* [Semantics] Modified the semantics for the documentation
* [Semantics] Updated the images
* [Semantics] Made further changes to the docs based of the comments received
When you launch your Unity Environment from python, you can see what the agents connected to non-external brains are doing. When calling `step` or `reset` on your environment, you retrieve a dictionary from brain names to `BrainInfo` objects. Each `BrainInfo` the non-external brains set to broadcast.
Just like with an external brain, the `BrainInfo` object contains the fields for `observations`, `states`, `memories`,`rewards`, `local_done`, `agents` and `previous_actions`. Note that `previous_actions` corresponds to the actions that were taken by the agents at the previous step, not the current one.
Just like with an external brain, the `BrainInfo` object contains the fields for `visual_observations`, `vector_observations`, `text_observations`, `memories`,`rewards`, `local_done`, `max_reached`, `agents` and `previous_actions`. Note that `previous_actions` corresponds to the actions that were taken by the agents at the previous step, not the current one.
Note that when you do a `step` on the environment, you cannot provide actions for non-external brains. If there are no external brains in the scene, simply call `step()` with no arguments.
You can use the broadcast feature to collect data generated by Player, Heuristics or Internal brains game sessions. You can then use this data to train an agent in a supervised context.
* If you want the agent to finish a task quickly, it is often helpful to provide a small penalty every step (-0.05) that the agent does not complete the task. In this case completion of the task should also coincide with the end of the episode.
* Overly-large negative rewards can cause undesirable behavior where an agent learns to avoid any behavior which might produce the negative reward, even if it is also behavior which can eventually lead to a positive reward.
## States
* States should include all variables relevant to allowing the agent to take the optimally informed decision.
* Categorical state variables such as type of object (Sword, Shield, Bow) should be encoded in one-hot fashion (ie `3` -> `0, 0, 1`).
* Besides encoding non-numeric values, all inputs should be normalized to be in the range 0 to +1 (or -1 to 1). For example rotation information on GameObjects should be recorded as `state.Add(transform.rotation.eulerAngles.y/180.0f-1.0f);` rather than `state.Add(transform.rotation.y);`. See the equation below for one approach of normaliztaion.
## Vector Observations
* Vector observations should include all variables relevant to allowing the agent to take the optimally informed decision.
* Categorical variables such as type of object (Sword, Shield, Bow) should be encoded in one-hot fashion (ie `3` -> `0, 0, 1`).
* Besides encoding non-numeric values, all inputs should be normalized to be in the range 0 to +1 (or -1 to 1). For example rotation information on GameObjects should be recorded as `AddVectorObs(transform.rotation.eulerAngles.y/180.0f-1.0f);` rather than `AddVectorObs(transform.rotation.y);`. See the equation below for one approach of normalization.
## Actions
## Vector Actions
* Be sure to set the action-space-size to the number of used actions, and not greater, as doing the latter can interfere with the efficency of the training process.
* Be sure to set the action-space-size to the number of used vector actions, and not greater, as doing the latter can interfere with the efficency of the training process.
All the values are divided by 5 to normalize the inputs to the neural network to the range [-1,1]. (The number five is used because the platform is 10 units across.)
The final part of the Agent code is the Agent.AgentStep() function, which receives the decision from the Brain.
The final part of the Agent code is the Agent.AgentAct() function, which receives the decision from the Brain.
The decision of the Brain comes in the form of an action array passed to the `AgentStep()` function. The number of elements in this array is determined by the `Action Space Type` and `ActionSize` settings of the agent's Brain. The RollerAgent uses the continuous action space and needs two continuous control signals from the brain. Thus, we will set the Brain `Action Size` to 2. The first element,`action[0]` determines the force applied along the x axis; `action[1]` determines the force applied along the z axis. (If we allowed the agent to move in three dimensions, then we would need to set `Action Size` to 3. Note the Brain really has no idea what the values in the action array mean. The training process adjust the action values in response to the observation input and then sees what kind of rewards it gets as a result.
The decision of the Brain comes in the form of an action array passed to the `AgentAct()` function. The number of elements in this array is determined by the `Vector Action Space Type` and `Vector Action Space Size` settings of the agent's Brain. The RollerAgent uses the continuous vector action space and needs two continuous control signals from the brain. Thus, we will set the Brain `Vector Action Size` to 2. The first element,`action[0]` determines the force applied along the x axis; `action[1]` determines the force applied along the z axis. (If we allowed the agent to move in three dimensions, then we would need to set `Vector Action Size` to 3. Note the Brain really has no idea what the values in the action array mean. The training process adjust the action values in response to the observation input and then sees what kind of rewards it gets as a result.
Before we can add a force to the agent, we need a reference to its Rigidbody component. A [Rigidbody](https://docs.unity3d.com/ScriptReference/Rigidbody.html) is Unity's primary element for physics simulation. (See [Physics](https://docs.unity3d.com/Manual/PhysicsSection.html) for full documentation of Unity physics.) A good place to set references to other components of the same GameObject is in the standard Unity `Start()` method:
**Rewards**
Rewards are also assigned in the AgentStep() function. The learning algorithm uses the rewards assigned to the Agent.reward property at each step in the simulation and learning process to determine whether it is giving the agent to optimal actions. You want to reward an agent for completing the assigned task (reaching the Target cube, in this case) and punish the agent if it irrevocably fails (falls off the platform). You can sometimes speed up training with sub-rewards that encourage behavior that helps the agent complete the task. For example, the RollerAgent reward system provides a small reward if the agent moves closer to the target in a step.
