375.66/nvidia-diag-driver-local-repo-ubuntu1604_375.66-1_amd64.deb |
|||
|
|||
sudo dpkg -i nvidia-diag-driver-local-repo-ubuntu1604_375.66-1_amd64.deb |
|||
|
|||
sudo apt-get update |
|||
|
|||
sudo apt-get install cuda-drivers |
|||
|
|||
sudo reboot |
|||
``` |
|||
|
|||
4. After a minute you should be able to reconnect to your VM and install the |
|||
CUDA toolkit: |
|||
|
|||
```sh |
|||
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb |
|||
|
|||
sudo dpkg -i cuda-repo-ubuntu1604_8.0.61-1_amd64.deb |
|||
|
|||
sudo apt-get update |
|||
|
|||
sudo apt-get install cuda-8-0 |
|||
``` |
|||
|
|||
5. You'll next need to download cuDNN from the Nvidia developer site. This |
|||
requires a registered account. |
|||
|
|||
6. Navigate to [http://developer.nvidia.com](http://developer.nvidia.com) and |
|||
create an account and verify it. |
|||
|
|||
7. Download (to your own computer) cuDNN from [this url](https://developer.nvidia.com/compute/machine-learning/cudnn/secure/v6/prod/8.0_20170307/Ubuntu16_04_x64/libcudnn6_6.0.20-1+cuda8.0_amd64-deb). |
|||
|
|||
8. Copy the deb package to your VM: |
|||
|
|||
```sh |
|||
scp libcudnn6_6.0.21-1+cuda8.0_amd64.deb <VMUserName>@<VMIPAddress>:libcudnn6_6.0.21-1+cuda8.0_amd64.deb |
|||
``` |
|||
|
|||
9. SSH back to your VM and execute the following: |
|||
|
|||
```console |
|||
sudo dpkg -i libcudnn6_6.0.21-1+cuda8.0_amd64.deb |
|||
|
|||
export LD_LIBRARY_PATH=/usr/local/cuda/lib64/:/usr/lib/x86_64-linux-gnu/:$LD_LIBRARY_PATH |
|||
. ~/.profile |
|||
|
|||
sudo reboot |
|||
``` |
|||
|
|||
10. After a minute, you should be able to SSH back into your VM. After doing |
|||
so, run the following: |
|||
|
|||
```sh |
|||
sudo apt install python-pip |
|||
sudo apt install python3-pip |
|||
``` |
|||
|
|||
11. At this point, you need to install TensorFlow. The version you install |
|||
should be tied to if you are using GPU to train: |
|||
|
|||
```sh |
|||
pip3 install tensorflow-gpu==1.4.0 keras==2.0.6 |
|||
``` |
|||
|
|||
Or CPU to train: |
|||
|
|||
```sh |
|||
pip3 install tensorflow==1.4.0 keras==2.0.6 |
|||
``` |
|||
|
|||
12. You'll then need to install additional dependencies: |
|||
|
|||
```sh |
|||
pip3 install pillow |
|||
pip3 install numpy |
|||
``` |
|||
|
|||
13. You can now return to the |
|||
[main Azure instruction page](Training-on-Microsoft-Azure.md). |
|||
撰写
预览
正在加载...
取消
保存
Reference in new issue