当前提交
082789ea
共有 49 个文件被更改,包括 299 次插入 和 572 次删除
-
12.pre-commit-config.yaml
-
7.pylintrc
-
2UnitySDK/Assets/ML-Agents/Scripts/Agent.cs
-
6config/gail_config.yaml
-
2docs/Migrating.md
-
9docs/Reward-Signals.md
-
34docs/Training-Imitation-Learning.md
-
35docs/Training-ML-Agents.md
-
18docs/Training-PPO.md
-
18docs/Training-SAC.md
-
142docs/images/mlagents-ImitationAndRL.png
-
6ml-agents-envs/mlagents/envs/base_env.py
-
13ml-agents-envs/mlagents/envs/environment.py
-
3ml-agents-envs/mlagents/envs/mock_communicator.py
-
25ml-agents-envs/mlagents/envs/rpc_utils.py
-
2ml-agents-envs/mlagents/envs/side_channel/engine_configuration_channel.py
-
19ml-agents-envs/mlagents/envs/side_channel/float_properties_channel.py
-
2ml-agents-envs/mlagents/envs/side_channel/raw_bytes_channel.py
-
2ml-agents-envs/mlagents/envs/side_channel/side_channel.py
-
10ml-agents-envs/mlagents/envs/tests/test_rpc_utils.py
-
3ml-agents-envs/mlagents/envs/tests/test_side_channel.py
-
4ml-agents/mlagents/trainers/action_info.py
-
4ml-agents/mlagents/trainers/agent_processor.py
-
16ml-agents/mlagents/trainers/brain.py
-
6ml-agents/mlagents/trainers/components/bc/module.py
-
4ml-agents/mlagents/trainers/demo_loader.py
-
9ml-agents/mlagents/trainers/env_manager.py
-
4ml-agents/mlagents/trainers/models.py
-
8ml-agents/mlagents/trainers/ppo/policy.py
-
2ml-agents/mlagents/trainers/ppo/trainer.py
-
6ml-agents/mlagents/trainers/rl_trainer.py
-
6ml-agents/mlagents/trainers/sac/models.py
-
8ml-agents/mlagents/trainers/sac/policy.py
-
7ml-agents/mlagents/trainers/sac/trainer.py
-
9ml-agents/mlagents/trainers/simple_env_manager.py
-
9ml-agents/mlagents/trainers/subprocess_env_manager.py
-
29ml-agents/mlagents/trainers/tests/test_barracuda_converter.py
-
14ml-agents/mlagents/trainers/tests/test_bcmodule.py
-
2ml-agents/mlagents/trainers/tests/test_policy.py
-
2ml-agents/mlagents/trainers/tests/test_reward_signals.py
-
2ml-agents/mlagents/trainers/tests/test_trainer_controller.py
-
62ml-agents/mlagents/trainers/tests/test_trainer_util.py
-
3ml-agents/mlagents/trainers/tf_policy.py
-
3ml-agents/mlagents/trainers/trainer.py
-
5ml-agents/mlagents/trainers/trainer_controller.py
-
11ml-agents/mlagents/trainers/trainer_util.py
-
30docs/Training-Behavioral-Cloning.md
-
236ml-agents/mlagents/trainers/tests/test_bc.py
{kind=link}
| 之前 | 之后 |
|---|---|
|
|
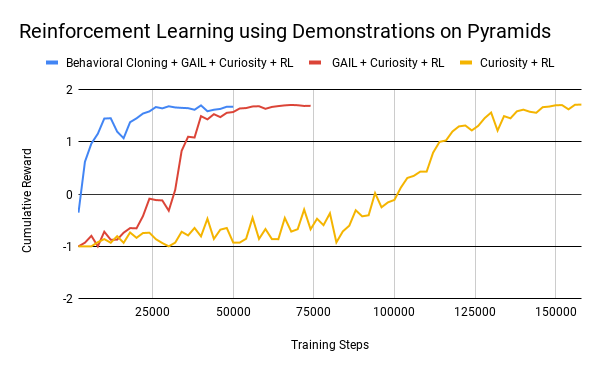
|
| 宽度: 600 | 高度: 371 | 大小: 23 KiB |
|
|||
# Training with Behavioral Cloning |
|||
|
|||
There are a variety of possible imitation learning algorithms which can |
|||
be used, the simplest one of them is Behavioral Cloning. It works by collecting |
|||
demonstrations from a teacher, and then simply uses them to directly learn a |
|||
policy, in the same way the supervised learning for image classification |
|||
or other traditional Machine Learning tasks work. |
|||
|
|||
## Offline Training |
|||
|
|||
With offline behavioral cloning, we can use demonstrations (`.demo` files) |
|||
generated using the `Demonstration Recorder` as the dataset used to train a behavior. |
|||
|
|||
1. Choose an agent you would like to learn to imitate some set of demonstrations. |
|||
2. Record a set of demonstration using the `Demonstration Recorder` (see [here](Training-Imitation-Learning.md)). |