Rewards are also assigned in the AgentAct() function. The learning algorithm uses the rewards assigned to the agent property at each step in the simulation and learning process to determine whether it is giving the agent to optimal actions. You want to reward an agent for completing the assigned task (reaching the Target cube, in this case) and punish the agent if it irrevocably fails (falls off the platform). You can sometimes speed up training with sub-rewards that encourage behavior that helps the agent complete the task. For example, the RollerAgent reward system provides a small reward if the agent moves closer to the target in a step.
The RollerAgent calculates the distance to detect when it reaches the target. When it does, the code increments the Agent.reward variable by 1.0 and marks the agent as finished by setting the Agent.done variable to `true`.
The RollerAgent calculates the distance to detect when it reaches the target. When it does, the code increments the Agent.reward variable by 1.0 and marks the agent as finished by setting the agent to done.
**Note:** When you mark an agent as done, it stops its activity until it is reset. You can have the agent reset immediately, by setting the Agent.ResetOnDone property in the inspector or you can wait for the Academy to reset the environment. This RollerBall environment relies on the `ResetOnDone` mechanism and doesn't set a `Max Steps` limit for the Academy (so it never resets the environment).
// Getting closer
if (distanceToTarget <previousDistance)
{
reward += 0.1f;
AddReward(0.1f);
reward += -0.05f;
AddReward(-0.05f);
Finally, to punish the agent for falling off the platform, assign a large negative reward and, of course, set the agent to done so that it resets itself in the next step:
this.done = true;
reward += -1.0f;
Done();
AddReward(-1.0f);
**AgentStep()**
**AgentAct()**
With the action and reward logic outlined above, the final version of the `AgentStep()` function looks like:
With the action and reward logic outlined above, the final version of the `AgentAct()` function looks like:
Finally, select the Brain GameObject so that you can see its properties in the Inspector window. Set the following properties:
* `State Size` = 8
* `Action Size` = 2
* `Action Space Type` = **Continuous**
* `State Space Type` = **Continuous**
* `Vector Observation Space Size` = 8
* `Vector Action Space Size` = 2
* `Vector Action Space Type` = **Continuous**
* `Vector Observation Space Type` = **Continuous**
* `Brain Type` = **Player**
Now you are ready to test the environment before training.
| Element 2 | W | 1 | 1 |
| Element 3 | S | 1 | -1 |
The **Index** value corresponds to the index of the action array passed to `AgentStep()` function. **Value** is assigned to action[Index] when **Key** is pressed.
The **Index** value corresponds to the index of the action array passed to `AgentAct()` function. **Value** is assigned to action[Index] when **Key** is pressed.
Press **Play** to run the scene and use the WASD keys to move the agent around the platform. Make sure that there are no errors displayed in the Unity editor Console window and that the agent resets when it reaches its target or falls from the platform. Note that for more involved debugging, the ML-Agents SDK includes a convenient Monitor class that you can use to easily display agent status information in the Game window.
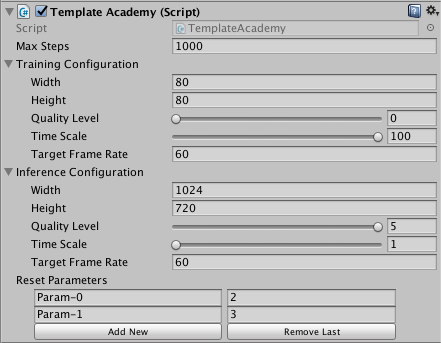
* `Max Steps` - Total number of steps per-episode. `0` corresponds to episodes without a maximum number of steps. Once the step counter reaches maximum, the environment will reset.
* `Frames To Skip` - How many steps of the environment to skip before asking Brains for decisions.
* `Wait Time` - How many seconds to wait between steps when running in `Inference`.
* `Configuration` - The engine-level settings which correspond to rendering quality and engine speed.
* `Width` - Width of the environment window in pixels.
* `Height` - Width of the environment window in pixels.
* `Default Reset Parameters` - List of custom parameters that can be changed in the environment on reset.
* `Reset Parameters` - List of custom parameters that can be changed in the environment on reset.
The Brain class abstracts out the decision making logic from the agent itself so that you can use the same brain in multiple agents.
How a brain makes its decisions depends on the type of brain it is. An **External** brain simply passes the observations from its agents to an external process and then passes the decisions made externally back to the agents. During training, the ML-Agents [reinforcement learning](Learning-Environment-Design.md) algorithm adjusts its internal policy parameters to make decisions that optimize the rewards received over time. An Internal brain uses the trained policy parameters to make decisions (and no longer adjusts the parameters in search of a better decision). The other types of brains do not directly involve training, but you might find them useful as part of a training project. See [Brains](Learning-Environment-Design-Brains.md).
## Observations and State
## Observations
To make decisions, an agent must observe its environment to determine its current state. A state observation can take the following forms:
When you use the **Continuous** or **Discrete**state space for an agent, implement the `Agent.CollectState()` method to create the feature vector or state index. When you use camera observations, you only need to identify which Unity Camera objects will provide images and the base Agent class handles the rest. You do not need to implement the `CollectState()` method.
When you use the **Continuous** or **Discrete**vector observation space for an agent, implement the `Agent.CollectObservations()` method to create the feature vector or state index. When you use camera observations, you only need to identify which Unity Camera objects will provide images and the base Agent class handles the rest. You do not need to implement the `CollectObservations()` method.
For agents using a continuous state space, you create a feature vector to represent the agent's observation at each step of the simulation. The Brain class calls the `CollectState()` method of each of its agents. Your implementation of this function returns the feature vector observation as a `List<float>` object.
For agents using a continuous state space, you create a feature vector to represent the agent's observation at each step of the simulation. The Brain class calls the `CollectObservations()` method of each of its agents. Your implementation of this function must call `AddVectorObs` to add vector observations.
The observation must include all the information an agent needs to accomplish its task. Without sufficient and relevant information, an agent may learn poorly or may not learn at all. A reasonable approach for determining what information should be included is to consider what you would need to calculate an analytical solution to the problem.
<!-- Note that the above values aren't normalized, which we recommend! -->
When you set up an Agent's brain in the Unity Editor, set the following properties to use a continuous state-space feature vector:
When you set up an Agent's brain in the Unity Editor, set the following properties to use a continuous vector observation:
**State Size** — The state size must match the length of your feature vector.
**State Space Type** — Set to **Continuous**.
**Space Size** — The state size must match the length of your feature vector.
**Space Type** — Set to **Continuous**.
Integers can be be added directly to the state vector, relying on implicit conversion in the `List.Add()` function. You must explicitly convert Boolean values to a number:
Integers can be be added directly to the observation vector. You must explicitly convert Boolean values to a number:
state.Add(isTrueOrFalse ? 1 : 0);
AddVectorObs(isTrueOrFalse ? 1 : 0);
state.Add(speed.x);
state.Add(speed.y);
state.Add(speed.z);
AddVectorObs(speed.x);
AddVectorObs(speed.y);
AddVectorObs(speed.z);
public override List<float> CollectState()
public override void CollectObservations()
state.Clear();
state.Add((int)currentItem == ci ? 1.0f : 0.0f);
AddVectorObs((int)currentItem == ci ? 1.0f : 0.0f);
return state;
}
For angles that can be outside the range [0,360], you can either reduce the angle, or, if the number of turns is significant, increase the maximum value used in your normalization formula.
### Camera Observations
### Visual Observations
Agents using camera images can capture state of arbitrary complexity and are useful when the state is difficult to describe numerically. However, they are also typically less efficient and slower to train, and sometimes don't succeed at all.
Agents using camera images can capture state of arbitrary complexity and are useful when the state is difficult to describe numerically. However, they are also typically less efficient and slower to train, and sometimes don't succeed at all.
You can use the discrete state space when an agent only has a limited number of possible states and those states can be enumerated by a single number. For instance, the [Basic example environment](Learning-Environment-Examples.md) in the ML Agent SDK defines an agent with a discrete state space. The states of this agent are the integer steps between two linear goals. In the Basic example, the agent learns to move to the goal that provides the greatest reward.
You can use the discrete vector observation space when an agent only has a limited number of possible states and those states can be enumerated by a single number. For instance, the [Basic example environment](Learning-Environment-Examples.md) in the ML Agent SDK defines an agent with a discrete vector observation space. The states of this agent are the integer steps between two linear goals. In the Basic example, the agent learns to move to the goal that provides the greatest reward.
More generally, the discrete state identifier could be an index into a table of the possible states. However, tables quickly become unwieldy as the environment becomes more complex. For example, even a simple game like [tic-tac-toe has 765 possible states](https://en.wikipedia.org/wiki/Game_complexity) (far more if you don't reduce the number of states by combining those that are rotations or reflections of each other).
More generally, the discrete vector observation identifier could be an index into a table of the possible states. However, tables quickly become unwieldy as the environment becomes more complex. For example, even a simple game like [tic-tac-toe has 765 possible states](https://en.wikipedia.org/wiki/Game_complexity) (far more if you don't reduce the number of observations by combining those that are rotations or reflections of each other).
To implement a discrete state observation, implement the `CollectState()` method of your Agent subclass and return a `List` containing a single number representing the state:
To implement a discrete state observation, implement the `CollectObservations()` method of your Agent subclass and return a `List` containing a single number representing the state:
private List<float> state = new List<float>();
public override List<float> CollectState()
public override void CollectObservations()
state[0] = stateIndex; // stateIndex is the state identifier
return state;
AddVectorObs(stateIndex); // stateIndex is the state identifier
## Actions
## Vector Actions
An action is an instruction from the brain that the agent carries out. The action is passed to the agent as a parameter when the Academy invokes the agent's `AgentStep()` function. When you specify that the action space is **Continuous**, the action parameter passed to the agent is an array of control signals with length equal to the `Action Size` property. When you specify a **Discrete** action space, the action parameter is an array containing only a single value, which is an index into your list or table of commands. In the **Discrete** action space, the `Action Size` is the number of elements in your action table. Set the `Action Space` and `Action Size` properties on the Brain object assigned to the agent (using the Unity Editor Inspector window).