|||
For illustrative purposes we will refer to this file as `AgentRecording.demo`. |
|||
3. Build the scene(make sure the Agent is not using its heuristic). |
|||
4. Open the `config/offline_bc_config.yaml` file. |
|||
5. Modify the `demo_path` parameter in the file to reference the path to the |
|||
demonstration file recorded in step 2. In our case this is: |
|||
`./UnitySDK/Assets/Demonstrations/AgentRecording.demo` |
|||
6. Launch `mlagent-learn`, providing `./config/offline_bc_config.yaml` |
|||
as the config parameter, and include the `--run-id` and `--train` as usual. |
|||
Provide your environment as the `--env` parameter if it has been compiled |
|||
as standalone, or omit to train in the editor. |
|||
7. (Optional) Observe training performance using TensorBoard. |
|||
|
|||
This will use the demonstration file to train a neural network driven agent |
|||
to directly imitate the actions provided in the demonstration. The environment |
|||
will launch and be used for evaluating the agent's performance during training. |
|||
|
|||
import unittest.mock as mock |
|||
import pytest |
|||
import os |
|||
|
|||
import numpy as np |
|||
from mlagents.tf_utils import tf |
|||
import yaml |
|||
|
|||
from mlagents.trainers.bc.models import BehavioralCloningModel |
|||
import mlagents.trainers.tests.mock_brain as mb |
|||
from mlagents.trainers.bc.policy import BCPolicy |
|||
from mlagents.trainers.bc.offline_trainer import BCTrainer |
|||
|
|||
from mlagents.envs.mock_communicator import MockCommunicator |
|||
from mlagents.trainers.tests.mock_brain import make_brain_parameters |
|||
from mlagents.envs.environment import UnityEnvironment |
|||
from mlagents.trainers.brain_conversion_utils import ( |
|||
step_result_to_brain_info, |
|||
group_spec_to_brain_parameters, |
|||
) |
|||
|
|||
|
|||
@pytest.fixture |
|||
def dummy_config(): |
|||
return yaml.safe_load( |
|||
""" |
|||
hidden_units: 32 |
|||
learning_rate: 3.0e-4 |
|||
num_layers: 1 |
|||
use_recurrent: false |
|||
sequence_length: 32 |
|||
memory_size: 32 |
|||
batches_per_epoch: 100 # Force code to use all possible batches |
|||
batch_size: 32 |
|||
summary_freq: 2000 |
|||
max_steps: 4000 |
|||
""" |
|||
) |
|||
|
|||
|
|||
def create_bc_trainer(dummy_config, is_discrete=False, use_recurrent=False): |
|||
mock_env = mock.Mock() |
|||
if is_discrete: |
|||
mock_brain = mb.create_mock_pushblock_brain() |
|||
mock_braininfo = mb.create_mock_braininfo( |
|||
num_agents=12, num_vector_observations=70 |
|||
) |
|||
else: |
|||
mock_brain = mb.create_mock_3dball_brain() |
|||
mock_braininfo = mb.create_mock_braininfo( |
|||
num_agents=12, num_vector_observations=8 |
|||
) |
|||
mb.setup_mock_unityenvironment(mock_env, mock_brain, mock_braininfo) |
|||
env = mock_env() |
|||
|
|||
trainer_parameters = dummy_config |
|||
trainer_parameters["summary_path"] = "tmp" |
|||
trainer_parameters["model_path"] = "tmp" |
|||
trainer_parameters["demo_path"] = ( |
|||
os.path.dirname(os.path.abspath(__file__)) + "/test.demo" |
|||
) |
|||
trainer_parameters["use_recurrent"] = use_recurrent |
|||
trainer = BCTrainer( |
|||
mock_brain, trainer_parameters, training=True, load=False, seed=0, run_id=0 |