An action is an instruction from the brain that the agent carries out. The action is passed to the agent as a parameter when the Academy invokes the agent's `AgentAct()` function. When you specify that the vector action space is **Continuous**, the action parameter passed to the agent is an array of control signals with length equal to the `Vector Action Space Size` property. When you specify a **Discrete** vector action space type, the action parameter is an array containing only a single value, which is an index into your list or table of commands. In the **Discrete** vector action space type, the `Vector Action Space Size` is the number of elements in your action table. Set the `Vector Action Space Size` and `Vector Action Space Type` properties on the Brain object assigned to the agent (using the Unity Editor Inspector window).
Neither the Brain nor the training algorithm know anything about what the action values themselves mean. The training algorithm simply tries different values for the action list and observes the affect on the accumulated rewards over time and many training episodes. Thus, the only place actions are defined for an agent is in the `AgentStep()` function. You simply specify the type of action space, and, for the continuous action space, the number of values, and then apply the received values appropriately (and consistently) in `ActionStep()`.
Neither the Brain nor the training algorithm know anything about what the action values themselves mean. The training algorithm simply tries different values for the action list and observes the affect on the accumulated rewards over time and many training episodes. Thus, the only place actions are defined for an agent is in the `AgentAct()` function. You simply specify the type of vector action space, and, for the continuous vector action space, the number of values, and then apply the received values appropriately (and consistently) in `ActionAct()`.
For example, if you designed an agent to move in two dimensions, you could use either continuous or the discrete actions. In the continuous case, you would set the action size to two (one for each dimension), and the agent's brain would create an action with two floating point values. In the discrete case, you would set the action size to four (one for each direction), and the brain would create an action array containing a single element with a value ranging from zero to four.
For example, if you designed an agent to move in two dimensions, you could use either continuous or the discrete vector actions. In the continuous case, you would set the vector action size to two (one for each dimension), and the agent's brain would create an action with two floating point values. In the discrete case, you would set the vector action size to four (one for each direction), and the brain would create an action array containing a single element with a value ranging from zero to four.
The [3DBall and Area example projects](Learning-Environment-Examples.md) are set up to use either the continuous or the discrete action spaces.
The [3DBall and Area example projects](Learning-Environment-Examples.md) are set up to use either the continuous or the discrete vector action spaces.
When an agent uses a brain set to the **Continuous** action space, the action parameter passed to the agent's `AgentStep()` function is an array with length equal to the Brain object's `Action Size` property value. The individual values in the array have whatever meanings that you ascribe to them. If you assign an element in the array as the speed of an agent, for example, the training process learns to control the speed of the agent though this parameter.
When an agent uses a brain set to the **Continuous** vector action space, the action parameter passed to the agent's `AgentAct()` function is an array with length equal to the Brain object's `Vector Action Space Size` property value. The individual values in the array have whatever meanings that you ascribe to them. If you assign an element in the array as the speed of an agent, for example, the training process learns to control the speed of the agent though this parameter.
The [Reacher example](Learning-Environment-Examples.md) defines a continuous action space with four control values.
When an agent uses a brain set to the **Discrete** action space, the action parameter passed to the agent's `AgentStep()` function is an array containing a single element. The value is the index of the action to in your table or list of actions. With the discrete action space, `Action Size` represents the number of actions in your action table.
When an agent uses a brain set to the **Discrete**vector action space, the action parameter passed to the agent's `AgentAct()` function is an array containing a single element. The value is the index of the action to in your table or list of actions. With the discrete vector action space, `Vector Action Space Size` represents the number of actions in your action table.
The [Area example](Learning-Environment-Examples.md) defines five actions for the discrete action space: a jump action and one action for each cardinal direction:
The [Area example](Learning-Environment-Examples.md) defines five actions for the discrete vector action space: a jump action and one action for each cardinal direction:
// Get the action index
int movement = Mathf.FloorToInt(act[0]);
Perhaps the best advice is to start simple and only add complexity as needed. In general, you should reward results rather than actions you think will lead to the desired results. To help develop your rewards, you can use the Monitor class to display the cumulative reward received by an agent. You can even use a Player brain to control the agent while watching how it accumulates rewards.
Allocate rewards to an agent by setting the agent's `reward` property in the `AgentStep()` function. The reward assigned in any step should be in the range [-1,1]. Values outside this range can lead to unstable training. The `reward` value is reset to zero at every step.
Allocate rewards to an agent by calling the `AddReward()` method in the `AgentAct()` function. The reward assigned in any step should be in the range [-1,1]. Values outside this range can lead to unstable training. The `reward` value is reset to zero at every step.
You can examine the `AgentStep()` functions defined in the [Examples](Learning-Environment-Examples.md) to see how those projects allocate rewards.
You can examine the `AgentAct()` functions defined in the [Examples](Learning-Environment-Examples.md) to see how those projects allocate rewards.
The `GridAgent` class in the [GridWorld example](Learning-Environment-Examples.md) uses a very simple reward system:
{
reward = 1f;
done = true;
AddReward(1.0f);
Done();
reward = -1f;
done = true;
AddReward(-1f);
Done();
}
The agent receives a positive reward when it reaches the goal and a negative reward when it falls into the pit. Otherwise, it gets no rewards. This is an example of a _sparse_ reward system. The agent must explore a lot to find the infrequent reward.
reward = -0.005f;
AddReward( -0.005f);
MoveAgent(act);
if (gameObject.transform.position.y <0.0f||
done = true;
reward = -1f;
Done();
AddReward(-1f);
}
The agent also gets a larger negative penalty if it falls off the playing surface.
if (done == false)
if (IsDone() == false)
reward = 0.1f;
SetReward(0.1f);
}
//When ball falls mark agent as done and give a negative penalty
{
done = true;
reward = -1f;
Done();
SetReward(-1f);
}
The `Ball3DAgent` also assigns a negative penalty when the ball falls off the platform.

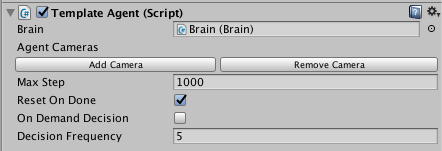
* `Brain` - The brain to register this agent to. Can be dragged into the inspector using the Editor.
* `Observations` - A list of `Cameras` which will be used to generate observations.
* `Visual Observations` - A list of `Cameras` which will be used to generate observations.
* `On Demand Decision` - Whether the agent will request decision at a fixed frequency or if he will be manually have to request decisions with `RequestDecision()`
* Decision Frequency` - If the agent is not `On Demand Decision`, this is the number of steps between decision requests.
Use the Brain class directly, rather than a subclass. Brain behavior is determined by the brain type. During training, set your agent's brain type to **External**. To use the trained model, import the model file into the Unity project and change the brain type to **Internal**. You can extend the CoreBrain class to create different brain types if the four built-in types don't do what you need.
The Brain class has several important properties that you can set using the Inspector window. These properties must be appropriate for the agents using the brain. For example, the `State Size` property must match the length of the feature vector created by an agent exactly. See [Agents](Learning-Environment-Design-Agents.md) for information about creating agents and setting up a Brain instance correctly.
The Brain class has several important properties that you can set using the Inspector window. These properties must be appropriate for the agents using the brain. For example, the `Vector Observation Space Size` property must match the length of the feature vector created by an agent exactly. See [Agents](Learning-Environment-Design-Agents.md) for information about creating agents and setting up a Brain instance correctly.
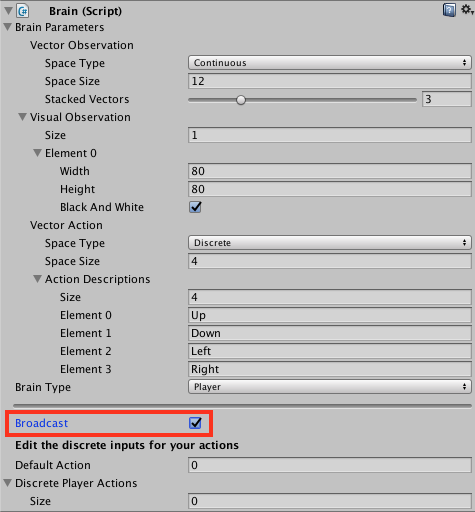
* `Brain Parameters` - Define state, observation, and action spaces for the Brain.
* `State Size` - Length of state vector for brain (In _Continuous_ state space). Or number of possible
values (in _Discrete_ state space).
* `Action Size` - Length of action vector for brain (In _Continuous_ state space). Or number of possible
* `Brain Parameters` - Define vector observations, visual observation, and vector actions for the Brain.
* `Vector Observation`
* `Space Type` - Corresponds to whether the observation vector contains a single integer (Discrete) or a series of real-valued floats (Continuous).
* `Space Size` - Length of vector observation for brain (In _Continuous_ space type). Or number of possible
values (in _Discrete_ space type).
* `Stacked Vectors` - The number of previous vector observations that will be stacked before being sent to the brain.
* `Visual Observations` - Describes height, width, and whether to greyscale visual observations for the Brain.
* `Vector Action`
* `Space Type` - Corresponds to whether action vector contains a single integer (Discrete) or a series of real-valued floats (Continuous).
* `Space Size` - Length of action vector for brain (In _Continuous_ state space). Or number of possible
* `Memory Size` - Length of memory vector for brain. Used with Recurrent networks and frame-stacking CNNs.
* `Camera Resolution` - Describes height, width, and whether to greyscale visual observations for the Brain.
* `Action Descriptions` - A list of strings used to name the available actions for the Brain.
* `State Space Type` - Corresponds to whether state vector contains a single integer (Discrete) or a series of real-valued floats (Continuous).
* `Action Space Type` - Corresponds to whether action vector contains a single integer (Discrete) or a series of real-valued floats (Continuous).