|||
) |
|||
trainer.demonstration_buffer = mb.simulate_rollout(env, trainer.policy, 100) |
|||
return trainer, env |
|||
|
|||
|
|||
@pytest.mark.parametrize("use_recurrent", [True, False]) |
|||
def test_bc_trainer_step(dummy_config, use_recurrent): |
|||
trainer, env = create_bc_trainer(dummy_config, use_recurrent=use_recurrent) |
|||
# Test get_step |
|||
assert trainer.get_step == 0 |
|||
# Test update policy |
|||
trainer.update_policy() |
|||
assert len(trainer.stats["Losses/Cloning Loss"]) > 0 |
|||
# Test increment step |
|||
trainer.increment_step(1) |
|||
assert trainer.step == 1 |
|||
|
|||
|
|||
def test_bc_trainer_add_proc_experiences(dummy_config): |
|||
trainer, env = create_bc_trainer(dummy_config) |
|||
# Test add_experiences |
|||
returned_braininfo = env.step() |
|||
brain_name = "Ball3DBrain" |
|||
trainer.add_experiences( |
|||
returned_braininfo[brain_name], returned_braininfo[brain_name], {} |
|||
) # Take action outputs is not used |
|||
for agent_id in returned_braininfo[brain_name].agents: |
|||
assert trainer.evaluation_buffer[agent_id].last_brain_info is not None |
|||
assert trainer.episode_steps[agent_id] > 0 |
|||
assert trainer.cumulative_rewards[agent_id] > 0 |
|||
# Test process_experiences by setting done |
|||
returned_braininfo[brain_name].local_done = 12 * [True] |
|||
trainer.process_experiences( |
|||
returned_braininfo[brain_name], returned_braininfo[brain_name] |
|||
) |
|||
for agent_id in returned_braininfo[brain_name].agents: |
|||
assert trainer.episode_steps[agent_id] == 0 |
|||
assert trainer.cumulative_rewards[agent_id] == 0 |
|||
|
|||
|
|||
def test_bc_trainer_end_episode(dummy_config): |
|||
trainer, env = create_bc_trainer(dummy_config) |
|||
returned_braininfo = env.step() |
|||
brain_name = "Ball3DBrain" |
|||
trainer.add_experiences( |
|||
returned_braininfo[brain_name], returned_braininfo[brain_name], {} |
|||
) # Take action outputs is not used |
|||
trainer.process_experiences( |
|||
returned_braininfo[brain_name], returned_braininfo[brain_name] |
|||
) |
|||
# Should set everything to 0 |
|||
trainer.end_episode() |
|||
for agent_id in returned_braininfo[brain_name].agents: |
|||
assert trainer.episode_steps[agent_id] == 0 |
|||
assert trainer.cumulative_rewards[agent_id] == 0 |
|||
|
|||
|
|||
@mock.patch("mlagents.envs.environment.UnityEnvironment.executable_launcher") |
|||
@mock.patch("mlagents.envs.environment.UnityEnvironment.get_communicator") |
|||
def test_bc_policy_evaluate(mock_communicator, mock_launcher, dummy_config): |
|||
tf.reset_default_graph() |
|||
mock_communicator.return_value = MockCommunicator( |
|||
discrete_action=False, visual_inputs=0 |
|||
) |
|||
env = UnityEnvironment(" ") |
|||
env.reset() |
|||
brain_name = env.get_agent_groups()[0] |
|||
brain_info = step_result_to_brain_info( |
|||
env.get_step_result(brain_name), env.get_agent_group_spec(brain_name) |
|||
) |
|||
brain_params = group_spec_to_brain_parameters( |
|||
brain_name, env.get_agent_group_spec(brain_name) |
|||
) |
|||
|
|||
trainer_parameters = dummy_config |
|||
model_path = brain_name |
|||
trainer_parameters["model_path"] = model_path |
|||
trainer_parameters["keep_checkpoints"] = 3 |