* `Action Descriptions` - A list of strings used to name the available actions for the Brain.
* `Type of Brain` - Describes how the Brain will decide actions.
* `External` - Actions are decided using Python API.
* `Internal` - Actions are decided using internal TensorFlowSharp model.
* `State Node Name` : If your graph uses the state as an input, you must specify the name if the placeholder here.
* `Recurrent Input Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the input placeholder here.
* `Recurrent Output Node Name` : If your graph uses a recurrent input / memory as input and outputs new recurrent input / memory, you must specify the name if the output placeholder here.
* `Observation Placeholder Name` : If your graph uses observations as input, you must specify it here. Note that the number of observations is equal to the length of `Camera Resolutions` in the brain parameters.
* `Visual Observation Placeholder Name` : If your graph uses observations as input, you must specify it here. Note that the number of observations is equal to the length of `Camera Resolutions` in the brain parameters.
* `Action Node Name` : Specify the name of the placeholder corresponding to the actions of the brain in your graph. If the action space type is continuous, the output must be a one dimensional tensor of float of length `Action Space Size`, if the action space type is discrete, the output must be a one dimensional tensor of int of length 1.
* `Graph Placeholder` : If your graph takes additional inputs that are fixed (example: noise level) you can specify them here. Note that in your graph, these must correspond to one dimensional tensors of int or float of size 1.
* `Name` : Corresponds to the name of the placeholdder.
1. Calls your Academy subclass's `AcademyReset()` function.
2. Calls the `AgentReset()` function for each agent in the scene.
3. Calls the `CollectState()` function for each agent in the scene.
3. Calls the `CollectObservations()` function for each agent in the scene.
5. Calls your subclass's `AcademyStep()` function.
6. Calls the `AgentStep()` function for each agent in the scene, passing in the action chosen by the agent's brain. (This function is not called if the agent is done.)
5. Calls your subclass's `AcademyAct()` function.
6. Calls the `AgentAct()` function for each agent in the scene, passing in the action chosen by the agent's brain. (This function is not called if the agent is done.)
To create a training environment, extend the Academy and Agent classes to implement the above methods. The `Agent.CollectState()` and `Agent.AgentStep()` functions are required; the other methods are optional — whether you need to implement them or not depends on your specific scenario.
To create a training environment, extend the Academy and Agent classes to implement the above methods. The `Agent.CollectObservations()` and `Agent.AgentAct()` functions are required; the other methods are optional — whether you need to implement them or not depends on your specific scenario.
**Note:** The API used by the Python PPO training process to communicate with and control the Academy during training can be used for other purposes as well. For example, you could use the API to use Unity as the simulation engine for your own machine learning algorithms. See [External ML API](Python-API.md) for more information.
* `InitializeAcademy()` — Prepare the environment the first time it launches.
* `AcademyReset()` — Prepare the environment and agents for the next training episode. Use this function to place and initialize entities in the scene as necessary.
* `AcademyStep()` — Prepare the environment for the next simulation step. The base Academy class calls this function before calling any `AgentStep()` methods for the current step. You can use this function to update other objects in the scene before the agents take their actions. Note that the agents have already collected their observations and chosen an action before the Academy invokes this method.
* `AcademyStep()` — Prepare the environment for the next simulation step. The base Academy class calls this function before calling any `AgentAct()` methods for the current step. You can use this function to update other objects in the scene before the agents take their actions. Note that the agents have already collected their observations and chosen an action before the Academy invokes this method.
The base Academy classes also defines several important properties that you can set in the Unity Editor Inspector. For training, the most important of these properties is `Max Steps`, which determines how long each training episode lasts. Once the Academy's step counter reaches this value, it calls the `AcademyReset()` function to start the next episode.
The base Academy classes also defines several important properties that you can set in the Unity Editor Inspector. For training, the most important of these properties is `Max Steps`, which determines how long each training episode lasts. Once the Academy's step counter reaches this value, it calls the `AcademyReset()` function to start the next episode.
See [Academy](Learning-Environment-Design-Academy.md) for a complete list of the Academy properties and their uses.
Use the Brain class directly, rather than a subclass. Brain behavior is determined by the brain type. During training, set your agent's brain type to **External**. To use the trained model, import the model file into the Unity project and change the brain type to **Internal**. See [Brain topic](Learning-Environment-Design-Brains.md) for details on using the different types of brains. You can extend the CoreBrain class to create different brain types if the four built-in types don't do what you need.
The Brain class has several important properties that you can set using the Inspector window. These properties must be appropriate for the agents using the brain. For example, the `State Size` property must match the length of the feature vector created by an agent exactly. See [Agent topic]() for information about creating agents and setting up a Brain instance correctly.
The Brain class has several important properties that you can set using the Inspector window. These properties must be appropriate for the agents using the brain. For example, the `Vector Observation Space Size` property must match the length of the feature vector created by an agent exactly. See [Agent topic]() for information about creating agents and setting up a Brain instance correctly.
See [Brains](Learning-Environment-Design-Brains.md) for a complete list of the Brain properties.
To create an agent, extend the Agent class and implement the essential `CollectState()` and `AgentStep()` methods:
To create an agent, extend the Agent class and implement the essential `CollectObservations()` and `AgentAct()` methods:
* `CollectState()` — Collects the agent's observation of its environment.
* `AgentStep()` — Carries out the action chosen by the agent's brain and assigns a reward to the current state.
* `CollectObservations()` — Collects the agent's observation of its environment.
* `AgentAct()` — Carries out the action chosen by the agent's brain and assigns a reward to the current state.
You must also determine how an Agent finishes its task or times out. You can manually set an agent to done in your `AgentStep()` function when the agent has finished (or irrevocably failed) its task. You can also set the agent's `Max Steps` property to a positive value and the agent will consider itself done after it has taken that many steps. When the Academy reaches its own `Max Steps` count, it starts the next episode. If you set an agent's RestOnDone property to true, then the agent can attempt its task several times in one episode. (Use the `Agent.AgentReset()` function to prepare the agent to start again.)
You must also determine how an Agent finishes its task or times out. You can manually set an agent to done in your `AgentAct()` function when the agent has finished (or irrevocably failed) its task. You can also set the agent's `Max Steps` property to a positive value and the agent will consider itself done after it has taken that many steps. When the Academy reaches its own `Max Steps` count, it starts the next episode. If you set an agent's `ResetOnDone` property to true, then the agent can attempt its task several times in one episode. (Use the `Agent.AgentReset()` function to prepare the agent to start again.)
See [Agents](Learning-Environment-Design-Agents.md) for detailed information about programing your own agents.
* Brains: One brain with the following observation/action space.
* State space: (Discrete) One variable corresponding to current state.
* Action space: (Discrete) Two possible actions (Move left, move right).
* Vector Observation space: (Discrete) One variable corresponding to current state.
* Vector Action space: (Discrete) Two possible actions (Move left, move right).
* Visual Observations: 0
* Reset Parameters: None
* Brains: One brain with the following observation/action space.
* Vector Observation space: (Continuous) 8 variables corresponding to rotation of platform, and position, rotation, and velocity of ball.
* Vector Observation space (Hard Version): (Continuous) 5 variables corresponding to rotation of platform and position and rotation of ball.
* Action space: (Continuous) Size of 2, with one value corresponding to X-rotation, and the other to Z-rotation.
* Vector Action space: (Continuous) Size of 2, with one value corresponding to X-rotation, and the other to Z-rotation.
* Visual Observations: 0
* Reset Parameters: None
* -1.0 if the agent navigates to an obstacle (episode ends).
* Brains: One brain with the following observation/action space.
* Vector Observation space: None
* Action space: (Discrete) Size of 4, corresponding to movement in cardinal directions.
* Vector Action space: (Discrete) Size of 4, corresponding to movement in cardinal directions.
* Visual Observations: One corresponding to top-down view of GridWorld.
* Reset Parameters: Three, corresponding to grid size, number of obstacles, and number of goals.
* -0.1 To agent who let ball hit their ground, or hit ball out of bounds.
* Brains: One brain with the following observation/action space.
* Vector Observation space: (Continuous) 8 variables corresponding to position and velocity of ball and racket.
* Action space: (Continuous) Size of 2, corresponding to movement toward net or away from net, and jumping.
* Vector Action space: (Continuous) Size of 2, corresponding to movement toward net or away from net, and jumping.
* Visual Observations: None
* Reset Parameters: One, corresponding to size of ball.
* -1.0 if the agent falls off the platform.
* Brains: One brain with the following observation/action space.
* Vector Observation space: (Continuous) 15 variables corresponding to position and velocities of agent, block, and goal.
* Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement.
* Vector Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement.
* Visual Observations: None.
* Reset Parameters: One, corresponding to number of steps in training. Used to adjust size of elements for Curriculum Learning.
* -1.0 if the agent falls off the platform.
* Brains: One brain with the following observation/action space.
* Vector Observation space: (Continuous) 16 variables corresponding to position and velocities of agent, block, and goal, plus the height of the wall.
* Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement.
* Vector Action space: (Discrete) Size of 6, corresponding to movement in cardinal directions, jumping, and no movement.
* Visual Observations: None.
* Reset Parameters: One, corresponding to number of steps in training. Used to adjust size of the wall for Curriculum Learning.
* +0.1 Each step agent's hand is in goal location.
* Brains: One brain with the following observation/action space.
* Vector Observation space: (Continuous) 26 variables corresponding to position, rotation, velocity, and angular velocities of the two arm rigidbodies.
* Action space: (Continuous) Size of 4, corresponding to torque applicable to two joints.
* Vector Action space: (Continuous) Size of 4, corresponding to torque applicable to two joints.
* Visual Observations: None
* Reset Parameters: Two, corresponding to goal size, and goal movement speed.
* -0.05 times velocity in the z direction
* Brains: One brain with the following observation/action space.
* Vector Observation space: (Continuous) 117 variables corresponding to position, rotation, velocity, and angular velocities of each limb plus the acceleration and angular acceleration of the body.
* Action space: (Continuous) Size of 12, corresponding to torque applicable to 12 joints.