|||
policy = BCPolicy(0, brain_params, trainer_parameters, False) |
|||
run_out = policy.evaluate(brain_info) |
|||
assert run_out["action"].shape == (3, 2) |
|||
|
|||
env.close() |
|||
|
|||
|
|||
def test_cc_bc_model(): |
|||
tf.reset_default_graph() |
|||
with tf.Session() as sess: |
|||
with tf.variable_scope("FakeGraphScope"): |
|||
model = BehavioralCloningModel( |
|||
make_brain_parameters(discrete_action=False, visual_inputs=0) |
|||
) |
|||
init = tf.global_variables_initializer() |
|||
sess.run(init) |
|||
|
|||
run_list = [model.sample_action, model.policy] |
|||
feed_dict = { |
|||
model.batch_size: 2, |
|||
model.sequence_length: 1, |
|||
model.vector_in: np.array([[1, 2, 3, 1, 2, 3], [3, 4, 5, 3, 4, 5]]), |
|||
} |
|||
sess.run(run_list, feed_dict=feed_dict) |
|||
# env.close() |
|||
|
|||
|
|||
def test_dc_bc_model(): |
|||
tf.reset_default_graph() |
|||
with tf.Session() as sess: |
|||
with tf.variable_scope("FakeGraphScope"): |
|||
model = BehavioralCloningModel( |
|||
make_brain_parameters(discrete_action=True, visual_inputs=0) |
|||
) |
|||
init = tf.global_variables_initializer() |
|||
sess.run(init) |
|||
|
|||
run_list = [model.sample_action, model.action_probs] |
|||
feed_dict = { |
|||
model.batch_size: 2, |
|||
model.dropout_rate: 1.0, |
|||
model.sequence_length: 1, |
|||
model.vector_in: np.array([[1, 2, 3, 1, 2, 3], [3, 4, 5, 3, 4, 5]]), |
|||
model.action_masks: np.ones([2, 2], dtype=np.float32), |
|||
} |
|||
sess.run(run_list, feed_dict=feed_dict) |
|||
|
|||
|
|||
def test_visual_dc_bc_model(): |
|||
tf.reset_default_graph() |
|||
with tf.Session() as sess: |
|||
with tf.variable_scope("FakeGraphScope"): |
|||
model = BehavioralCloningModel( |
|||
make_brain_parameters(discrete_action=True, visual_inputs=2) |
|||
) |
|||
init = tf.global_variables_initializer() |
|||
sess.run(init) |
|||
|
|||
run_list = [model.sample_action, model.action_probs] |
|||
feed_dict = { |
|||
model.batch_size: 2, |
|||
model.dropout_rate: 1.0, |
|||
model.sequence_length: 1, |
|||
model.vector_in: np.array([[1, 2, 3, 1, 2, 3], [3, 4, 5, 3, 4, 5]]), |
|||
model.visual_in[0]: np.ones([2, 40, 30, 3], dtype=np.float32), |
|||
model.visual_in[1]: np.ones([2, 40, 30, 3], dtype=np.float32), |
|||
model.action_masks: np.ones([2, 2], dtype=np.float32), |
|||
} |
|||
sess.run(run_list, feed_dict=feed_dict) |
|||
|
|||
|
|||
def test_visual_cc_bc_model(): |
|||
tf.reset_default_graph() |
|||
with tf.Session() as sess: |
|||
with tf.variable_scope("FakeGraphScope"): |
|||
model = BehavioralCloningModel( |
|||
make_brain_parameters(discrete_action=False, visual_inputs=2) |
|||
) |
|||
init = tf.global_variables_initializer() |
|||
sess.run(init) |
|||
|
|||
run_list = [model.sample_action, model.policy] |
|||
feed_dict = { |
|||
model.batch_size: 2, |
|||
model.sequence_length: 1, |
|||
model.vector_in: np.array([[1, 2, 3, 1, 2, 3], [3, 4, 5, 3, 4, 5]]), |
|||
model.visual_in[0]: np.ones([2, 40, 30, 3], dtype=np.float32), |
|||
model.visual_in[1]: np.ones([2, 40, 30, 3], dtype=np.float32), |
|||
} |
|||
sess.run(run_list, feed_dict=feed_dict) |
|||
|
|||
|
|||
if __name__ == "__main__": |
|||
pytest.main() |
|||
撰写
预览
正在加载...
取消
保存
Reference in new issue