* Vector Action space: (Continuous) Size of 12, corresponding to torque applicable to 12 joints.
* Visual Observations: None
* Reset Parameters: None
* -1 for interaction with red banana.
* Brains: One brain with the following observation/action space.
* Vector Observation space: (Continuous) 51 corresponding to velocity of agent, plus ray-based perception of objects around agent's forward direction.
* Action space: (Continuous) Size of 3, corresponding to forward movement, y-axis rotation, and whether to use laser to disable other agents.
* Vector Action space: (Continuous) Size of 3, corresponding to forward movement, y-axis rotation, and whether to use laser to disable other agents.
* Visual Observations (Optional): First-person view for each agent.
* Reset Parameters: None
* -0.0003 Existential penalty.
* Brains: One brain with the following observation/action space:
* Vector Observation space: (Continuous) 30 corresponding to local ray-casts detecting objects, goals, and walls.
* Action space: (Discrete) 4 corresponding to agent rotation and forward/backward movement.
* Vector Action space: (Discrete) 4 corresponding to agent rotation and forward/backward movement.
* Visual Observations (Optional): First-person view for the agent.
* **`observations`** : A list of 4 dimensional numpy arrays. Matrix n of the list corresponds to the n<sup>th</sup> observation of the brain.
* **`states`** : A two dimensional numpy array of dimension `(batch size, state size)` if the state space is continuous and `(batch size, 1)` if the state space is discrete.
* **`visual_observations`** : A list of 4 dimensional numpy arrays. Matrix n of the list corresponds to the n<sup>th</sup> observation of the brain.
* **`vector_observations`** : A two dimensional numpy array of dimension `(batch size, vector observation size)` if the vector observation space is continuous and `(batch size, 1)` if the vector observation space is discrete.
* **`text_observations`** : A list of string corresponding to the agents text observations.
* **`max_reached`** : A list as long as the number of agents using the brain containing true if the agents reached their max steps.
* **`previous_actions`** : A two dimensional numpy array of dimension `(batch size, vector action size)` if the vector action space is continuous and `(batch size, 1)` if the vector action space is discrete.
Once loaded, `env` can be used in the following way:
- **Print : `print(str(env))`**
- `train_model` indicates whether to run the environment in train (`True`) or test (`False`) mode.
- `config` is an optional dictionary of configuration flags specific to the environment. For more information on adding optional config flags to an environment, see [here](Making-a-new-Unity-Environment.md#implementing-yournameacademy). For generic environments, `config` can be ignored. `config` is a dictionary of strings to floats where the keys are the names of the `resetParameters` and the values are their corresponding float values.
- **Step : `env.step(action, memory=None, value = None)`**
- `value` is an optional input that be used to send a single float per agent to be displayed if and `AgentMonitor.cs` component is attached to the agent.
- `text_action` is an optional input that be used to send a single string per agent.
Note that if you have more than one external brain in the environment, you must provide dictionaries from brain names to arrays for `action`, `memory` and `value`. For example: If you have two external brains named `brain1` and `brain2` each with one agent taking two continuous actions, then you can have:
`hidden_units` correspond to how many units are in each fully connected layer of the neural network. For simple problems
where the correct action is a straightforward combination of the state inputs, this should be small. For problems where
the action is a very complex interaction between the state variables, this should be larger.
where the correct action is a straightforward combination of the observation inputs, this should be small. For problems where
the action is a very complex interaction between the observation variables, this should be larger.
Typical Range: `32` - `512`
#### Normalize
`normalize` corresponds to whether normalization is applied to the state inputs. This normalization is based on the running average and variance of the states.
`normalize` corresponds to whether normalization is applied to the vector observation inputs. This normalization is based on the running average and variance of the vector observation.
`num_layers` corresponds to how many hidden layers are present after the state input, or after the CNN encoding of the observation. For simple problems,
`num_layers` corresponds to how many hidden layers are present after the observation input, or after the CNN encoding of the visual observation. For simple problems,
fewer layers are likely to train faster and more efficiently. More layers may be necessary for more complex control problems.
We recommend using the following naming convention:
* Name the batch size input placeholder `batch_size`
* Name the input state placeholder `state`
* Name the input vector observation placeholder `state`
* Name the observations placeholders input placeholders `observation_i` where `i` is the index of the observation (starting at 0)
* Name the observations placeholders input placeholders `visual_observation_i` where `i` is the index of the observation (starting at 0)
The object you get by calling `step` or `reset` has fields `states`, `observations` and `memories` which must correspond to the placeholders of your graph. Similarly, the arguments `action` and `memory` you pass to `step` must correspond to the output nodes of your graph.
The object you get by calling `step` or `reset` has fields `vector_observations`, `visual_observations` and `memories` which must correspond to the placeholders of your graph. Similarly, the arguments `action` and `memory` you pass to `step` must correspond to the output nodes of your graph.
While training your Agent using the Python API, you can save your graph at any point of the training. Note that the argument `output_node_names` must be the name of the tensor your graph outputs (separated by a coma if multiple outputs). In this case, it will be either `action` or `action,recurrent_out` if you have recurrent outputs.
{kind=link}
{kind=link}
{kind=link}

{kind=link}